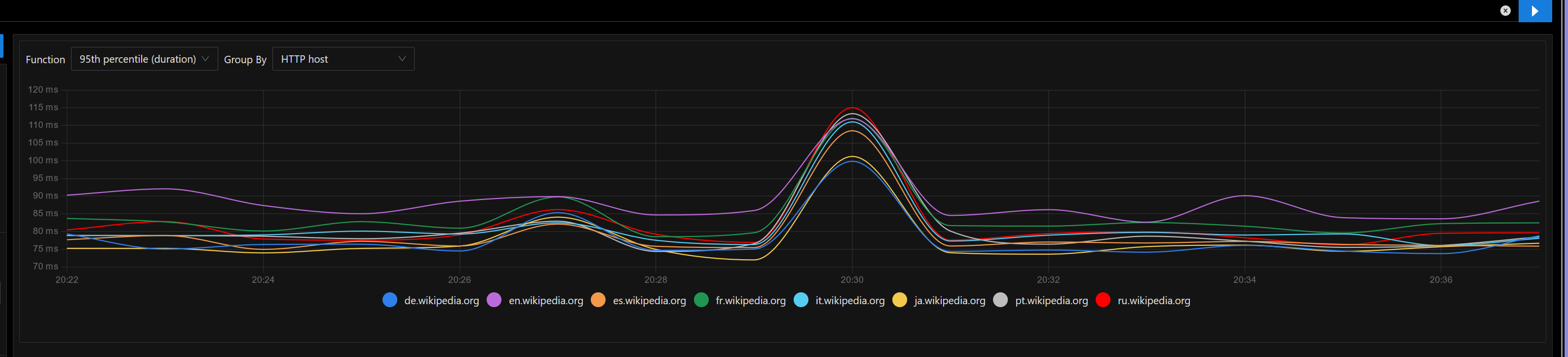
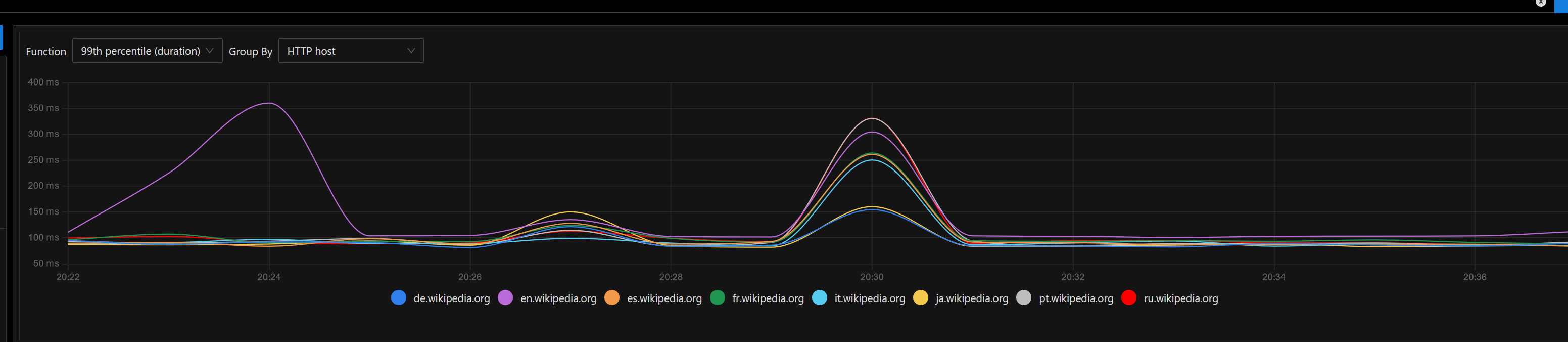
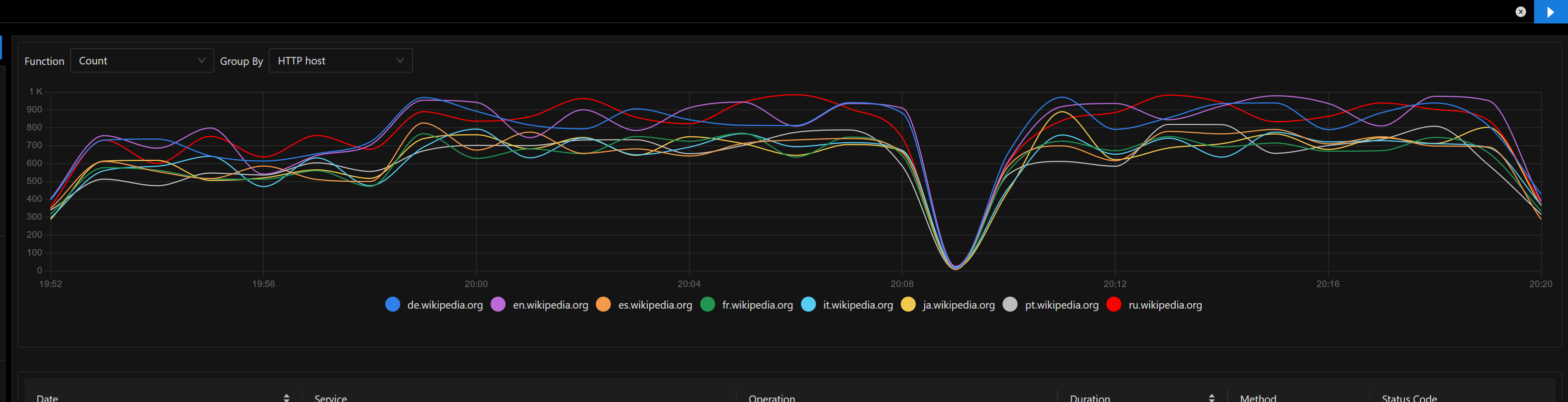
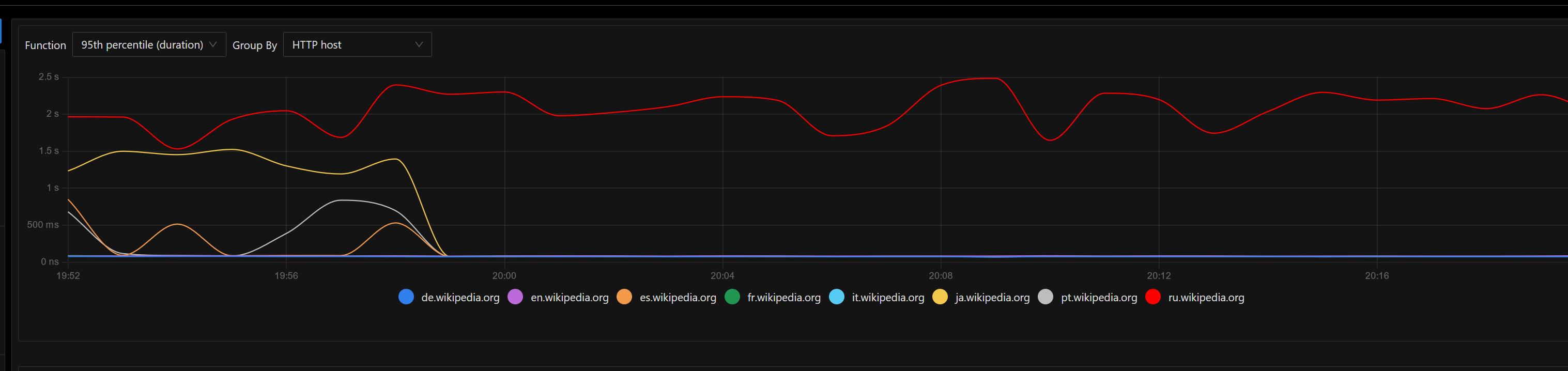
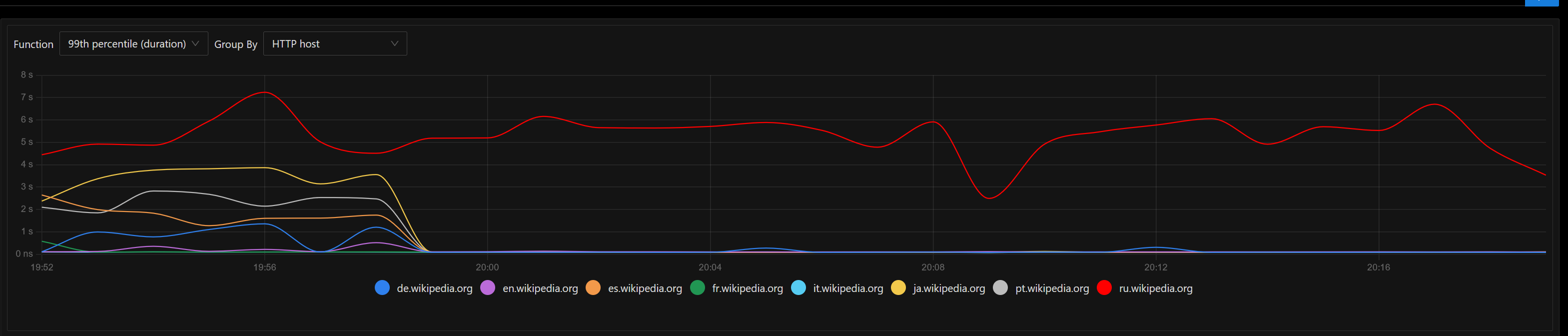
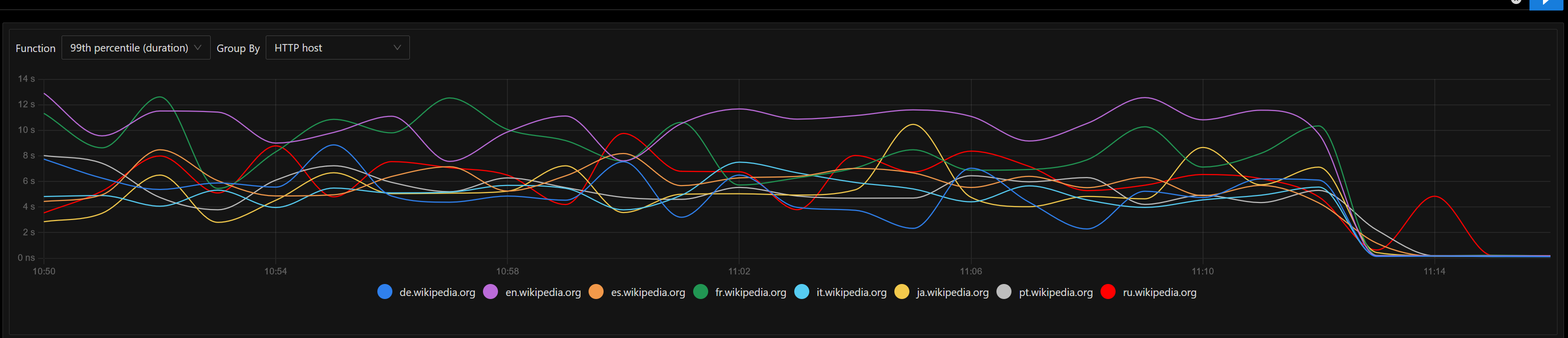
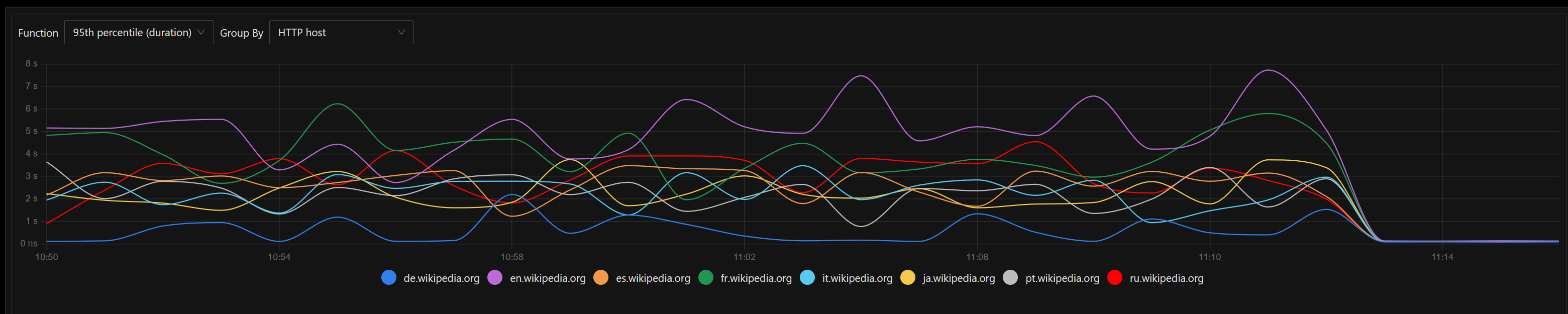
Currently summary endpoint is implemented inside mobileapps service and it internally reuses the MCS codebase (without outgoing requests to the MCS endpoints).
With RESTBase going away its worth investigating moving the summary endpoint outside of mobileapps.
Reasons:
- It doesn't fall into mobileapps scope
- Its heavily used by web clients not only apps (probably the main consumers)
- It makes outgoing requests to both action API and Parsoid which made sense in an architecture where because of RESTBase services were designed to work closely interconnected but maybe its a performance overhead
Regarding outgoing requests, summary endpoint has the following:
- Queries action API for flagged revisions
- Queries Parsoid for page html
- Queries action API for summary metadata
- Queries action API for siteinfo