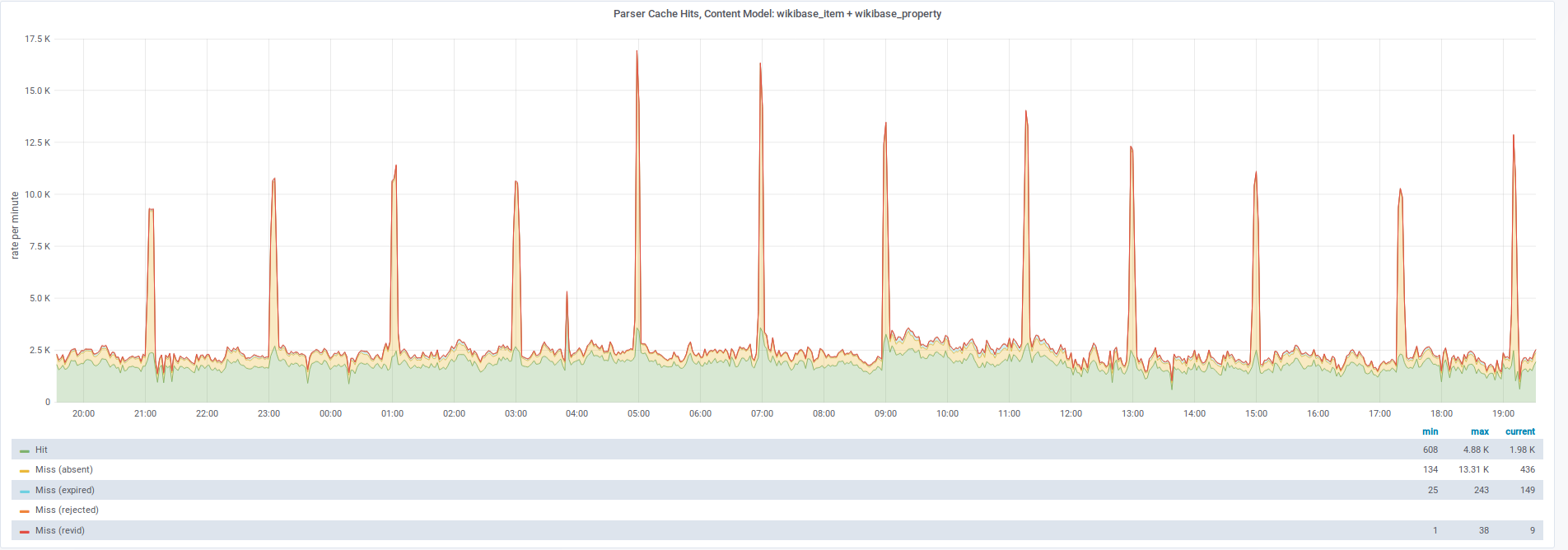
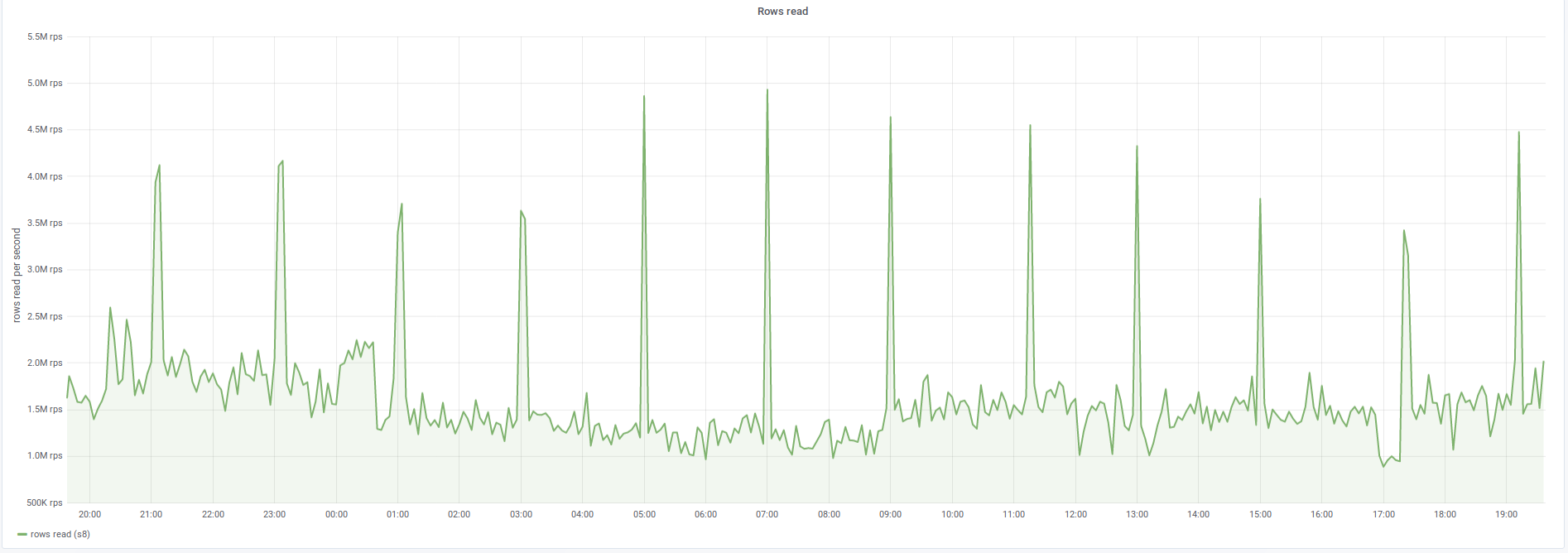
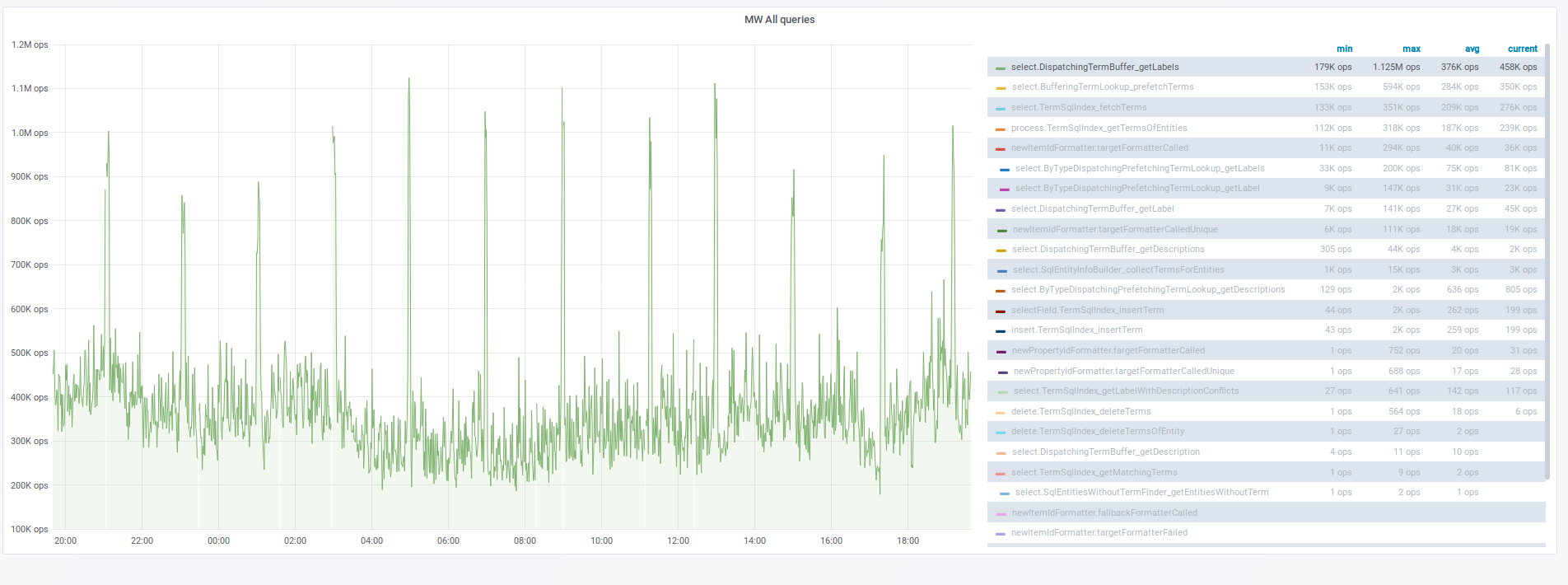
From: T143862
For starters, snapshot1006.eqiad.wmnet is accessing a non-dump host; this is a bug, but I do not think is the problem here.
The idea is that if the current dump db host is not enough to dump values, we can set up more (I said many times that you should ask for resources and I happy to providing them, in fact, dump hosts are scheduled for renewal with some of the most expensive servers we have bought), but nothing that is an interactive query should go to the regular servers and it risks being blocked at any time by the firewall configuration/grant system because they are not supposed to have connections. I do not have any issue reserving new servers for dumps, or even several of them if it was necessary, but it has to be documented and configured on mediawiki.
Also, as a secondary thing, regarding resources, I was asked if new dump servers could be on codfw, as eqiad is more costly in rack space.
So please 1) identify those cases 2) ask for more resources if needed 3) do not hide such configuration.