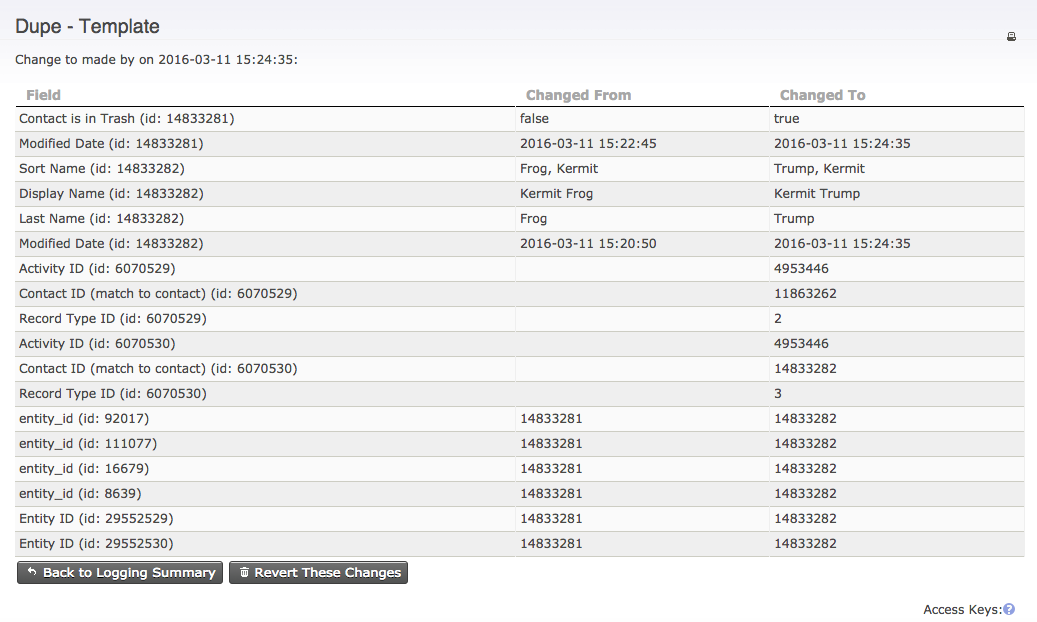
We need to be able to undo dedupe merges, before we start merging large batches of contacts.
This means,
- Keep an audit log of merges.
- Keep records of which entities were associated with the deleted contact.
- Provide a GUI for undoing a merge.
Description of CiviCRM audit log functionality
CiviCRM keeps a separate log table for each table in the database (except cache tables). By default the audit log engine is an archive table. Archives are optimised for writing but have poor read performance. The audit log tables hold a copy of every insert, update or delete action along with the initial status when the logging is turned on. In addition to the fields in the parent table the log tables hold the contact id of the person who made the change, the timestamp and the connection id. Changes across several tables can have the same connection id.
The log tables are kept up to date by triggers.
CiviCRM provides a tab in the interface to view the change log for a given contact along with a button to reverse any changes.
Configuration options
CiviCRM supports the log tables being in a different database.
Although CiviCRM uses the Archive engine I have in the past converted specific tables to INNODB and added specific indexes to them. In general this would be tables like log_civicrm_contact, log_civicrm_address etc but we probably would not alter tables like log_civicrm_option_value which would only ever be interrogated by mysql. Indexes would go on the contact_id fields, and connection_id.
Performance
Without converting some tables to INNODB and adding indexes we won't get acceptable performance through the UI for viewing changes. The write speed is in theory faster for ARCHIVE than INNODB but I have not previous found a noticeable performance issue with write. We should try to do some performance benchmarking.
Disk space
If we want to be able to have reversibility then storing a large amount of extra data is going to be necessary. Other sites I have dealt with don't cull this data but it's something we might need to consider. Planning for that is a little tricky since we probably need to keep the most recent copy of each record - rather than simply deleting before a certain date.
The size of our data will be less if we put less indexes on - but if we want to intermittently cull data we need to think about indexes to facilitate any delete queries.
Risks
On other sites I have occassionally seen archive table corruption. This usually happens on particular high use tables - like the group_contact table. I have a suspicion that the that dedupe speed improvement we did may also fix this. I think converting important tables to INNODB will address this.
Note that Fuzion uses this audit logging on every site we deal with - only the scale issue is different. On larger sites we do experience speed rendering the change log. Doing the conversions I mentioned help but I believe there is also a query that needs review in there.
Steps
- We need to test turning on logging on Staging to see how it performs.
- I need to provide a mysql file to Jeff to create the triggers & log tables
- Jeff to run sql, determining how much extra disc is used
- general click around by me
- Identify and Address specific points of slowness in click-around (I can probably do a first hit of these on another test DB at around 500k contacts)
- Review & address acceptability of the reversal interface
- I'm pretty sure the interface for deletes is unacceptable.
- Look at benchmarking our import jobs and comparing
- A minor task identified by Adam previously is to add an activity to a contact on delete identifying the deleted contact as a merge-delete
The highest risk of this derailing is that it is just too unwieldly - which should reveal itself on staging