I have noticed CI jobs running on integration-slave-docker-1003 to take twice longer than on other instances. The usual suspect is the underlying Compute node being CPU starved.
Looking at the https://grafana.wikimedia.org/dashboard/db/labs-capacity-planning?panelId=91&fullscreen&orgId=1 graph of CPU usage (7 days), five of the labvirt have very high CPU usage:
| labvirt1001 |
| labvirt1002 |
| labvirt1008 |
| labvirt1011 |
| labvirt1013 |
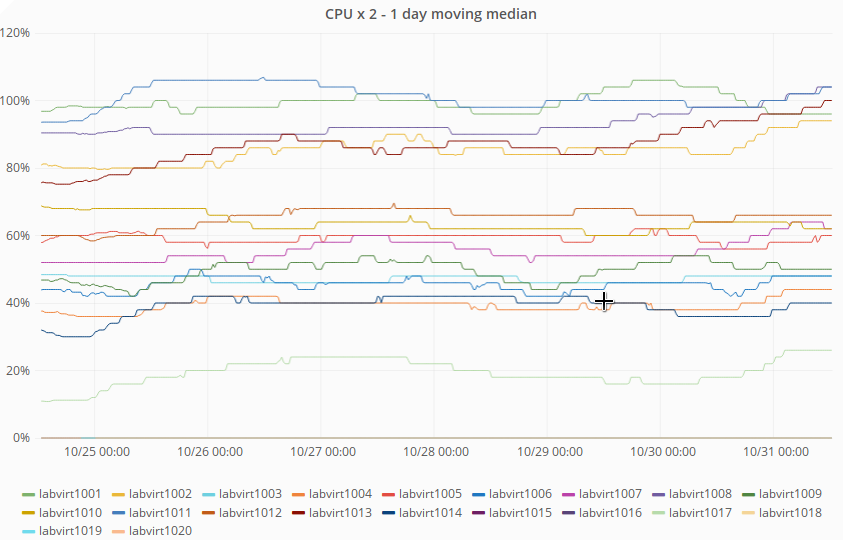
NOTE: labvirt have hyperthreading activated, Diamond aggreate the CPU usage and divide that by the total number of CPU including the HT one. The graph multiply the value by two to more or less take in account hyper threading.