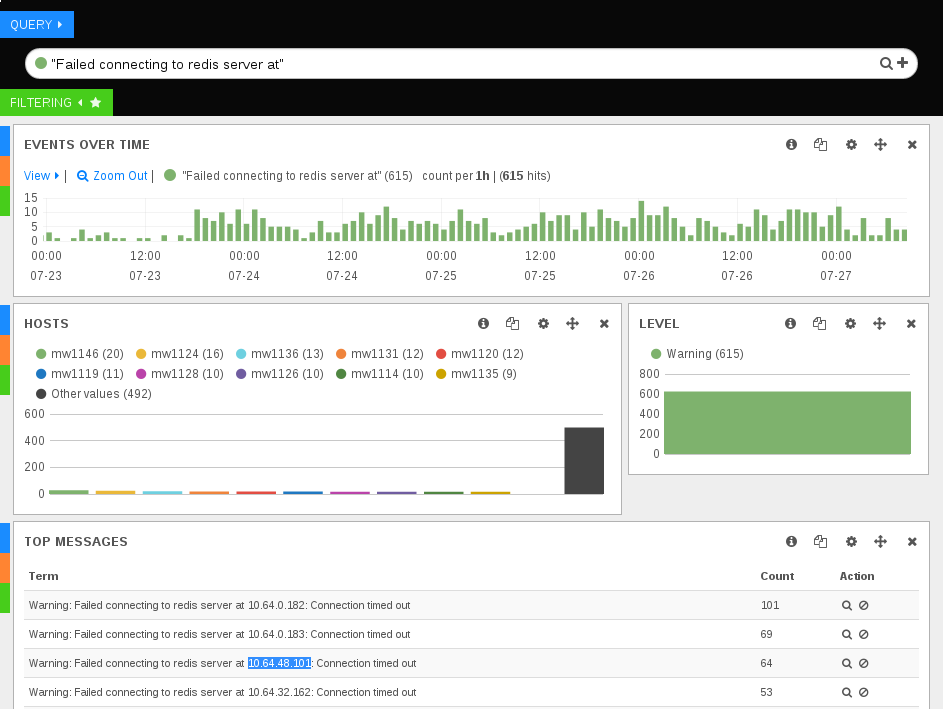
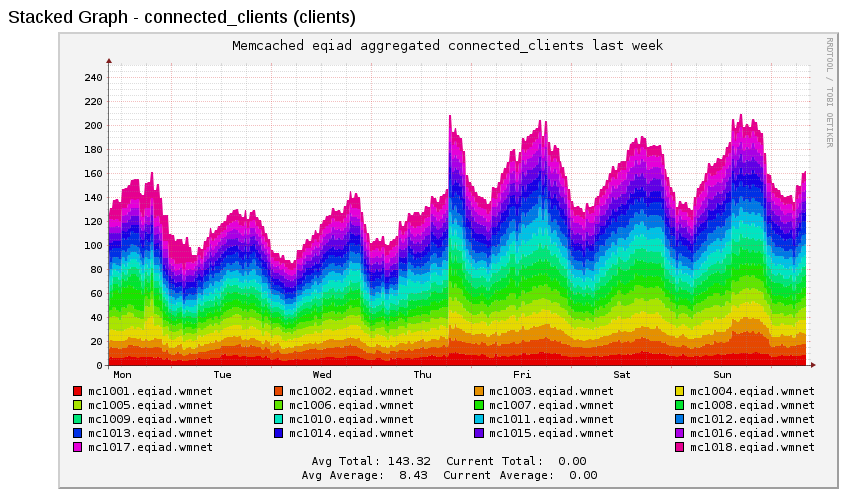
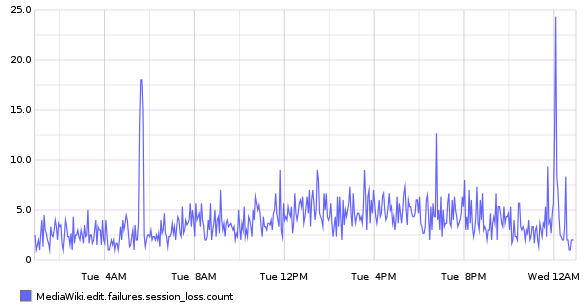
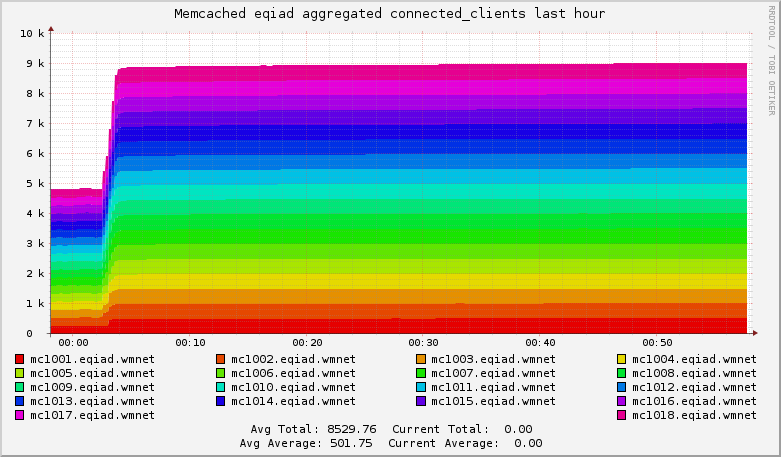
The number of connection timeouts to the session redis servers (which are on the mc* boxes) is worryingly high, lately.
hoo@fluorine:/a/mw-log$ zgrep -c 'Failed connecting to redis server' archive/hhvm.log-201507* archive/hhvm.log-20150701.gz:0 archive/hhvm.log-20150702.gz:0 archive/hhvm.log-20150703.gz:2 archive/hhvm.log-20150704.gz:1 archive/hhvm.log-20150705.gz:0 archive/hhvm.log-20150706.gz:0 archive/hhvm.log-20150707.gz:2 archive/hhvm.log-20150708.gz:0 archive/hhvm.log-20150709.gz:1 archive/hhvm.log-20150710.gz:1 archive/hhvm.log-20150711.gz:1 archive/hhvm.log-20150712.gz:1 archive/hhvm.log-20150713.gz:0 archive/hhvm.log-20150714.gz:0 archive/hhvm.log-20150715.gz:0 archive/hhvm.log-20150716.gz:0 archive/hhvm.log-20150717.gz:0 archive/hhvm.log-20150718.gz:1 archive/hhvm.log-20150719.gz:0 archive/hhvm.log-20150720.gz:6 archive/hhvm.log-20150721.gz:5 archive/hhvm.log-20150722.gz:9 archive/hhvm.log-20150723.gz:117 archive/hhvm.log-20150724.gz:514 archive/hhvm.log-20150725.gz:597 archive/hhvm.log-20150726.gz:670
This might be related to T102199.