In T192464, the user agent parsing regexes from ua-parser are being updated for the first time in two years. We need to know whether/how this affects our traffic data, at least for the core metrics.
- What percentage of global human pageviews (i.e. those with agent_type = 'user', a core metric we report to the board on a monthly basis) are going to be reclassified as spider pageviews?
- What percentage of monthly Wikipedia uniques devices (a core metric we report to the board on a monthly basis, calculated based on webrequests with agent_type = 'user') is going to be removed by improved spider classification?
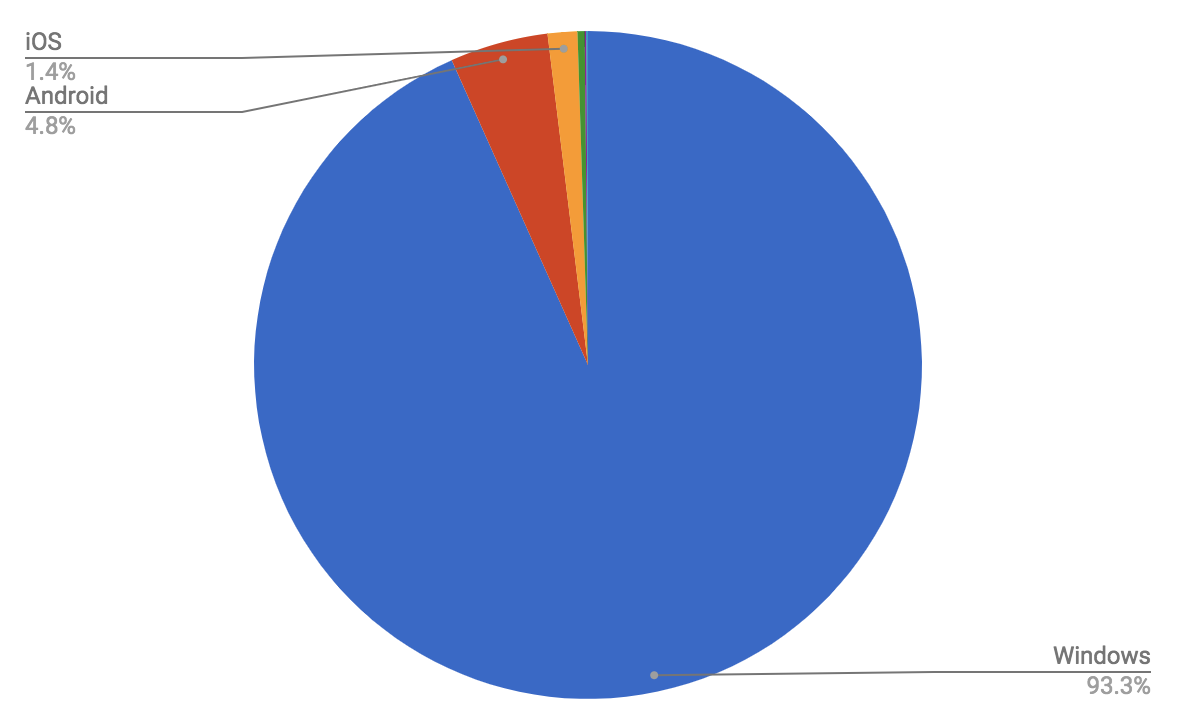
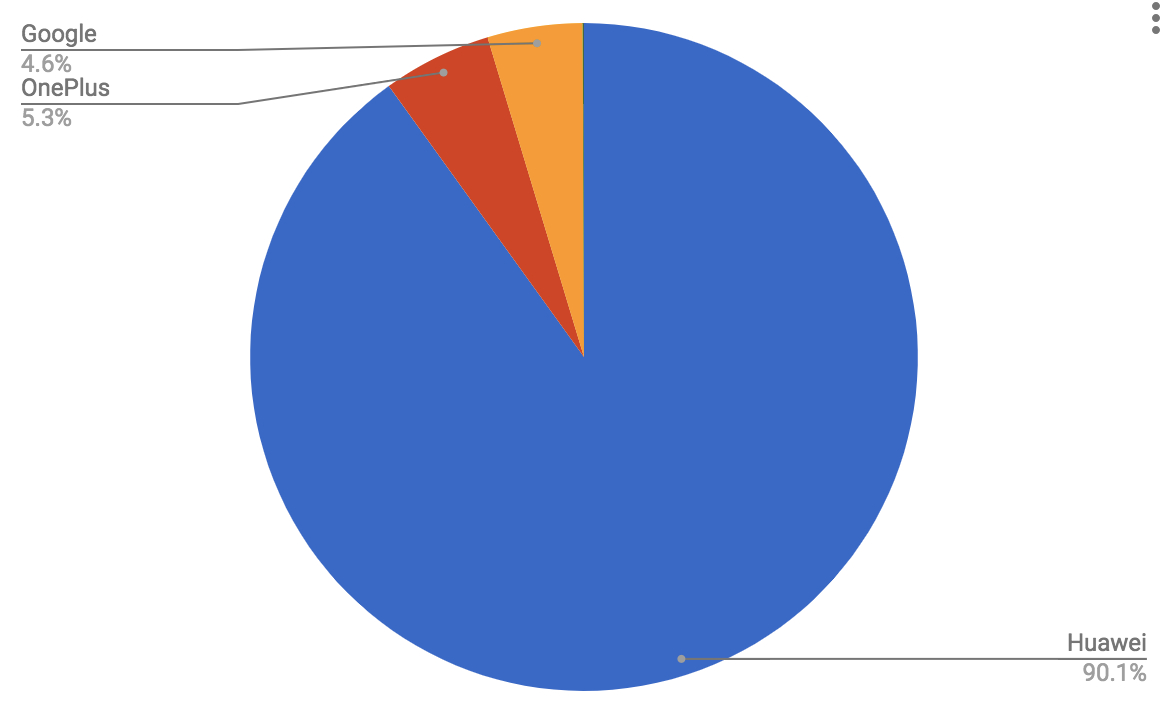
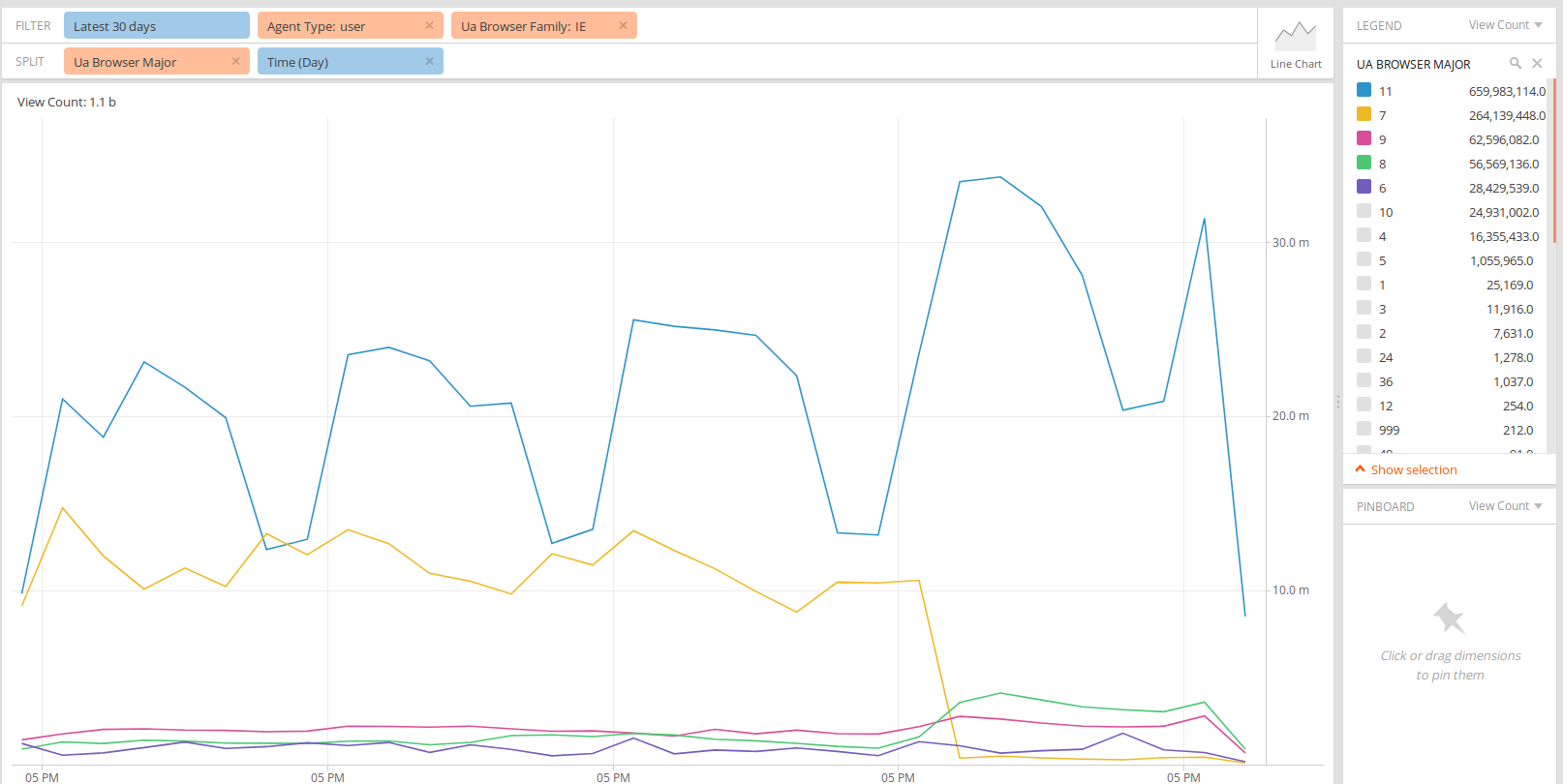
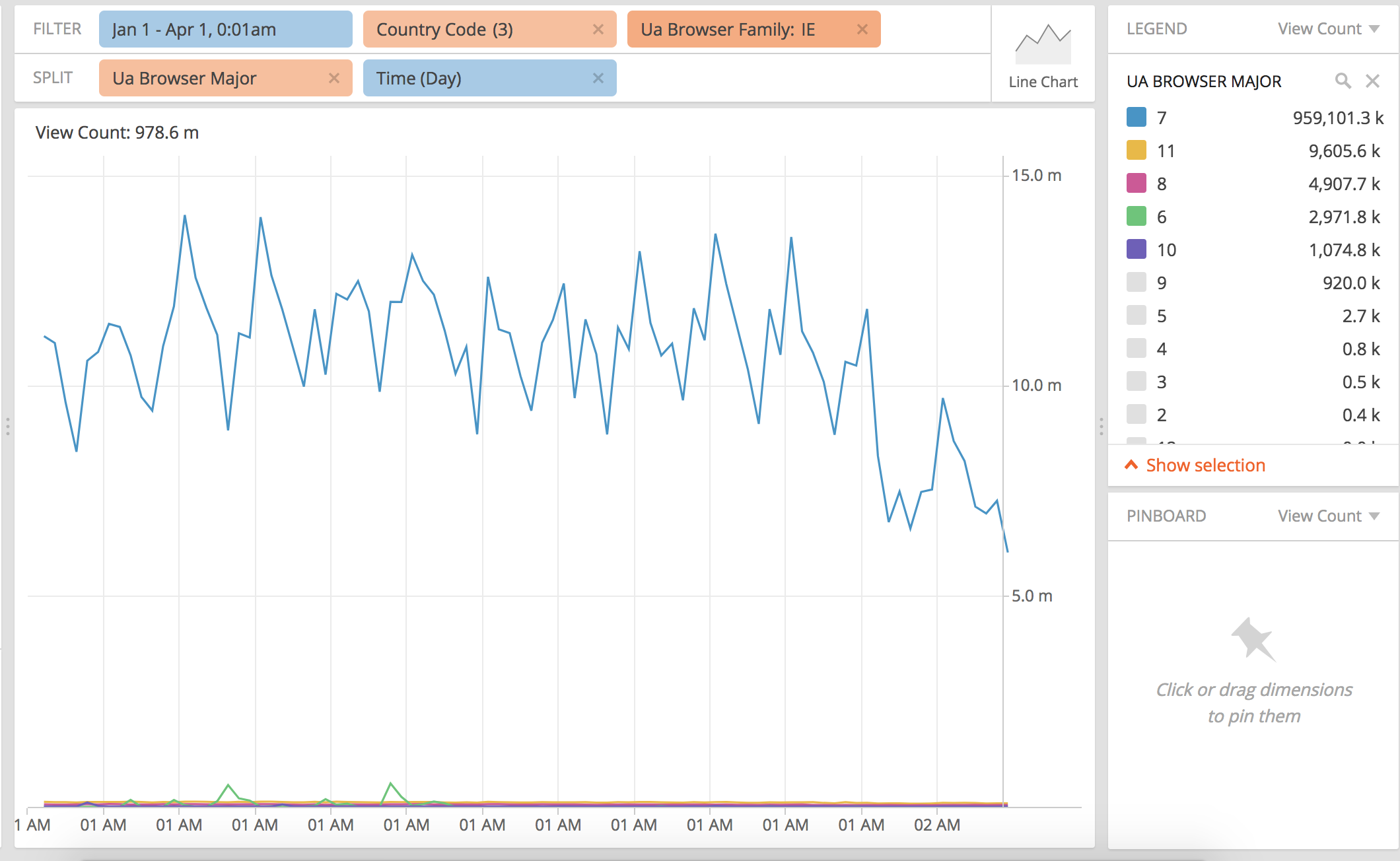
- Are there any browsers or browser versions whose place in the browser support matrix is changing due to improved classification in the new version?