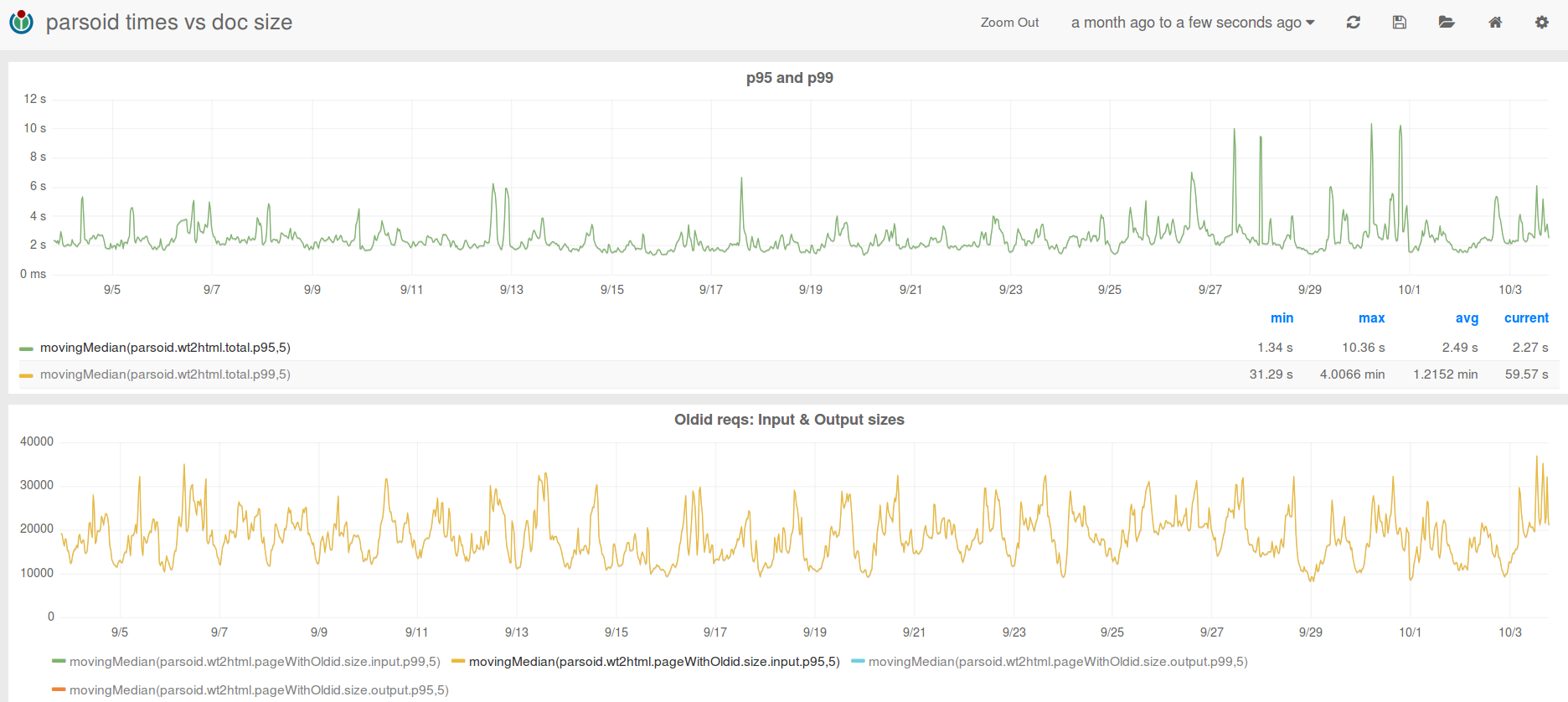
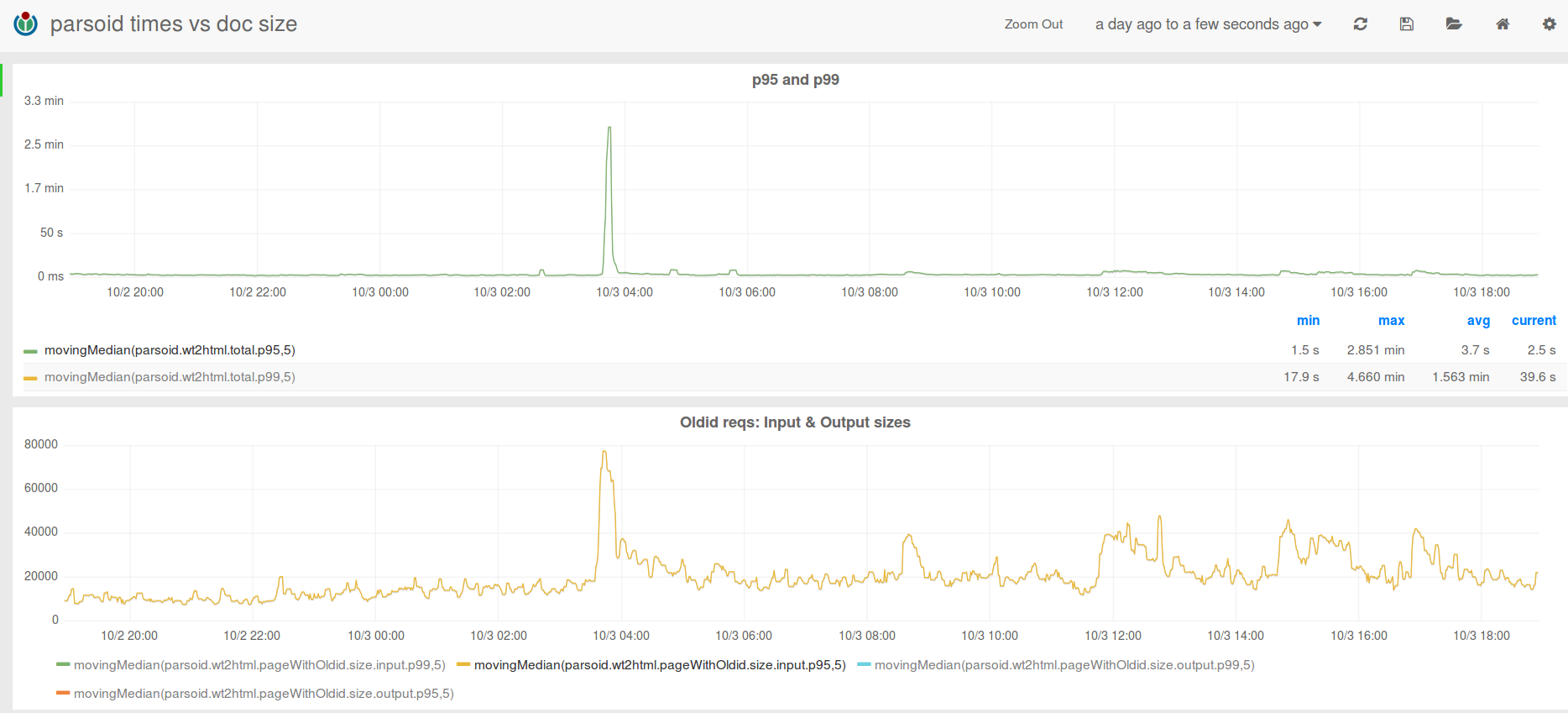
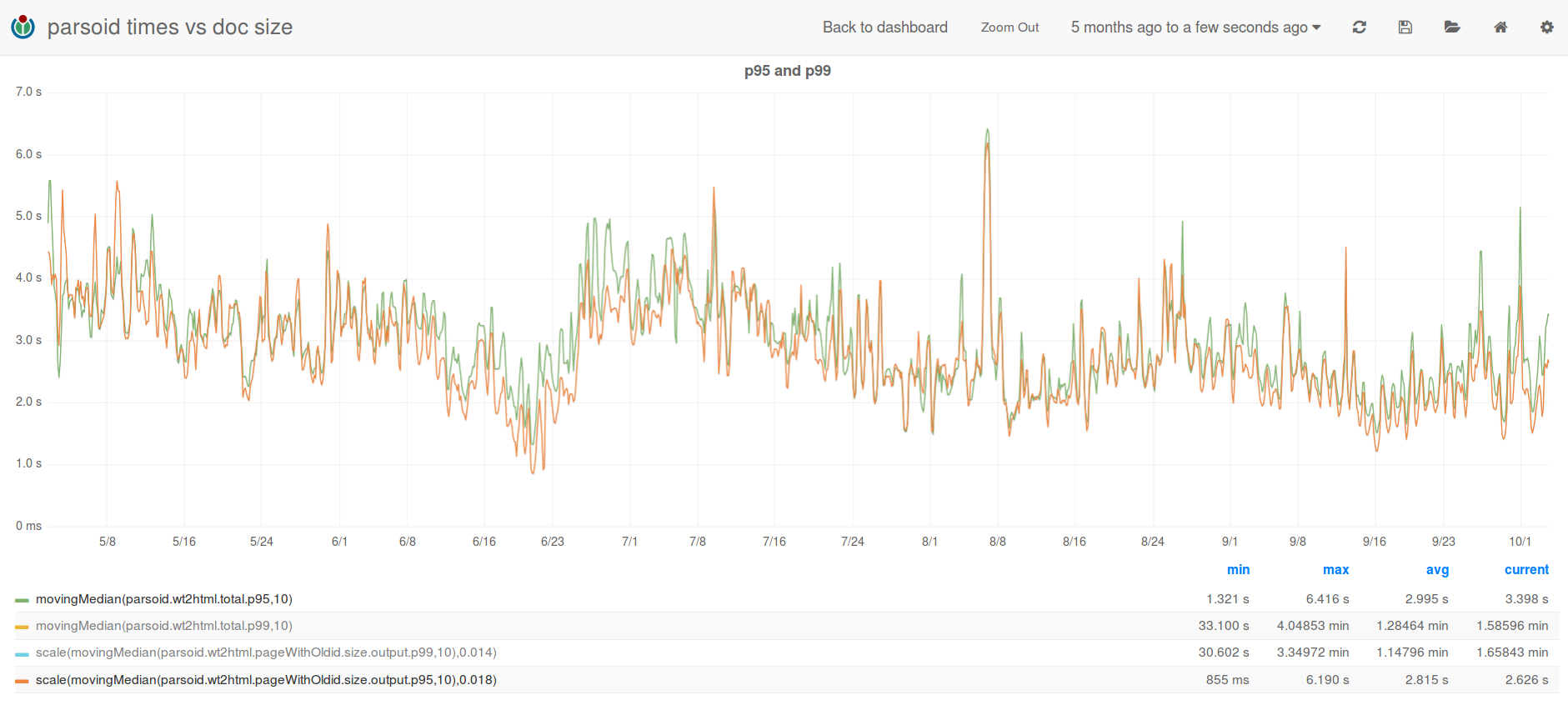
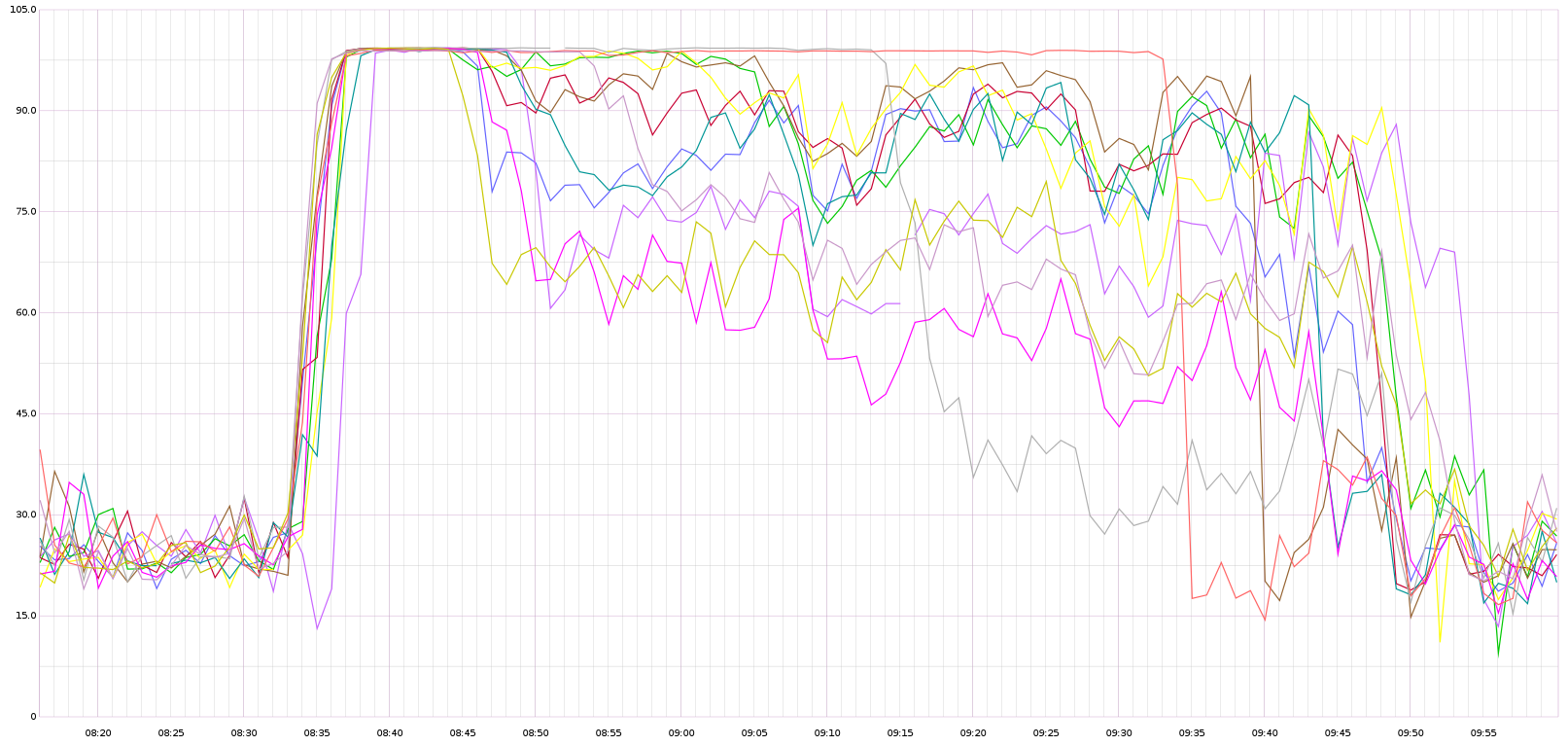
This morning I found all the parsoid servers under a sudden, very high CPU load. Restarting one of them did the trick of retaking it to a normal state, so I got some time to investigate
I found that, unsurprisingly, all the processes were stuck in some part of tokenizer.utils; but I got no clear indication of where in the code they were all stuck. Here is an example:
nodejs debug 127.0.0.1:5858
connecting... ok
debug> pause
break in /srv/deployment/parsoid/deploy/src/lib/mediawiki.tokenizer.utils.js:210
208 ) && input.substr(pos, 5) === '{{!}}';
209 case '}':
210 return counters.template && input[pos + 1] === "}";
211 case ':':
212 return counters.colon &&
debug> bt
#0 mediawiki.tokenizer.utils.js:210:1
#1 undefined:19803:21
#2 PegTokenizer._processText mediawiki.tokenizer.peg.js:313:30
#3 PegTokenizer.process mediawiki.tokenizer.peg.js:226:7
#4 ParserPipeline.process mediawiki.parser.js:482:21
#5 ParserPipeline.process mediawiki.parser.js:482:21
#6 Util.processContentInPipeline mediawiki.Util.js:1158:12
#7 ext.Cite.js:55:8
#8 Ref.handleRef ext.Cite.js:121:2
#9 b native v8natives.js:1607:30watching the master process, it was endlessly receiving timeout messages from the worker.
Since it's the weekend and we're having customer impact, I did restart the parsoids in the end.