Some Wikidata entries do not seem to appear in ElasticSearch index, e.g.: https://www.wikidata.org/wiki/Q45825730, https://www.wikidata.org/wiki/Q45825742, https://www.wikidata.org/wiki/Q45825741, https://www.wikidata.org/wiki/Q45825750. cirrusDump returns empty for them. They are created recently, but not recently enough so the lag is the reason - a day or more has passed.
Description
Description
| Status | Subtype | Assigned | Task | ||
|---|---|---|---|---|---|
| Open | None | T46529 Wikidata search problems (tracking) | |||
| Resolved | PRODUCTION ERROR | • Imarlier | T183101 Items missing from Wikidata index due to LinksUpdate lock failures |
Event Timeline
Comment Actions
I can see data in https://www.wikidata.org/wiki/Q45825730?action=cirrusDump now but not in https://www.wikidata.org/wiki/Q45825750?action=cirrusDump. Extreme case of delay or something going really wrong here?
Comment Actions
Q45825750 has page ID of 46985262. Kibana says:
Could not acquire lock 'LinksUpdate:atomicity:pageid:46985262'.
Could be the reason for failed update.
Comment Actions
@aaron is the author of that code, maybe has any ideas why this lock could fail? I see 5 failures on this page in Kibana.
Comment Actions
Looks like we have 2 spikes of LinksUpdate errors: https://logstash.wikimedia.org/goto/a2050a1aca3e9d8c9bf7089ee2d2431d - which may be caused by some kind of database problems. We need to think how to make system more robust so that such problems do not lead to items disappearing.
Comment Actions
Aaron is on vacation this week, likely not paying any attention to notifications. We'll try to take a look at it without him.
Comment Actions
Looking at Q45825750, there were 7 edits made very quickly right after another, so it seems reasonable that a links update would be in progress, holding the lock, and then another links update would be unable to get the lock and fail. However, AFAIK failed jobs are supposed to retry after an hour, so I'm not sure why that didn't happen here. (Unless all the jobs retried around the same time and ran into the lock problem again..?)
Comment Actions
Just throwing a couple of notes in here:
Q45825741 and Q45825750 were both updated at very close to the same time (2017-12-16 14:54:00-15:02:00); both had a number of updates that happened within a very tight window (<1 minute). Both also have log entries indicating that they experienced failures getting a lock:
2017-12-16T14:55:09 mw1283 INFO Expectation (readQueryTime <= 5) by MediaWiki::restInPeace not met (actual: 15.000407934189):
query-m: SELECT GET_LOCK('X', N) AS lockstatus [TRX#43742a]
#0 /srv/mediawiki/php-1.31.0-wmf.12/includes/libs/rdbms/TransactionProfiler.php(223): Wikimedia\Rdbms\TransactionProfiler->reportExpectationViolated()
#1 /srv/mediawiki/php-1.31.0-wmf.12/includes/libs/rdbms/database/Database.php(1049): Wikimedia\Rdbms\TransactionProfiler->recordQueryCompletion()
#2 /srv/mediawiki/php-1.31.0-wmf.12/includes/libs/rdbms/database/Database.php(948): Wikimedia\Rdbms\Database->doProfiledQuery()
#3 /srv/mediawiki/php-1.31.0-wmf.12/includes/libs/rdbms/database/DatabaseMysqlBase.php(1039): Wikimedia\Rdbms\Database->query()
#4 /srv/mediawiki/php-1.31.0-wmf.12/includes/libs/rdbms/database/Database.php(3559): Wikimedia\Rdbms\DatabaseMysqlBase->lock()2017-12-16T15:00:38 mw1235 INFO Expectation (readQueryTime <= 5) by MediaWiki::restInPeace not met (actual: 15.000345230103):
query-m: SELECT GET_LOCK('X', N) AS lockstatus [TRX#aa6d60]
#0 /srv/mediawiki/php-1.31.0-wmf.12/includes/libs/rdbms/TransactionProfiler.php(223): Wikimedia\Rdbms\TransactionProfiler->reportExpectationViolated()
#1 /srv/mediawiki/php-1.31.0-wmf.12/includes/libs/rdbms/database/Database.php(1049): Wikimedia\Rdbms\TransactionProfiler->recordQueryCompletion()
#2 /srv/mediawiki/php-1.31.0-wmf.12/includes/libs/rdbms/database/Database.php(948): Wikimedia\Rdbms\Database->doProfiledQuery()
#3 /srv/mediawiki/php-1.31.0-wmf.12/includes/libs/rdbms/database/DatabaseMysqlBase.php(1039): Wikimedia\Rdbms\Database->query()
#4 /srv/mediawiki/php-1.31.0-wmf.12/includes/libs/rdbms/database/Database.php(3559): Wikimedia\Rdbms\DatabaseMysqlBase->lock()
#5 /srv/mediawiki/php-1.31.0-wmf.12/includes/deferred/LinksUpdate.php(203): Wikimedia\Rdbms\Database->getScopedLockAndFlush()
#6 /srv/mediawiki/php-1.31.0-wmf.12/includes/deferred/LinksUpdate.php(170): LinksUpdate::acquirePageLock()
#7 /srv/mediawiki/php-1.31.0-wmf.12/includes/deferred/DeferredUpdates.php(259): LinksUpdate->doUpdate()
#8 /srv/mediawiki/php-1.31.0-wmf.12/includes/deferred/DeferredUpdates.php(210): DeferredUpdates::runUpdate()
#9 /srv/mediawiki/php-1.31.0-wmf.12/includes/deferred/DeferredUpdates.php(131): DeferredUpdates::execute()
#10 /srv/mediawiki/php-1.31.0-wmf.12/includes/MediaWiki.php(897): DeferredUpdates::doUpdates()
#11 /srv/mediawiki/php-1.31.0-wmf.12/includes/MediaWiki.php(719): MediaWiki->restInPeace()
#12 (): Closure$MediaWiki::doPostOutputShutdown()
#13 {main}Both of those records also have one or more log entries showing that db1100 was significantly lagged at this time:
2017-12-16T14:54:54 mw1283 WARNING Wikimedia\Rdbms\LoadBalancer::doWait: Timed out waiting on db1100 pos db1070-bin.001655/818130407
2017-12-16T15:00:44 mw1314 WARNING Wikimedia\Rdbms\LoadBalancer::doWait: Timed out waiting on db1100 pos db1070-bin.001655/821972877
This doesn't necessarily mean anything, but it does immediately bring to mind the possibility of a bad interaction between two simultaneous transactions -- a process that gets the update lock, then tries to read from a slave that's lagged, times out waiting on that, and ultimately bails out without releasing the lock?
This code is new to me, but that seems like an angle that's worth looking at.
Q45825730 and Q45825742 were both created around the same time. However, neither of them shows any indication of similar database timeouts or lock failures. Here's 42:
Time host level message 2017-12-16T14:55:07 mw1286 INFO AbuseFilter::filterAction: cache miss for 'Q45825742' (key wikidatawiki:abusefilter:check-stash:default:19082eae700e0352ac30604486024ca3:v1). 2017-12-16T14:54:03 wdqs1003 INFO Got 5 changes, from Q45825742@609888642@20171216145333|645260053 to Q17580698@609888669@20171216145400|645260055 2017-12-16T14:53:33 mw1316 INFO AbuseFilter::filterAction: cache miss for 'Q45825742' (key wikidatawiki:abusefilter:check-stash:default:75754391037fe534c51178ac2603dc26:v1). 2017-12-16T14:53:23 wdqs1005 INFO Got 2 changes, from Q2492695@609888609@20171216145249|645260020 to Q45825742@609888612@20171216145251|645260022 2017-12-16T14:53:23 wdqs2002 INFO Got 2 changes, from Q2492695@609888609@20171216145249|645260020 to Q45825742@609888612@20171216145251|645260022 2017-12-16T14:53:22 wdqs1004 INFO Got 2 changes, from Q2492695@609888609@20171216145249|645260020 to Q45825742@609888612@20171216145251|645260022 2017-12-16T14:53:22 wdqs2001 INFO Got 2 changes, from Q2492695@609888609@20171216145249|645260020 to Q45825742@609888612@20171216145251|645260022 2017-12-16T14:53:22 wdqs2003 INFO Got 2 changes, from Q2492695@609888609@20171216145249|645260020 to Q45825742@609888612@20171216145251|645260022 2017-12-16T14:53:20 wdqs1003 INFO Got 2 changes, from Q2492695@609888609@20171216145249|645260020 to Q45825742@609888612@20171216145251|645260022 2017-12-16T14:53:20 mw1280 INFO AbuseFilter::filterAction: cache miss for 'Q45825742' (key wikidatawiki:abusefilter:check-stash:default:09f6595b2b674089e12c1c01698946af:v1). 2017-12-16T14:53:08 mw1232 INFO AbuseFilter::filterAction: cache miss for 'Q45825742' (key wikidatawiki:abusefilter:check-stash:default:f6f3586b5afd827fb2bfcdf305d4f41b:v1). 2017-12-16T14:52:51 mw1290 INFO AbuseFilter::filterAction: cache miss for 'Q45825742' (key wikidatawiki:abusefilter:check-stash:default:43b4667869d07ce4d7e32e416f51b9b3:v1). 1–12 of 12
And here's 30:
Time host level message 2017-12-16T15:03:41 wdqs2001 INFO Got 100 changes, from Q40739103@609888095@20171216144339|645259546 to Q45825730@609888298@20171216144625|645259730 2017-12-16T15:03:41 wdqs1005 INFO Got 100 changes, from Q40739103@609888095@20171216144339|645259546 to Q45825730@609888298@20171216144625|645259730 2017-12-16T14:46:25 mw1317 INFO AbuseFilter::filterAction: cache miss for 'Q45825730' (key wikidatawiki:abusefilter:check-stash:default:e059a2c2b6c96934a8967978dcecdaa0:v1). 1–3 of 3
Also noticing that there were exceptions showing up in Logstash around this time:
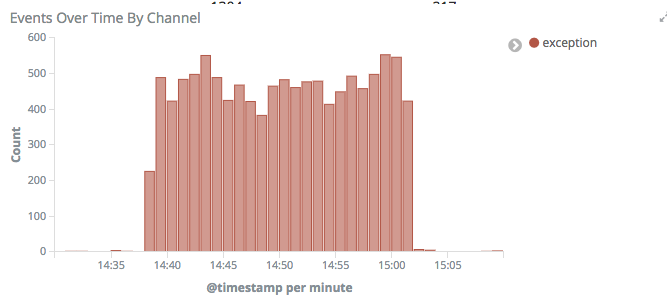
This approx. 10 minute period of time accounts for nearly 30% of all exceptions reported to logstash in the last week.
No smoking guns, but I think this points us in the right direction. I'm going to look into it more this afternoon.
Comment Actions
First appearance of a timeout on db1100:
2017-12-16T14:37:46 mw1311 WARNING Wikimedia\Rdbms\LoadBalancer::doWait: Timed out waiting on db1100 pos db1070-bin.001655/808461384
First exception trying to get the lock:
2017-12-16T14:38:16 mw1290 ERROR [WjUvyQpAEDcAACARVmoAAACM] /w/api.php RuntimeException from line 205 of /srv/mediawiki/php-1.31.0-wmf.12/includes/deferred/LinksUpdate.php: Could not acquire lock 'LinksUpdate:atomicity:pageid:1524206'.
Prior to this exception being recorded, there hadn't been any exceptions received for a period of nearly 2 minutes -- in particular, there hadn't been any database timeouts or slave replication lag issues during that time.
The first indication of replication lag is recorded 27 seconds later:
2017-12-16T14:38:43 mw1308 ERROR [8e59bd7e779c680d140f8366] /rpc/RunJobs.php?wiki=dawiki&type=refreshLinks&maxtime=30&maxmem=300M Wikimedia\Rdbms\DBReplicationWaitError from line 373 of /srv/mediawiki/php-1.31.0-wmf.12/includes/libs/rdbms/lbfactory/LBFactory.php: Could not wait for replica DBs to catch up to db1070
Last set of timeouts waiting on replication to db1100:
2017-12-16T15:02:02 mw1239 WARNING Wikimedia\Rdbms\LoadBalancer::doWait: Timed out waiting on db1100 pos db1070-bin.001655/825818703 2017-12-16T15:02:06 mw1288 WARNING Wikimedia\Rdbms\LoadBalancer::doWait: Timed out waiting on db1100 pos db1070-bin.001655/826052699 2017-12-16T15:02:12 terbium WARNING Wikimedia\Rdbms\LoadBalancer::doWait: Timed out waiting on db1100 pos db1070-bin.001655/826518643 2017-12-16T15:02:25 mw1286 WARNING Wikimedia\Rdbms\LoadBalancer::doWait: Timed out waiting on db1100 pos db1070-bin.001655/827446248 2017-12-16T15:03:25 mw1286 WARNING Wikimedia\Rdbms\LoadBalancer::doWait: Timed out waiting on db1100 pos db1070-bin.001655/831205807
This is right around when everything recovered, and I don't think that it's coincidence. I'm not sure yet how this is all overlapping, but I'm pretty certain that it is.
Comment Actions
Alternate theory that I think is wrong: there's a chance that something wonky happened with db1070 around this time, which caused replication to stop and may also have caused issues getting locks. If that were the case I would expect to see far more write errors here (like on the original submit, and not just on the LinksUpdate job), but I can't rule it out right now.
Comment Actions
Just noticed this in SAL:
15:00 <jynus@tin> Synchronized wmf-config/db-eqiad.php: Depool db1100 (duration: 00m 58s)
Potentially interesting, given that timeouts has started to be reported slightly before that.
The commit that was being synced just refers to the host as being broken: https://phabricator.wikimedia.org/rOMWC6b3f4c9b5be8f231fb4c687e8cdcff2468796905
This does explain the big surge in exceptions around that time, but doesn't help to clear up what connection (if any) this issue had to the failed LinksUpdate jobs.
Comment Actions
(Access was fixed.)
Closing as resolved for now. We've not been able to fine another case of this, and the case we know coincided with a spike of database errors relating to T180918.
One possible take away is that we may need to look into how the RDBMS interface reacts if a lock couldn't be acquired and also wasn't known to be acquired elsewhere. Right now it looks like it just returns false, which is interpreted by the update job as "work already being done elsewhere" and returns in a way that makes the job a no-op that ends successfully.
Comment Actions
I think there is a different core returned between killed (or other error)-although I think in this case there is an exception, timed out and acquired, but I may be wrong. Note that on that ticket, I mention waits for slave can start being killed from now on to avoid pileups.