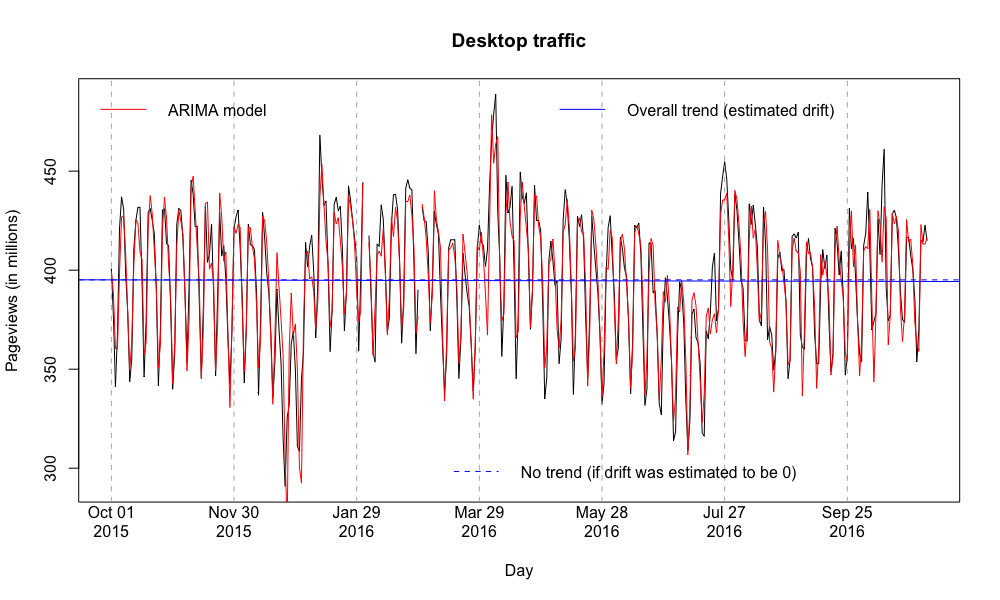
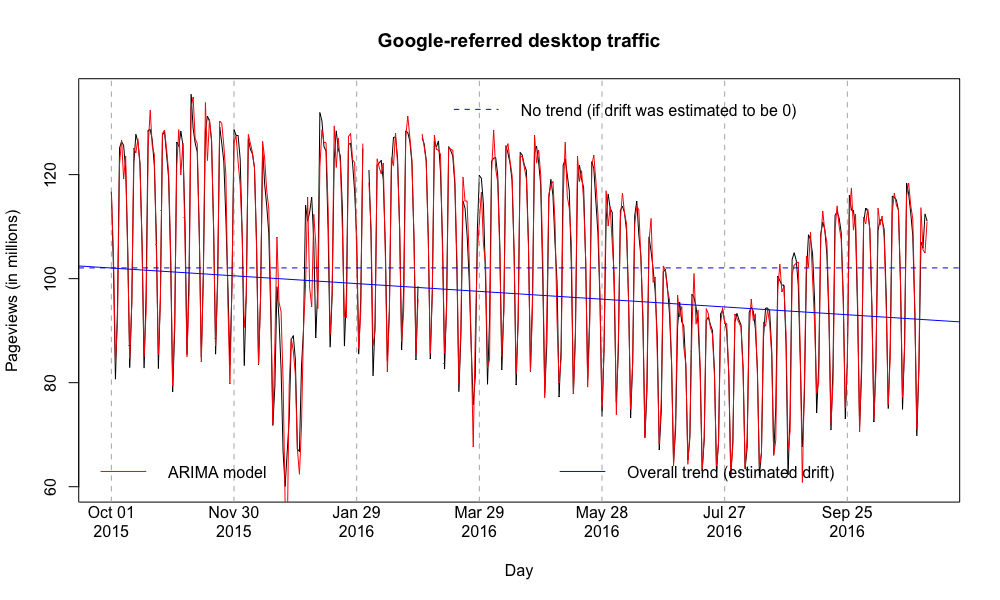
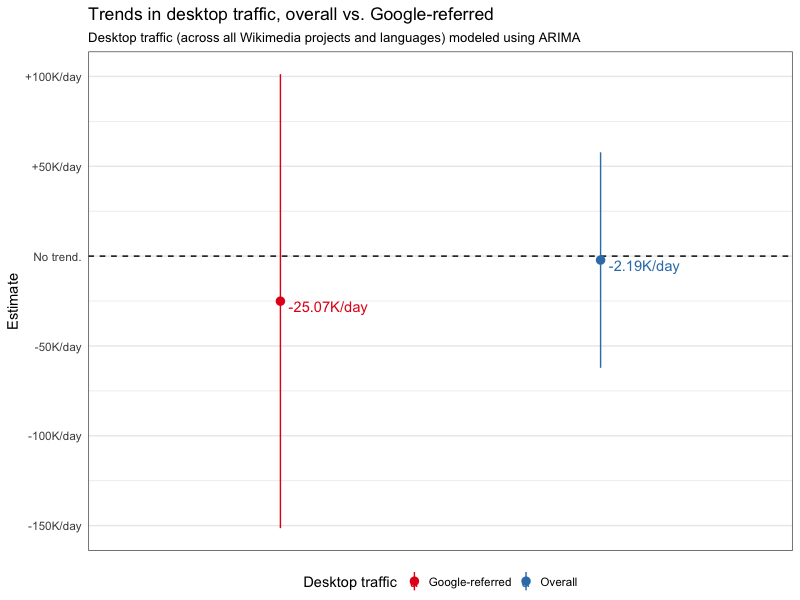
This was a question posed by @DarTar at today's (October) Monthly Metrics Meeting during the Q&A:
I was curious about the rate at which search engine traffic is declining, not just the absolute numbers. In other words: is Google referred traffic declining at the same rate as the overall decline of desktop traffic? Or faster? Past longitudinal data suggested it was dropping faster.