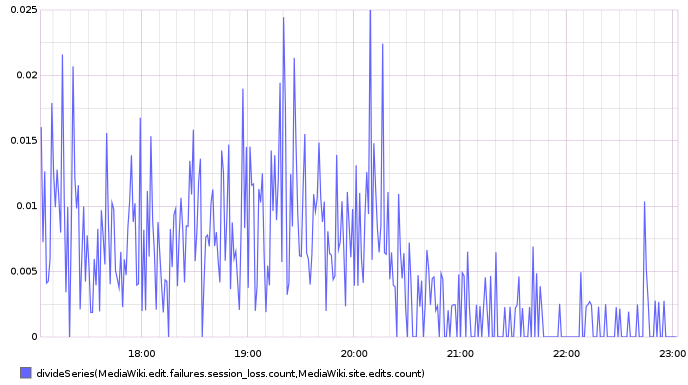
Recently (i.e. since a few weeks), it happens way more frequently than usual that I have to save an edit twice to get it through, because the error
"session_fail_preview": "<strong>Sorry! We could not process your edit due to a loss of session data.</strong>\nPlease try again.\nIf it still does not work, try [[Special:UserLogout|logging out]] and logging back in.",
became way more frequent. I didn't change my editing patterns, for instance I'm not waiting between action=edit load and submit time more than I used to be, so the issue is server side.
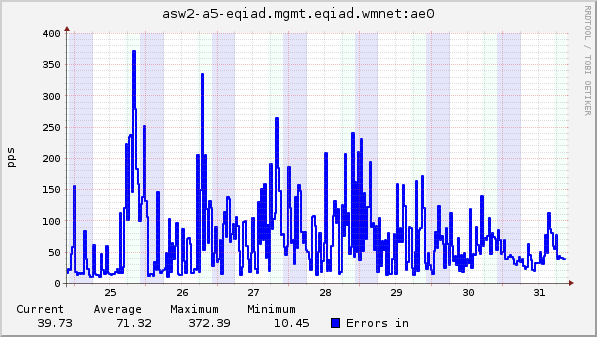
I saw multiple reports of this feeling around, on IRC and at least two wikis. There were many changes related to caching recently, so that's the most obvious suspect.
Aside from the annoyance and productivity loss, the most obvious damage is that an unknown amount of edits go lost forever (when editors do not notice the edit was not saved).
Per @Whatamidoing-WMF's note to the operations list:
There's been a significant uptick in the number of complaints about people losing session data during the last few days. Some editors report that it's happening for a majority of sessions. The discussion at en.wp is here: https://en.wikipedia.org/wiki/Wikipedia:Village_pump_(technical)#.22Loss_of_session_data.22_error_on_Save_page