This meta-task is to serve as a pointer/blocker so we don't keep having to re-explain the same basic problems in many tickets.
Background
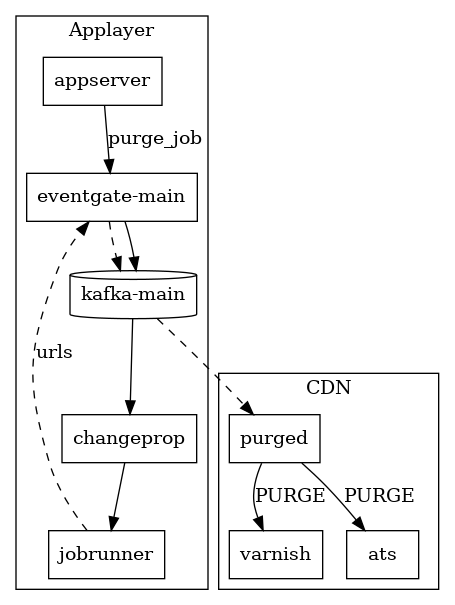
The CDN infrastructure is composed of two layers. Traffic flows from frontend-cache -> backend-cache -> MediaWiki application.
- "Frontend" cache. Their main purpose is to handle high load. Traffic is generally distributed equally among them. Implementation-wise this is currently backed by Varnish, stored in RAM, has the logical capacity equal to what one such server can hold in memory (given each frontend server is effectively the same).
- "Backend" cache. Their main purpose is to handle wide range of pages. Traffic is distributed by hashing the URL to one of the backends (any relevant request headers factor in as well).
When an article is edited, or when we cascade updates from templates and Wikidata items, we need to purge the relevant URLs from the CDN caches. We use HTCP (multicast UDP) to send the purges from MediaWiki to the cache nodes.
See https://wikitech.wikimedia.org/wiki/MediaWiki_at_WMF#Infrastructure for a more complete overview, including links to in-depth docs.
Root problems
- Network congestion. The use of HTCP (multicast UDP) generates a lot of internal traffic to our cache nodes.
- Packet loss. UDP is unreliable, especially at high rates multicasted across broad networks and contending with other beefy traffic to the cache boxes on network queues and such. Historically, this hasn't been a huge issue when internal traffic was much more stable. For quite a long time, user-notable missed purges were rare.
- Bad renewal of purged content, due to a cache-layer race condition. The multicast HTCP purges have no awareness of our distinct frontend and backend layers.
It is easy for a purge to reache a frontend first (instead of backends). Then upon the next visit to that article the frontend will fallback to the backend cache which may serve it its old copy. Thus it will have "whitewashed" the old version. Sometime later the backend recieves the purge, but the frontends have already moved on and this does not self-correct currently. Again, historically this wasn't a huge problem in practice; the race condition was never noticed much for articles that people paid most attention to.
This problem is non-trivial to solve because there can be a local backlog of purges. Even if we "simply" send the purge to all the backends first, and only then purge the frontends, this does not help per-se because the action isn't instantenous. Each server has its own inbox of purges it has received for processing. What matters is not the order in which they are sent to the cache layers, but the order in which they are processed.
- Many URLs to purge (content variants and derivatives). Often a single piece of unique content is reflected under several distinct URLs (think language conversion, image resizing, mobile vs desktop rendering, the History page of an article, etc). Historically, this was solved by either never caching or never purging the "less-important" views of article metadata.
Impact
Since late 2015, the above problems have gotten worse and more-noticeable:
- T124418 outlines how our rate of purge requests has multiplied by more than an order of magnitude in this recent timeframe. There are several distinct days on which the level raised higher (permanently), and we can only guess at the various causes:
- We know some of the causes were code changes that attempted to fix the variants problem (4) above by issuing purges for many more distinct URLs per unique content source than we have historically.
- We know some of the causes were code changes trying to fix problems (2) and (3) by sending multiple delayed repeats of every purge request a short time later to try to paper over races and loss, which further multiplies the total rate.
- We suspect that when most of the purging was centralized through the JobQueue somewhere in this timeframe, that this probably also multiplied the purge rate due to JobQueue bugs repeating past purges that were already completed for no good reason.
- Some wikis have actually added javascript at various places in the wikis themselves to execute automatic purge-on-view as a recourse as well, further exacerbating the problem in an incredibly frustrating way.
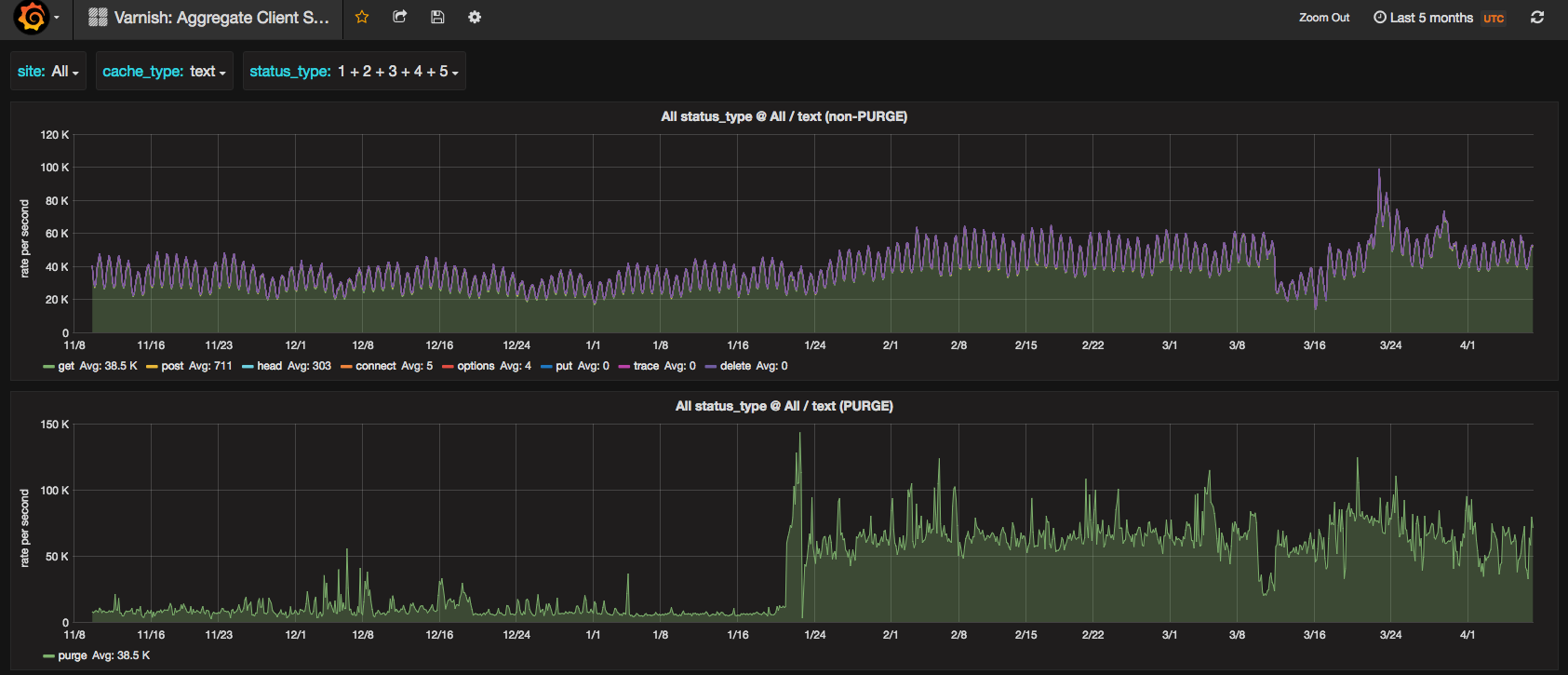
- Because of the massive increase in raw purge rate at the caches, we're almost certainly in worse shape than we were before. Various parties' attempts to 'fix' the problems have overwhelmed us with far more purge traffic than we've ever had before, which results in more loss to network queues and buffers at various layers. We now get far more frequent reports of failed purging than we did historically. This image gives a decent view of the purge traffic increase:
What we're doing
We've basically given up on trying to backtrack through whatever has gone wrong in the past several months, since T124418 investigation basically went nowhere. However, we already have longer-term solutions in the works to fix various aspects of the underlying issues anyways, which will hopefully obviate this whole mess:
- Enable XKey support in Varnish (Aug 2016). A key component is T122881 where (after upgrading to varnish4, which is still ongoing) we'll get the XKey vmod going to provide a realistic, scalable solution for problem (4) with content variants.
- Deploy EventBus/Kafka support to MediaWiki (2015-2016). Another key component is the EventBus work (T116786), where we hope to centralize purge requests and fan them out to the caches more-reliably without using multicast. We'll probably solve the layer races within EventBus as well by having different subscription topics for different layers and staggering through them, but that's a relatively-minor detail for this ticket.
- Shorten CDN expiry to reduce need for purging (2016). We're also looking in T124954 at reducing our maximum cache TTLs pretty dramatically, which makes any minor purge loss a much smaller fallout than it is with today's long TTLs, but that's stalled out a bit while working on the varnish4 -> xkey backlog for the first point.
- Introduce MediaWiki rebound purging (2015). To reduce chances of problem (3) happening with race conditions, we added a stop-gap that effectively rolls the dice twice. The purge is repeated once, 20 seconds later, via the job queue. Configured in MediaWiki via $wgCdnReboundPurgeDelay.
- Introduce chained purging in vhtcpd (2017). Within a single server (which hosts both a frontend instance and a backend instance) chain the purge processing so that backend is applied before frontend. This reduces chances of problem (3) happening, but does not rule it out because there is no coordination between backends. See also https://gerrit.wikimedia.org/r/382868/ (91cda076 https://wikitech.wikimedia.org/wiki/Multicast_HTCP_purging.
Future thoughts
The amount of remaining work to get from where we are today to a better solution is non-trivial. It will probably be months before we've significantly reduced or eliminated purging problems, not weeks or days. In the meantime, we don't have a whole lot of awesome ways to cope with this.
If easy administrative tools to simply re-issue purges (e.g. ?action=purge) do not paper over the problem, our only other recourse is having operators execute manual varnish cache bans. These do not scale on a human level (and in fact, detract from ongoing work including all the above), and they also do not scale well enough at a technical level that we want to automate this and make it any easier to execute them faster.
Currently, the majority of the real pragmatic problems this is causing are on upload.wikimedia.org links for Commons deletions, as seen in e.g. T119038, T109331, T133819, and probably several other duplicates of the same basic thing. A lot of the urgency from requestors on these is driven by a rise in Commons abuse from mobile networks to upload copyvio material (especially through labs-based proxy tools), which Commons admins are having to deal with an alarming rate of. At the rate at which they're deleting copyvio content, and the degree to which they care this content isn't visible from our servers anymore, they're falling into a bucket where they are affected by the general purging issues to a much greater and more-noticeable degree than most.
While that's totally our fault (the missed purges), it should be possible to fix individual cases with ?action=purge sorts of solutions. If it's not, then we have a content-variants problem or some other code problem in the midst of all of this as well.
A lot confusion happens in every ticket about this. Browser caching confuses reporters into thinking the item is still cached by us when it's not. Sometimes they're confused by our multiple geographic endpoints (esams, ulsfo, eqiad, codfw). Even within each datacenter, there are multiple frontend caches to which different users will map, getting inconsistent results when there's an issue. I don't have any good answers for this at the moment.
Regardless, caching isn't the only problem in these cases. The underlying problem of massive copyvio uploads on commons should be addressed on its own in some realistic and relatively-future-proof way that's less burdensome to administrators and operators everywhere, IMHO.