Description
Related Objects
- Mentioned In
- T214721: Create #pageviews-anomaly tag
T175870: Correct pageview_hourly and derived data for T141506
T153699: Skewed pageviews for Azerbaijani and Bulgarian Wikipedias, September, October and November 2016
T149355: Google-referred desktop traffic decline vs overall desktop traffic decline
T141786: TLS stats regression related to Chrome/41 on Windows
T144715: Top Pageview stats for August 27th doesn't look right
T144681: Traffic stats not generating reliably
T144635: Pageview Spike in Tagalog Wikipedia mid-June 2016
T143599: Correlate page views and interlanguage links clicks for all languages
T143064: Wikipedia.org Portal Dashboard: update pageview counting
T143045: Wikipedia.org Portal Dashboard: investigate increase in pageviews
T142505: [REQUEST] Language team's baseline metrics - correct CLL pageview data
T142408: Better publishing of Annotations about Data Issues
T93213: Improve access to local language wikis by fixing bug in generation of hreflang tags in <head> of article pages - Mentioned Here
- T175870: Correct pageview_hourly and derived data for T141506
T142505: [REQUEST] Language team's baseline metrics - correct CLL pageview data
T143064: Wikipedia.org Portal Dashboard: update pageview counting
T142408: Better publishing of Annotations about Data Issues
T141786: TLS stats regression related to Chrome/41 on Windows
rMW208983b6d1f5: OutputPage: Only set <link hreflang=x-default> on wiki/pages with variants
T136084: Unexpected increase in traffic for 4 languages in same region, on smaller projects
Event Timeline
FWIW, this is high priority for the Language team because these statistics significantly affect the info about pageviews in general, and I need pageview stats to be as precise as possible to make correct analyses of interlanguage links usage.
Thanks everyone for the analysis. This kind of bug is really hard to pin down. Because you're right, it's probably a bot. But finding some unique thing about this bot that doesn't apply to mobile traffic or other kinds of traffic is hard. This is an issue worth looking at, I'm just setting expectations that there may be no easy fix.
Ugh, interesting findings. Focusing on this desktop & "User" slice, let's look if the increase was concentrated in a certain geographical region, as it was in T136084#2357026. (Quickly adapting a query I've used before; not sure whether/when I will have time to contribute more thorough research here.)
It turns out that this is not the case - pageviews increased steeply across multiple countries (comparing July 13-16 with July 21-26):
| country | changepercentage | views_after |
|---|---|---|
| Iran | -13.05% | 9.309m/day |
| Germany | +4472.42% | 6.316m/day |
| India | +4265.44% | 5.897m/day |
| United States | +514.83% | 5.749m/day |
| France | +9263.15% | 4.79m/day |
| United Kingdom | +1049.37% | 2.989m/day |
| Italy | +7315.84% | 2.806m/day |
| Canada | +1841.57% | 2.627m/day |
| Japan | +5714.18% | 1.247m/day |
| Thailand | +9461.29% | 0.989m/day |
| Sweden | +2685.51% | 0.894m/day |
| Pakistan | -9.45% | 0.859m/day |
| Afghanistan | -11.98% | 0.592m/day |
| New Zealand | +3638.08% | 0.487m/day |
| Denmark | +3855.37% | 0.446m/day |
| Australia | +408.72% | 0.354m/day |
| Austria | +1704.56% | 0.161m/day |
| Russia | +520.59% | 0.156m/day |
18 rows selected (176.302 seconds)
Data via:
SELECT '|', -- include Phabricator table formatting country, '|', CONCAT(IF(changeratio-1>0,'+',''), ROUND(100*(changeratio-1),2), '%') AS changepercentage, '|', CONCAT(ROUND (milliondailyviewsafter, 3), 'm/day') AS views_after, '|' FROM (SELECT country, SUM(IF(day>20,view_count,NULL)) / SUM(IF(day<20,view_count,NULL)) AS changeratio, -- compare Jul 13-19 with Jul 21-26, excluding Jul 20 as apparent day of change SUM(IF(day > 20, view_count, null))/7000000 AS milliondailyviewsafter FROM wmf.pageview_hourly WHERE year = 2016 AND month = 7 AND day > 12 AND day < 27 AND project = 'en.wikipedia' AND page_title = 'Main_Page' AND agent_type = 'user' AND access_method = 'desktop' GROUP BY country) AS countrylist WHERE milliondailyviewsafter > 0.1 -- ignore countries with low traffic GROUP BY country, -- artificial grouping enforced by HQL: changeratio, milliondailyviewsafter ORDER BY views_after DESC LIMIT 10000;
Spot-checking France as the country with the second highest increase on this list, it indeed happened around July 20 there, matching the overall pattern:
SELECT year, month, day, CONCAT(year,"-",LPAD(month,2,"0"),"-",LPAD(day,2,"0")) AS date, SUM(view_count) AS views FROM wmf.pageview_hourly WHERE year = 2016 AND month = 7 AND project = 'en.wikipedia' AND page_title = 'Main_Page' AND agent_type = 'user' AND access_method = 'desktop' AND country = 'France' GROUP BY year, month, day ORDER BY year, month, day LIMIT 1000; year month day date views 2016 7 1 2016-07-01 39534 2016 7 2 2016-07-02 45448 2016 7 3 2016-07-03 49590 2016 7 4 2016-07-04 58748 2016 7 5 2016-07-05 44288 2016 7 6 2016-07-06 39705 2016 7 7 2016-07-07 41655 2016 7 8 2016-07-08 42681 2016 7 9 2016-07-09 40376 2016 7 10 2016-07-10 41610 2016 7 11 2016-07-11 44189 2016 7 12 2016-07-12 52575 2016 7 13 2016-07-13 43945 2016 7 14 2016-07-14 42197 2016 7 15 2016-07-15 29963 2016 7 16 2016-07-16 33642 2016 7 17 2016-07-17 33355 2016 7 18 2016-07-18 37791 2016 7 19 2016-07-19 137228 2016 7 20 2016-07-20 1932960 2016 7 21 2016-07-21 4491894 2016 7 22 2016-07-22 5899980 2016 7 23 2016-07-23 5156882 2016 7 24 2016-07-24 5596893 2016 7 25 2016-07-25 6161804 2016 7 26 2016-07-26 6223943 2016 7 27 2016-07-27 5902629 2016 7 28 2016-07-28 6074585 2016 7 29 2016-07-29 5923880 2016 7 30 2016-07-30 5539041 2016 7 31 2016-07-31 5693306 31 rows selected (336.374 seconds)
OK, this is just a vague hunch. But looking at the Google Search Console (webmaster tools) for some of our domains, it's interesting that they show a very conspicuous drop in the number of hreflang tags roughly around the time where these main page bumps happened (July 20, on enwiki, ruwiki and nlwiki):
https://en.wikipedia.org/ (screenshot from here, access required):
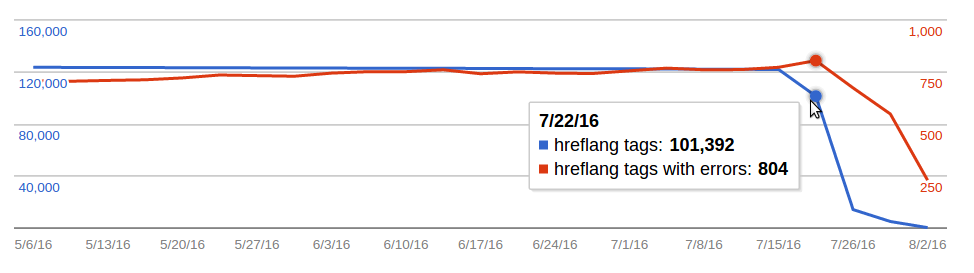
https://es.wikipedia.org/ (screenshot from here, access required):
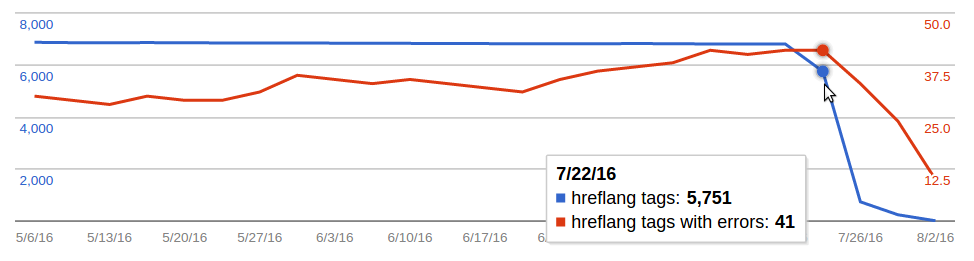
https://ar.wikipedia.org/ (screenshot from here, access required):
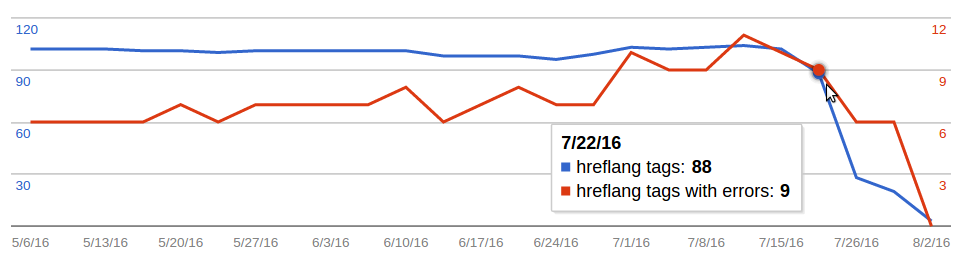
In contrast, the drop recorded for http://commons.wikimedia.org/ [sic] was less pronounced (screenshot from here, access required):

(I happened to check these because just today we received two notifications from the Google Search Console Team regarding "Incorrect hreflang implementation" on https://en.wikipedia.org/ and https://es.wikipedia.org/ . I can share more detail on these error notifications in case someone is interested and doesn't have access. But as can be seen from these charts, there had been errors all along, and their number actually decreased together with the overall number of tags. BTW I don't have access to the corresponding data for ruwiki and nlwiki; not sure if we have registered/verified these domains with Google at all.)
Of course one would expect that missing hreflang tags would decrease rather than increase traffic in the long term. But perhaps there is a common cause for both anomalies.
Some further remarks:
- This has a considerable effect on our global traffic metrics, too. Overall pageviews appear to have increased by over 11% due to this. We haven't seen such a large non-seasonal short-term change since the HTTPS rollout over a year ago. (The English Wikipedia's main page increase from roughly 15 to 57 million daily views alone accounts for about 8%; we generally have about half a billion daily global views.) The ratio of desktop pageviews increased by 5 percentage points in the last two weeks.
- On the other hand, at least on the English Wikipedia the daily unique devices numbers have not changed more than usual.
- Looking at http://discovery.wmflabs.org/external/#traffic_summary , the additional pageviews appear to have no referrer:
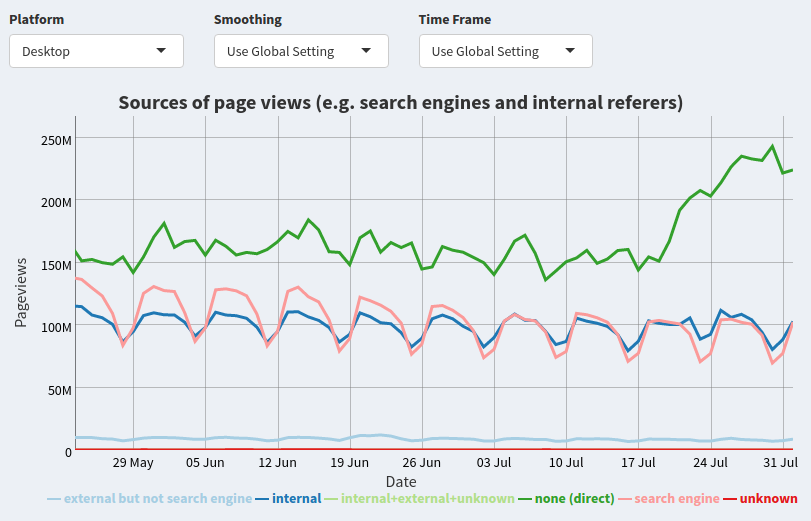
- The ratio of pageviews from the Global North hasn't changed more than usual (from 75.2% to 75.9% in the last two weeks), confirming that this isn't a bot operating from a specific location. (Although it is kind of interesting that the only three countries in the above list that did not see these at least five-fold increases - and which actually decreased - are all in the Global South.)
<s>That timing would line up with the merging/deployment of rMW208983b6d1f5: OutputPage: Only set <link hreflang=x-default> on wiki/pages with variants.</s>
Edit: Ignore me, I didn't notice that commit was from 2015, not 2016.
It would be interesting to have information on OS or other, if nothing else, to rule out some possibilities. (Imagine e.g. a Windows 10 update loading a preview of the Wikipedia main pages in the start menu.)
If so, something relying on Google's hreflang detection system should be correlated to the switch of links/clicks/traffic to main pages. Something like Knowledge Graph attribution links pointing to a main page rather than a localised version of the specific article on the topic?
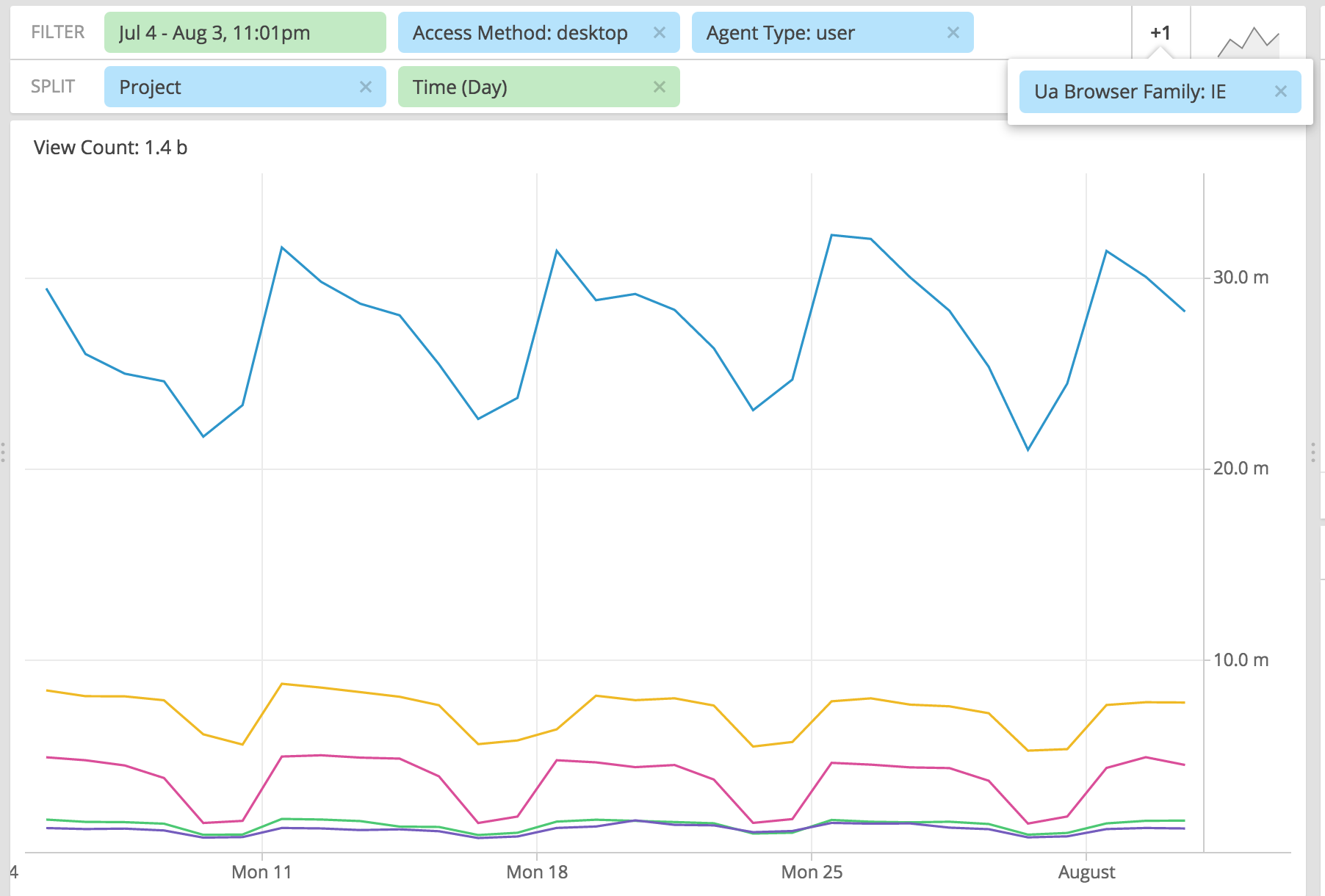

To follow up on Nuria's theory, we broke down the version of Chrome and see that Chrome 41 is almost solely responsible for the increase:
One possibility is that a bot running as Chrome 41 all of a sudden started being active from a lot of countries. Digging in more, but for others who are interested and have access to stat1002, the tunnel command to get to Pivot is:
ssh -N stat1002.eqiad.wmnet -L 9090:stat1002.eqiad.wmnet:9090
And the URL for the graph below is: Stable Pivot URL if you tunnel as above
If I filter just Chrome 41 on desktop, and break down by countries, I see something interesting. All countries appear to spike after July 20, but the United States has two small spikes before that. It's almost as if someone tested something (either a botnet or a patch to Chrome 41) in the US and then deployed it worldwide:
Also, a quick note: I couldn't find any article among the top 10 other than Main Page where this happens. I searched for a short while, but enwiki's Main Page is solely responsible for a 40M increase in pageviews.
One possibility is that a bot running as Chrome 41 all of a sudden started being active from a lot of countries.
This is unlikely a bot, it's probably the browser itself prefetching the main page, most requests come from windows 10/7
@Legoktm just pointed me here. I've been investigating something almost certainly-related, but I wasn't considering that changes to our content/output could be a factor: T141786 . In a nutshell, we've also observed at the Traffic level anomalies related to Chrome/41.0.2272.76 on Windows (all modern versions). Without historical context, I couldn't say whether they always had bad TLS behavior and their request-rate went up, or their request rate was constant and their TLS behavior regressed. From this ticket, it sounds like it could be the former (I was assuming the latter).
@BBlack this points to a chrome update for windows missbehaving, see updates: https://en.wikipedia.org/wiki/Google_Chrome_release_history
Any effect due to us seems that it had to be equally spread among pages and this is not the case as increase comes from Main_Page .Now, there might be several things here as July 20th is a release of other chrome version, not 41
All the anomalous stuff I'm looking at definitely points at Chrome/41.0.2272.76 on Windows (10, 8, 7), which is an old release. The timing of Microsoft's blundering of an SChannel/CryptoAPI update (that has messed up TLS for several bits of third party software) seemed very relevant, before seeing this ticket. Even after seeing this ticket, it's hard to tease apart cause and effect here. It could still be that a TLS bug is at the root of this, and it's causing the browser to abort/retry what should be a single fetch of Main_page many times in a row, which could in turn be triggered by users, or by some kind of built-in prefetching of our main page.
Copying in a couple of relevant links from the TLS ticket, re the bad MS update that seems to have at least partially broken TLS for some 3rd party software on Windows:
https://www.reddit.com/r/sysadmin/comments/4ogr7m/kb3163018_win_10_issue_block_this_sucker/
http://www.cisco.com/c/en/us/support/docs/customer-collaboration/unified-contact-center-express-1061/200556-UCCX-10-6-Pages-Does-not-Load-in-IE11-Af.html
If we are sure that what we are observing didn't happen in Iran and a few other countries, checking what updates actually affected those countries might help narrow down the list of possible causes. For instance, I see some recent Microsoft support threads implying that Windows 10 reaches Iranian users just fine, but it might not be the same yet for all updates.
@Nemo_bis : I do not think there is anything additional for us to do, requests are real, due to a probable malfunction of windows/chrome 41 but on our end there is not much we can do for spikes like these other than identify them and make sure they are labeled.
Documented issue on dataset page: https://wikitech.wikimedia.org/wiki/Analytics/Data/Pageview_hourly#Changes_and_known_problems_since_2015-06-16
If they are not listed as "user" views in the pageviews data, this is enough for our needs. Thanks.
Yeah, the only thing we could do is blacklist Chrome 41 on Windows from the pageviews data, but that would skew our data the other way. I tried but couldn't narrow it down more than that, to like a specific user agent or anything. We could also replace it with artificial traffic that mimics past traffic. Erik Zachte did this for spikes like these in the old Wikistats pageviews reports, we could use the same logic he did. But we should probably have a conversation about it before making decisions like that.
I understand; I meant that if you can get them labeled as non-user, that would be enough. You said "there is not much we can do for spikes like these other than identify them and make sure they are labeled", so I hoped you will label them so they wouldn't appear as real "user" views.
So, before seeing this ticket I hadn't been looking at the URL/hostname patterns of these requests. Now that I am:
In the US, we're seeing these strange/buggy Chrome/41 requests are almost exclusively coming from original requests for https://en.wikipedia.org/, which 301-redirects to /wiki/Main_Page, and then sometimes (at far lower rate) we see a few hits on related assets from /w/load.php and/or stats stuff hitting /beacon/event, etc. Filtering these requests down to just actual fetches on /wiki/FOO where FOO is anything but Main_page results in seeing the much lower (basically, statistically insignificant) traffic we'd expect to see from this outdated Chrome/41 release.
The situation is similar on our EU terminators, except that the bulk of the traffic is split about 60% ruwiki and 40% enwiki, with the ruwiki traffic having same initial fetch of / redirecting to ruwiki's equivalent of Main_page.
I'm still digging into this behavior a bit, I may yet be able to find out something more-concrete about what's going on here...
@Amire80 : what problem are these spikes causing you? The spikes represent real traffic, not per se "user initiated requests"
I'd like to know how many real users with real non-mobile browsers looked at the site to compare this with the number of people who clicked on interlanguage links. This is the main metric of success for the Compact Language Links feature which is being depliyed at the moment. Bots and any other non-interactive traffic is irrelevant for this.
If we're looking to reduce impact on global statistics interpretation, simply filtering out all requests which have a User-Agent string containing Chrome/41.0.2272.76 is probably a reasonable approach. It may kill some legitimate requests from that exact version on non-Windows platforms, and probably a handful of legitimate human requests from that version on Windows, but neither seems very statistically significant regardless. If you wanted to filter more-precisely (but I really don't think it's worth the effort), you could eliminate requests which contain all three of these attributes:
- UA string contains Chrome/41.0.2272.76
- UA string also contains Windows NT (any version)
- Request URL is for a real wiki page (/wiki/...) other than Main_page or its language-specific equivalent.
@Amire80 so we could try to clean up this data in our pageview data pipeline, but it would be a *lot* of effort. Also, I'm not at all sure how we would clean it. These requests are not originating from bots and they're not invalid pageviews in the technical sense. So they could be labeled as "bugs" somehow, which would mean even more changes.
As an alternative, I filed T142408. Taking care of this would mean people have better access to good annotations about these kinds of issues. We can extend the annotation to explain the extent of the problem, and clients could programatically adjust their visualizations. This seems like a more general way to deal with the problem. Perhaps another step would be to take Erik's smoothing algorithm and implement it in javascript so it could be applied on the fly based on annotation information.
I'd like to know how many real users with real non-mobile browsers looked at the site to compare this with the number of people who clicked on interlanguage links.
Side note: This calculation with the data we hold is hard to do in the best conditions. Our recommendation is that you look at sites (desktop versus mobile) not user agents. That being said if you remove in your end the "Main_Page" from your calculations you would not be affected by this anomaly. Also, be careful not to equal pageviews and users. We use unique devices as a proxy for users and that metric is not affected by this anomaly.
We are hesitant to remove/autocorrect what is actual, real, traffic. You are correct that the spike is mislabeled as "user" as those are not intentional pageviews but they are real requests being served by our stack to users. The issue is documented here: https://wikitech.wikimedia.org/wiki/Analytics/Data/Pageview_hourly
Please let us know if you need help working around the issue.
At the moment I am getting this info from https://tools.wmflabs.org/pageviews/ . AFAIK, it cannot currently filter out the Main Page in the Siteviews mode.
I either need that feature on that site, or an entirely different way to get the data, which filters the Main Page out. If I can, for example, get it as an HQL query that I can run on stat1002, it would be sufficient.
@Amire80, if you apply the following filter to any query against the pageview_hourly table on stat1002, it will exclude the spike. You will need to roll up to the project level yourself if you do it this way, but it's better than nothing:
where not (
user_agent_map['browser_family'] = 'Chrome'
and user_agent_map['browser_major'] = '41'
and user_agent_map['os_family'] = 'Windows'
and page_title = 'Main_Page'
)This will eliminate some legitimate Chrome 41 requests, but there are very few of those in general, so the loss should be negligible. If it's not, you can try to be more specific with the page_title filter and adding in a project filter as well. That's because as far as I understand the spike was seen mostly on a few wikis and always on the Main_Page (NOTE: localized title on some wikis).
Thanks, we'll try this. We'll probably have to redo how we run these metrics, but it was planned anyway :)
I had been trying to understand why the wikipedia.org portal pageviews had been on the rise recently and @Tbayer pointed me to this ticket.
We're not sure why it happened, but it does seem to be fairly consistent, time period wise, with the other increases in page views. You can view the portal dashboard here and below is a screen capture of the last few months of page views on the portal.
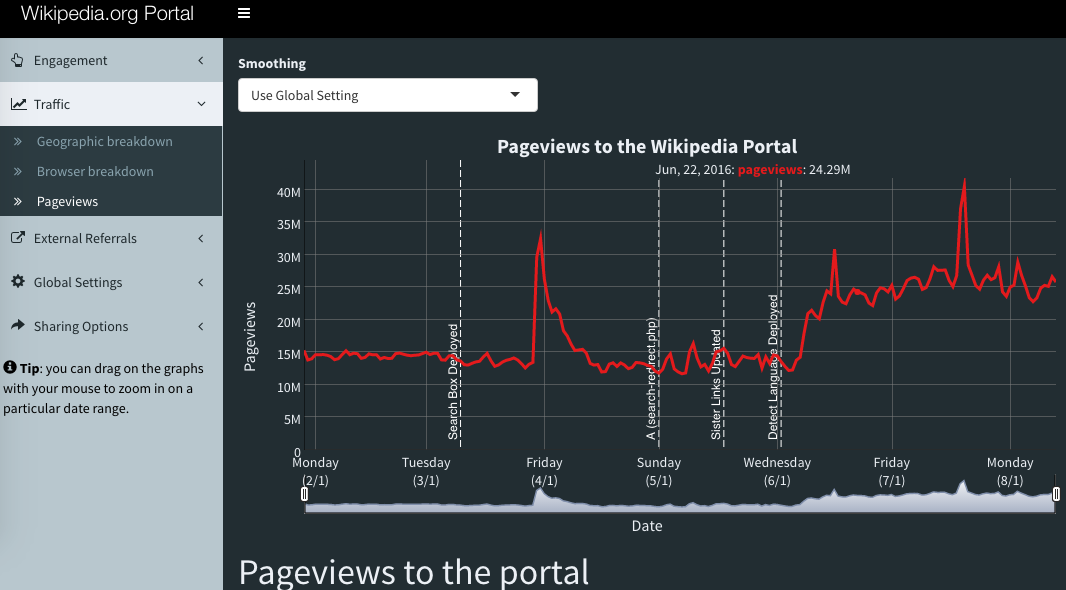
This is definitely interesting, but seems to have occurred in mid June (correct)? The issue discussed here happened around July 20.
@debt: Maybe you want to open another ticket? Make sure to note where are you getting your pageviews from, is it pageview API?
@Nuria: Since the pageviews UDF doesn't apply to the wikipedia.org portal page, we use a custom Hive query to count portal pageviews: https://github.com/wikimedia/wikimedia-discovery-golden/blob/master/portal/pageviews.R#L9
@Tbayer - the portal showed a spike to about 40.5Million pageviews on July 20th, so we felt it there a bit too, but ours did start in June.
Since the pageviews UDF doesn't apply to the wikipedia.org portal page
I assume you are talking about this page: https://www.wikipedia.org/
Your query has couple issues : does not filter self-reported bots and it does not filter by http codes. A pageview should always be a 200. Please open another ticket cause your issue seems slightly different.
Thanks, @Nuria - I've opened this ticket T143064 to update our eventlogging schema for the Wikipedia portal page (https://www.wikipedia.org)
@Nuria, did we do more investigation on this TLS hypothesis as cause of the pageview spike? I noticed that the Analytics Engineering team now appears to be reporting it as confirmed elsewhere ("Windows update caused a problem with the TLS handshake in Chrome 41").
If yes, has there been more insight on the actual mechanism, i.e. how this would generate extraneous main page views (only on some wikis, not in all countries)?
I will need to say a thing or two about this when presenting readership metrics at the metrics meeting next week (Aug 25), and would appreciate being able to present our best knowledge.
Also, considering the enormous dimension of the problem (possibly affecting several millions of actual human readers per day), and the fact that it seems to be persisting largely unabated after almost a month, an understanding of the actual mechanism might also be valuable regarding the possibility for workaround on our side that would make these people's reading experience better and decrease bandwidth usage for them.
@Tbayer: you can read plenty details on TLS issues here: https://phabricator.wikimedia.org/T141786 and the several tests the traffic team did on this regard.
If yes, has there been more insight on the actual mechanism, i.e. how this would generate extraneous main page views (only on some wikis, not in all countries)?
It is linked to a windows upgrade and as such we would not expect its effect to be uniform. There seems to be also a related issue with geoiplookup.
understanding of the actual mechanism might also be valuable regarding the possibility for workaround
on our side that would make these people's reading experience better and decrease bandwidth usage for them.
You can see changes done by traffic team, looks like sending out a 401 was effective, on the analytics end after narrowing down the UAS and OS affected we are not doing any further investigation.
I don't have a lot of firm information really. A lot of what we're going on here is guesses as to the exact mechanism and nature of the broken clients. There are multiple possible coincidences that could be causative (and of course, unknown factors totally out of our view and control), but the "bad MS update" theory seems the one that's the most-likely. We really don't know for sure.
We did deploy a workaround about 48 hours ago (after several other failed experimental attempts), which presents a "401 Unauthorized" response to the broken clients (Chrome/41.0.2272.76 on Windows) when they request the root URL of any wiki (which is the start of their spam request pattern, which then normally redirects to the Main_Page). ( T141786#2558383 )
The 401 (as opposed to other attempted [45]xx) does stop their cycle of repeated requests, but we have no idea whether the breakage is visible to any significant population of real users, or all of this is hidden in some background requests by the browser for e.g. pre-fetching. It fixed the bulk of the stats anomaly on the TLS Ciphers graphs. We've included a link to the phabricator bug and request to report, in two different places in the 401 response: in the "Reason" code sent with 401, and also as the value of the "Realm" for the authentication request (which would appear in the text of a popup username/password dialog if the 401 presents that to a human user). No users have followed up on that link so far.
A workaround HQL query is in T142505, thanks to pointers from @Milimetric about the user-agent. Examining the same UA around July 20th, the UA went from being usually fewer than 5% of pageviews on a particular wiki, to suddenly become more than two times the rest of pageviews combined.
Thanks for the link! Yes, that was exactly what I was looking for. (I know that task had been linked here some time ago, but considering the narrow scope of its title and the impact of the subsequent work there on this bug here, an update here could have been useful.)
OK, I have now read through your impressive detective work at T141786 - that's pretty much what I had in mind regarding further investigation and a workaround for affected users.
We did deploy a workaround about 48 hours ago (after several other failed experimental attempts), which presents a "401 Unauthorized" response to the broken clients (Chrome/41.0.2272.76 on Windows) when they request the root URL of any wiki (which is the start of their spam request pattern, which then normally redirects to the Main_Page). ( T141786#2558383 )
The 401 (as opposed to other attempted [45]xx) does stop their cycle of repeated requests, but we have no idea whether the breakage is visible to any significant population of real users, or all of this is hidden in some background requests by the browser for e.g. pre-fetching. It fixed the bulk of the stats anomaly on the TLS Ciphers graphs.
Also, rechecking the enwiki main page views with the latest data in, these seem to be back to almost the previous levels.
We've included a link to the phabricator bug and request to report, in two different places in the 401 response: in the "Reason" code sent with 401, and also as the value of the "Realm" for the authentication request (which would appear in the text of a popup username/password dialog if the 401 presents that to a human user). No users have followed up on that link so far.
Thanks! The last bit, combined with what you found at T141786#2557297 this week ("There are relatively-few IPs doing this, and they tend to repeat the cycle incessantly, up to a rate of roughly once per second") makes one confident that these extraneous pageviews really did not correspond to significant additional human consumption of Wikipedia content, so I'm now going to exclude them from the global pageviews I'm tracking. (That perspective is a bit different from @Amire80's need to compare only intentional user actions - if these views had been unintended but resulting in actual human reading acticity, I would have tended to include them, similar to @Nuria's view at T141506#2534689. These new insights however are also a strong argument to reconsider that decision to continue including these views in projectview_hourly and pageview_hourly.)
If I had a button that would exclude these views from projectview_hourly and pageview_hourly, I would click it without hesitation.
But as things are right now, we have to filter out these views manually from a fairly complicated pipeline and rerun a lot of dependent jobs. If people here feel this is important enough to prioritize over other Analytics infrastructure work, then please file a task and advocate for it.
If we do this, I would lean toward implementing a general ability to do this kind of thing in the future, because this is not the first nor last weird spike or drop that we see. So if we start redacting the pageview stream in the same way Erik Zachte used to fix his counts, we should build good reusable tools to do so.
One difference from the old pageview data is that consumers can remove these spikes themselves by applying the right filters, like in Helen's query. But I agree that's not completely satisfying, and it doesn't work on data sources like the Pageview API where all we have to help end-users are annotations.
My personal view on the matter is that this traffic should never be removed as it is actually real traffic. We probably should implement a way to tag it as "automated" or "spurious" traffic so as to distinguish it from users viewing content.
For the record and to save others trouble: There was a bug in this code (causing the filter not to exclude anything), which caused quite a bit of confusion over at T142505. The OS family condition needs to read user_agent_map['os_family'] LIKE 'Windows%'instead of user_agent_map['os_family'] = 'Windows'. See T142505#2569160 for details.
Huh, it turns out that Chrome 41 on Windows was actually only responsible for the rise on the enwiki and ruwiki main pages, not on nlwiki. There, it appears to have come from Chrome 19 on Windows instead - starting a day or two later (July 22), and ending equally suddenly on August 13, i.e. several days before the workaround was deployed:
SELECT year, month, day, CONCAT(year,"-",LPAD(month,2,"0"),"-",LPAD(day,2,"0")) AS date, SUM(view_count) AS all, SUM( IF( (user_agent_map['browser_family'] = 'Chrome' AND user_agent_map['browser_major'] = '41' AND user_agent_map['os_family'] LIKE 'Windows%'), view_count, 0)) AS Chrome41Windows, SUM( IF( (user_agent_map['browser_family'] = 'Chrome' AND user_agent_map['browser_major'] = '19' AND user_agent_map['os_family'] LIKE 'Windows%'), view_count, 0)) AS Chrome19Windows FROM wmf.pageview_hourly WHERE year = 2016 AND month > 6 AND project = 'nl.wikipedia' AND page_title = 'Hoofdpagina' AND agent_type = 'user' AND access_method = 'desktop' GROUP BY year, month, day ORDER BY year, month, day LIMIT 10000; year month day date all chrome41windows chrome19windows 2016 7 1 2016-07-01 63492 45 1 2016 7 2 2016-07-02 48066 25 2 2016 7 3 2016-07-03 50322 6 0 2016 7 4 2016-07-04 62591 45 2 2016 7 5 2016-07-05 64582 50 0 2016 7 6 2016-07-06 56058 48 0 2016 7 7 2016-07-07 54990 33 1 2016 7 8 2016-07-08 54253 25 1 2016 7 9 2016-07-09 41459 14 1 2016 7 10 2016-07-10 44160 705 2 2016 7 11 2016-07-11 64074 1528 6 2016 7 12 2016-07-12 62573 55 2 2016 7 13 2016-07-13 64557 39 0 2016 7 14 2016-07-14 56382 54 3 2016 7 15 2016-07-15 50746 30 0 2016 7 16 2016-07-16 43759 14 0 2016 7 17 2016-07-17 44824 27 0 2016 7 18 2016-07-18 52979 34 0 2016 7 19 2016-07-19 50608 40 1 2016 7 20 2016-07-20 50761 36 1 2016 7 21 2016-07-21 47879 39 2 2016 7 22 2016-07-22 302275 35 254435 2016 7 23 2016-07-23 502652 19 461691 2016 7 24 2016-07-24 503803 30 460753 2016 7 25 2016-07-25 543151 44 487486 2016 7 26 2016-07-26 543415 54 489267 2016 7 27 2016-07-27 533942 43 478443 2016 7 28 2016-07-28 513383 57 459995 2016 7 29 2016-07-29 550092 44 497609 2016 7 30 2016-07-30 507239 24 457493 2016 7 31 2016-07-31 366568 33 320394 2016 8 1 2016-08-01 286532 47 229109 2016 8 2 2016-08-02 286799 68 226313 2016 8 3 2016-08-03 278636 36 220575 2016 8 4 2016-08-04 348712 48 294469 2016 8 5 2016-08-05 502511 36 451621 2016 8 6 2016-08-06 521511 18 480516 2016 8 7 2016-08-07 495445 17 449988 2016 8 8 2016-08-08 536687 49 476874 2016 8 9 2016-08-09 508391 58 450495 2016 8 10 2016-08-10 548821 55 491600 2016 8 11 2016-08-11 550877 41 487955 2016 8 12 2016-08-12 519352 38 466354 2016 8 13 2016-08-13 141805 25 99151 2016 8 14 2016-08-14 44546 24 0 2016 8 15 2016-08-15 53758 41 0 2016 8 16 2016-08-16 56022 417 1 2016 8 17 2016-08-17 53064 164 1 2016 8 18 2016-08-18 53516 36 1 2016 8 19 2016-08-19 54150 24 0 2016 8 20 2016-08-20 37330 35 0 51 rows selected (764.666 seconds)
(See also this Pivot/Druid view, for those with access.)
How do we know it is? I have trouble reconciling this statement with:
(unless the two patterns described are separate).
Could it be someone just copying their current user-agent string for use in some bot?
It's more a philosophical than technical distinction that people are having different views on here. It is real traffic, in the sense that bits came down a wire and hit our servers. It may not be real traffic in the sense of intentional human will to view a Wikipedia page with their eyeballs.
On the Operations end of things, we look at data that is much closer to the wire-level view of traffic in raw HTTP request terms. Analytics is looking at the more human view of things. However, analytics output of human pageviews still has to be anchored to some technical explanation and derivation or it begins to lose all meaning and become arbitrary. IMHO, over the long term, if the high level explanation of analytics pageviews reads like "This is HTTP requests to wiki content pages by known browser and mobileapp agents, but we've also expertly and silently applied a lot of other filtering and manipulation you'll never understand", the meaning becomes fuzzy to the data consumer.
It's better that the baseline statistics have a solid and simple meaning, and that other one-off filtering and manipulation is applied on top of that in a way that's transparent to the consumer (e.g. flagging the requests as likely being related to particular persistent class of automation or abuse, or linking them to a particular short-duration incident). The bar for removing such a flagged class from the baseline data (where it becomes an invisible-to-the-consumer filter, unless you add more complexity to the explanation of the baseline data) should be pretty high.
Could it be someone just copying their current user-agent string for use in some bot?
Seems very unlikely that a 401 non authorized would stop the traffic if that was a bot. Also bots do not tend to request the top domain but rather specific pages. So, no, this seems unintentional traffic from some readers computers.
For reference and as summary of the corrections made since last week to the initially suggested filter, this is the expression I'm using currently (here as part of a query of global human pageviews that also retrieves mobile traffic):
SELECT year, month, day, CONCAT(year,'-',LPAD(month,2,'0'),'-',LPAD(day,2,'0')) AS date, SUM(IF(access_method <> 'desktop', view_count, null)) AS mobileviews, SUM(view_count) AS allviews FROM wmf.pageview_hourly WHERE year = 2016 AND month > 6 AND agent_type = 'user' AND NOT ( -- See https://phabricator.wikimedia.org/T141506 access_method = 'desktop' AND user_agent_map['os_family'] LIKE 'Windows%' AND user_agent_map['browser_family'] = 'Chrome' AND ( ( user_agent_map['browser_major'] = '41' AND project = 'en.wikipedia' AND page_title = 'Main_Page' ) OR ( user_agent_map['browser_major'] = '41' AND project = 'ru.wikipedia' AND page_title = 'Заглавная_страница' ) OR ( user_agent_map['browser_major'] = '19' AND project = 'nl.wikipedia' AND page_title = 'Hoofdpagina' ) ) ) GROUP BY year, month, day ORDER BY year, month, day LIMIT 1000;
(This of course assumes that the anomalies on the Dutch Wikipedia are of the same nature as those examined by @BBlack on enwiki and/or ruwiki, even though a different version of Chrome - from 2012! - is involved.)
This task is still open after more than a year, and continues to affect pageview data analysis. I have filed T175870 to remedy that.
Is this resolved? The English Wikipedia main page seems to be again within the 20M/d threshold:
https://tools.wmflabs.org/pageviews/?project=en.wikipedia.org&platform=all-access&agent=user&range=all-time&pages=Main_Page
We do not plan to remove the real (if unintentional) spike of pageviews that hit our servers on 2016, is that what you mean? Or are you referring to a more recent event?
I'm referring to the fact that all seems good now. If there are no action items left, this could be closed.