The apps teams would like to migrate https://ml-article-descriptions.toolforge.org/ off of toolforge into a more production setting and its been suggested that Liftwing should be the destination.
What use case is the model going to support/resolve?
Android app users currently have an entry point for adding Wikidata descriptions to Wikipedia articles that are missing them. This model provides recommended descriptions to add to simplify the process and help codify norms around what these descriptions should look like. More background: https://www.mediawiki.org/wiki/Wikimedia_Apps/Team/Android/Machine_Assisted_Article_Descriptions
Do you have a model card? If you don't know what it is, please check https://meta.wikimedia.org/wiki/Machine_learning_models.
Yes: https://meta.wikimedia.org/wiki/Machine_learning_models/Proposed/Article_descriptions
What team created/trained/etc.. the model? What tools and frameworks have you used?
A group of external researchers and often-collaborators from EPFL trained the model. More details in the paper (arxiv). Essentially they're using a modified transformers library to merge an mBART model that takes article paragraphs as input and an mBERT model that takes existing article descriptions from other languages as input (paper overview). NOTE: there are some details in the paper such as the Wikidata knowledge graph embeddings that were not used in the deployed model.
Here's their raw code: https://github.com/epfl-dlab/transformers-modified (and a more general repo that also includes code for training)
And the API code that uses the model and has a copy of the modified transformers library: https://github.com/geohci/transformers-modified/blob/main/artdescapi/wsgi_template.py
The raw PyTorch model binary and supporting config etc. can be found here: https://drive.google.com/file/d/1bhn5O2WW6uXo4UvKDFoHqQnc0ozCCXmi/view?usp=sharing
What kind of data was the model trained with, and what kind of data the model is going to need in production (for example, calls to internal/external services, special datasources for features, etc..) ?
- Input: Wikipedia article
- Features: first paragraph of that article (if it exists -- not strictly necessary), first paragraph of the article in any of the 24 other languages supported by the model, existing article descriptions in any of the other 24 languages.
- Output: k suggested article descriptions where k is an adjustable parameter but we've found that generating the top 3 and recommending the top 2 from that seems to best balance utility, quality, and diversity.
If you have a minimal codebase that you used to run the first tests with the model, could you please share it?
- Working API (with model binary files): https://github.com/geohci/transformers-modified/tree/main
State what team will own the model and please share some main point of contacts (see more info in Ownership of a model).
Joseph Seddon
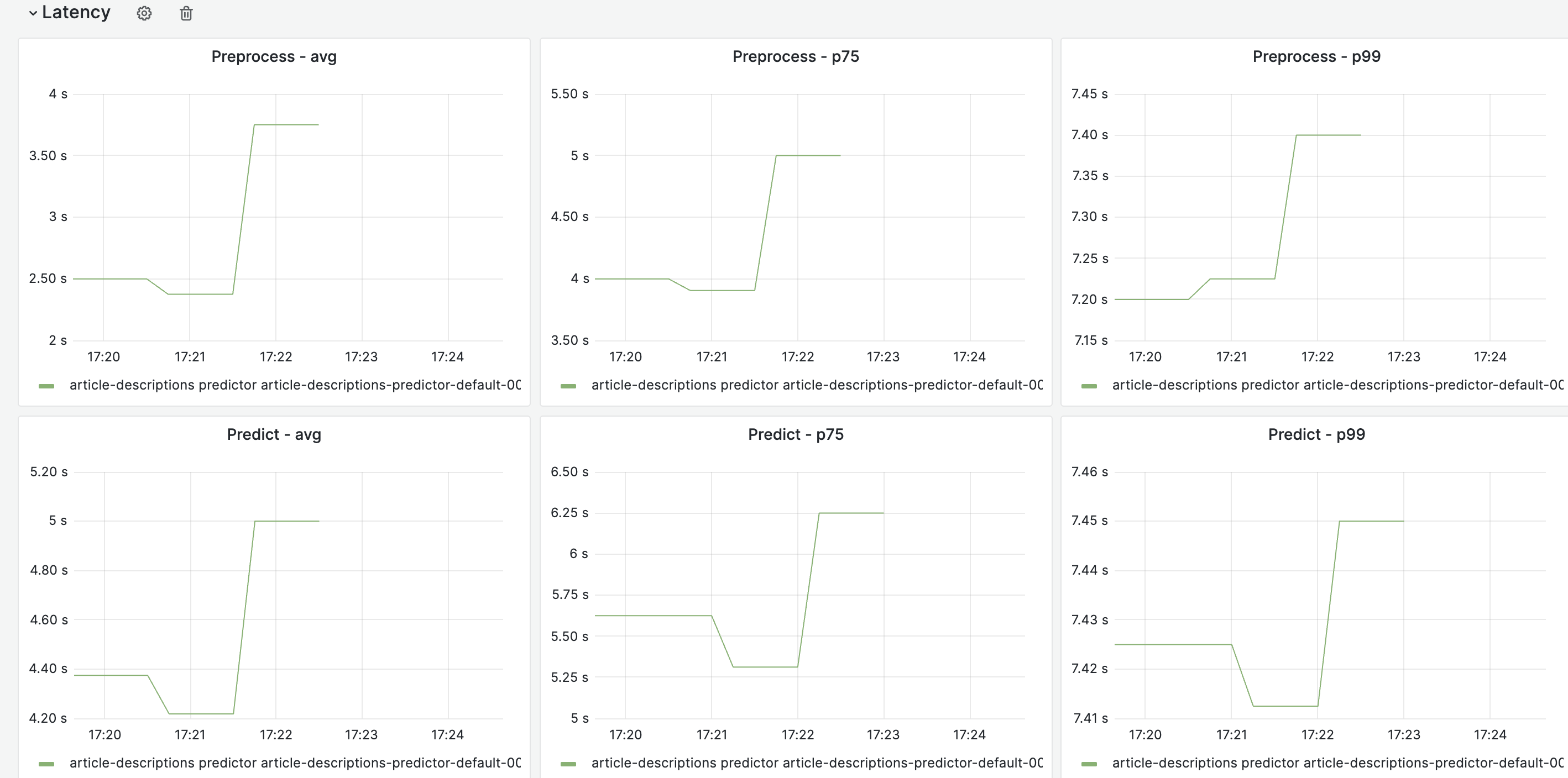
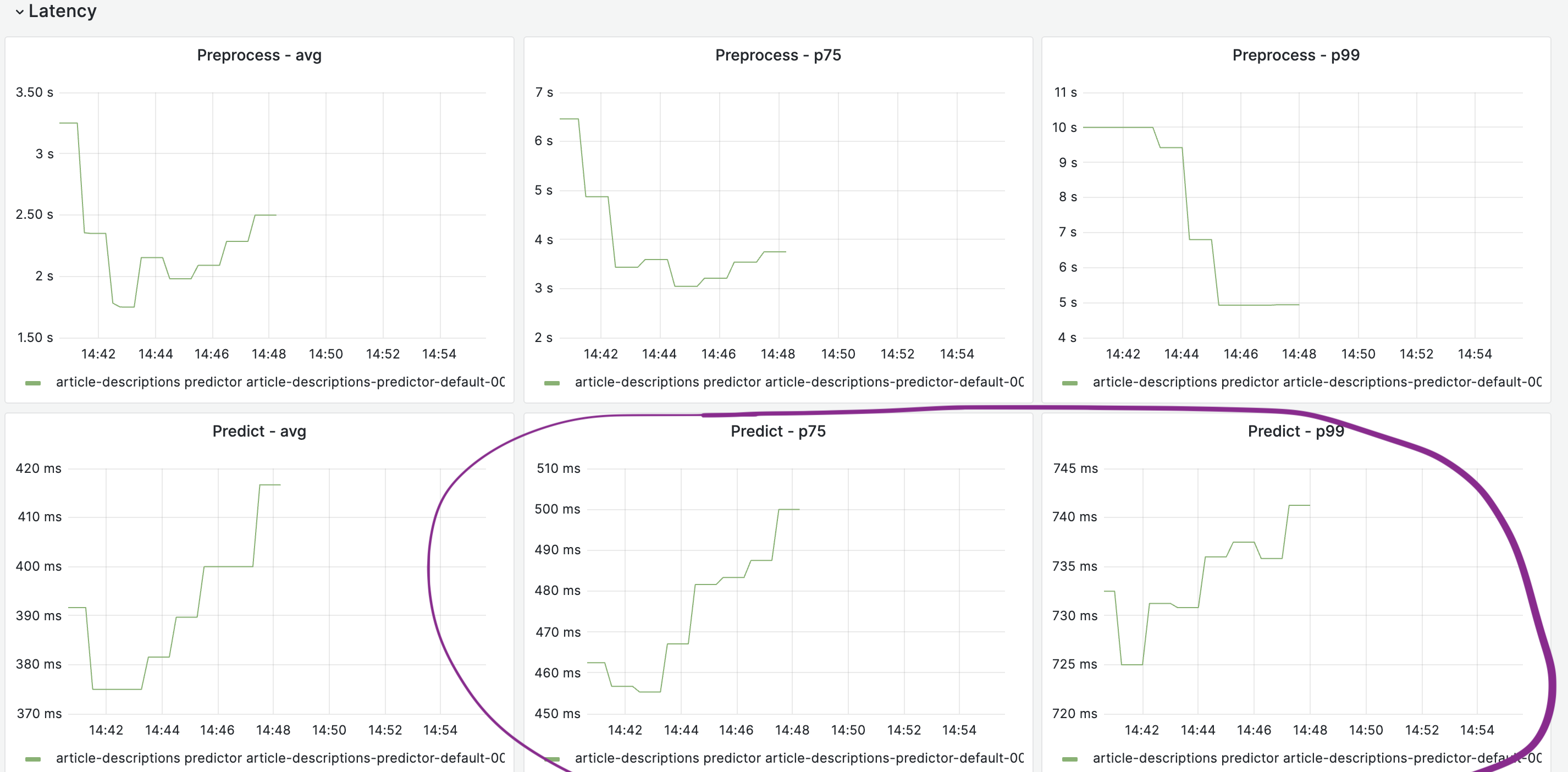
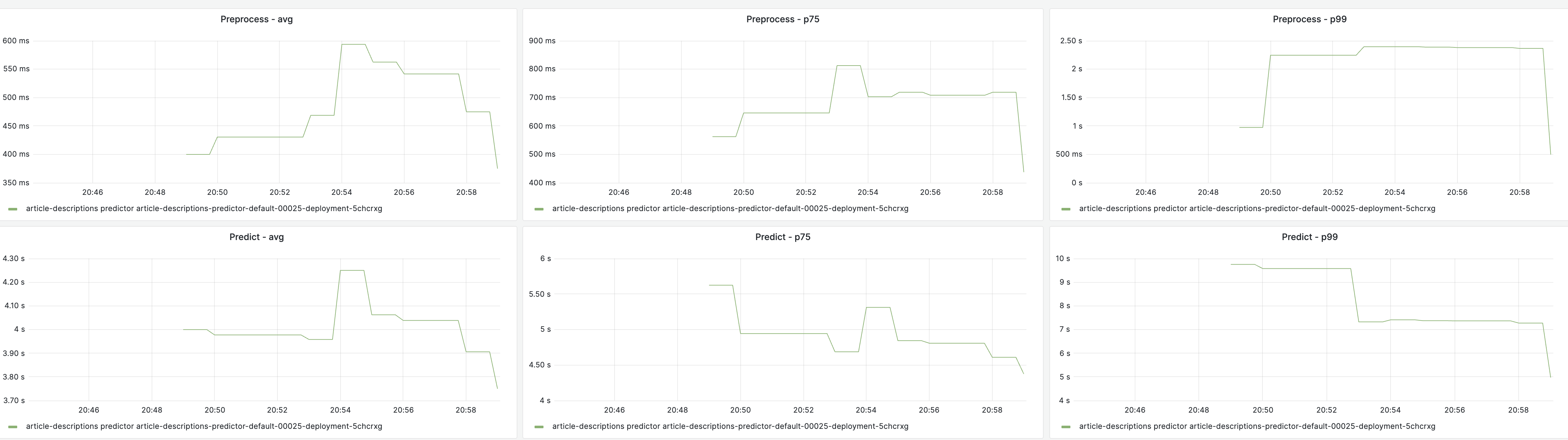
What is the current latency and throughput of the model, if you have tested it? We don't need anything precise at this stage, just some ballparks numbers to figure out how the model performs with the expected inputs. For example, does the model take ms/seconds/etc.. to respond to queries? How does it react when 1/10/20/etc.. requests in parallel are made? If you don't have these numbers don't worry, open the task and we'll figure something out while we discuss about next steps!
Generally looking at 3-4 seconds depending on the input. You can test it out with various inputs at this UI for the Cloud VPS endpoint and see some stats on latency from this notebook. It's highly dependent on how much content exists -- e.g., articles with many language editions + existing article descriptions are a good bit slower (upwards of 10+ seconds) than articles that only exist in a single language (1-2 seconds). There is some allowance for latency of a second or two in the UI but obviously any speed-ups would be nice and there might be ways to downsample the languages considered for highly multilingual topics to reduce some of the worse-case latencies. A GPU would obviously speed it up but it's possible that something like CTranslate2 could be applied or even just that LiftWing has better hardware for this use-case than Cloud Services and it won't be an issue. These more multilingual articles often already have article descriptions too so are less likely to need the tool.
Is there an expected frequency in which the model will have to be retrained with new data? What are the resources required to train the model and what was the dataset size?
At this point, there hasn't been discussion around re-training. Fine-tuning is certainly possible but I think not too urgent given that there's a pretty large dataset of existing Wikidata descriptions that the model was trained on and I don't foresee a massive amount of data drift. This repo has some details on training.
Have you checked if the output of your model is safe from a human rights point of view? Is there any risk of it being offensive for somebody? Even if you have any slight worry or corner case, please tell us!
A few analyses:
- Initial potential harm exploration that led us to institute guardrails around which editors will have access to recommendations for biographies of living people.
- The tool was piloted for several weeks in early 2023 and the edits made with the tool were evaluated by a number of volunteers across different languages (slide deck).
Anything thing else that is relevant in your opinion :)
- If I foresee a potential engineering challenge, it's that the model inference code currently depends on a modified, static snapshot of the transformers repo. Long-term, that might not be desirable as it would be hard to keep it up-to-date with improvements made to the broader transformers library. I'm not sure how feasible it is, but it might be worth considering whether it's possible to convert it from a modified snapshot of the transformers library to something more like a wrapper around it.
- There is an additional issue that was discovered during this testing which is that occasionally the model will "hallucinate" dates of births for people. This stems from a difficulty with these language models in handling numbers (they tend to tokenize them as single digits and so have trouble reasoning across things like dates) as well as the source of training data (TextExtracts), which removes dates from the article lead and thus likely make it more difficult for the model to learn how to handle them. I'm open to a discussion on how to handle this but after chatting with the EPFL researchers about it, I personally think it'd be easy and reasonable to generate a simple filter that removes any recommendations that contain a date that is not seen in the input paragraph / description data.