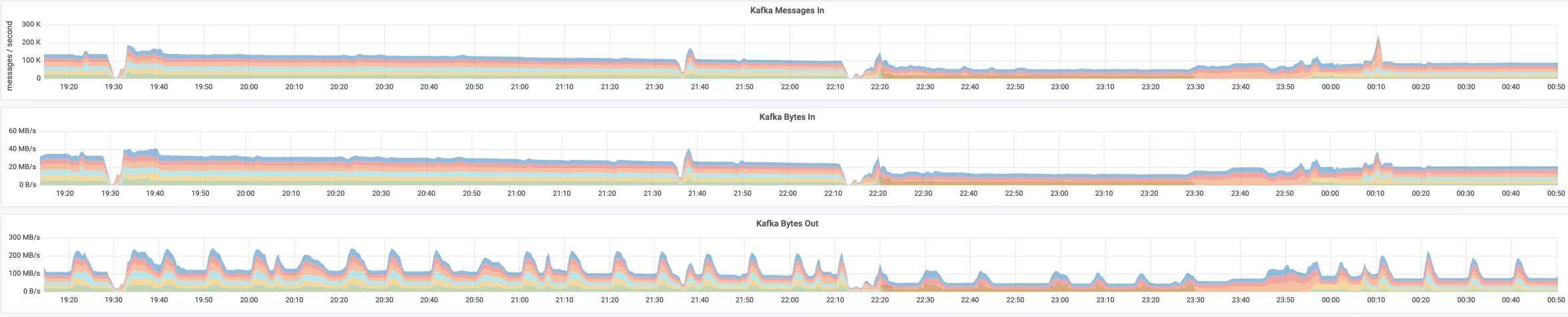
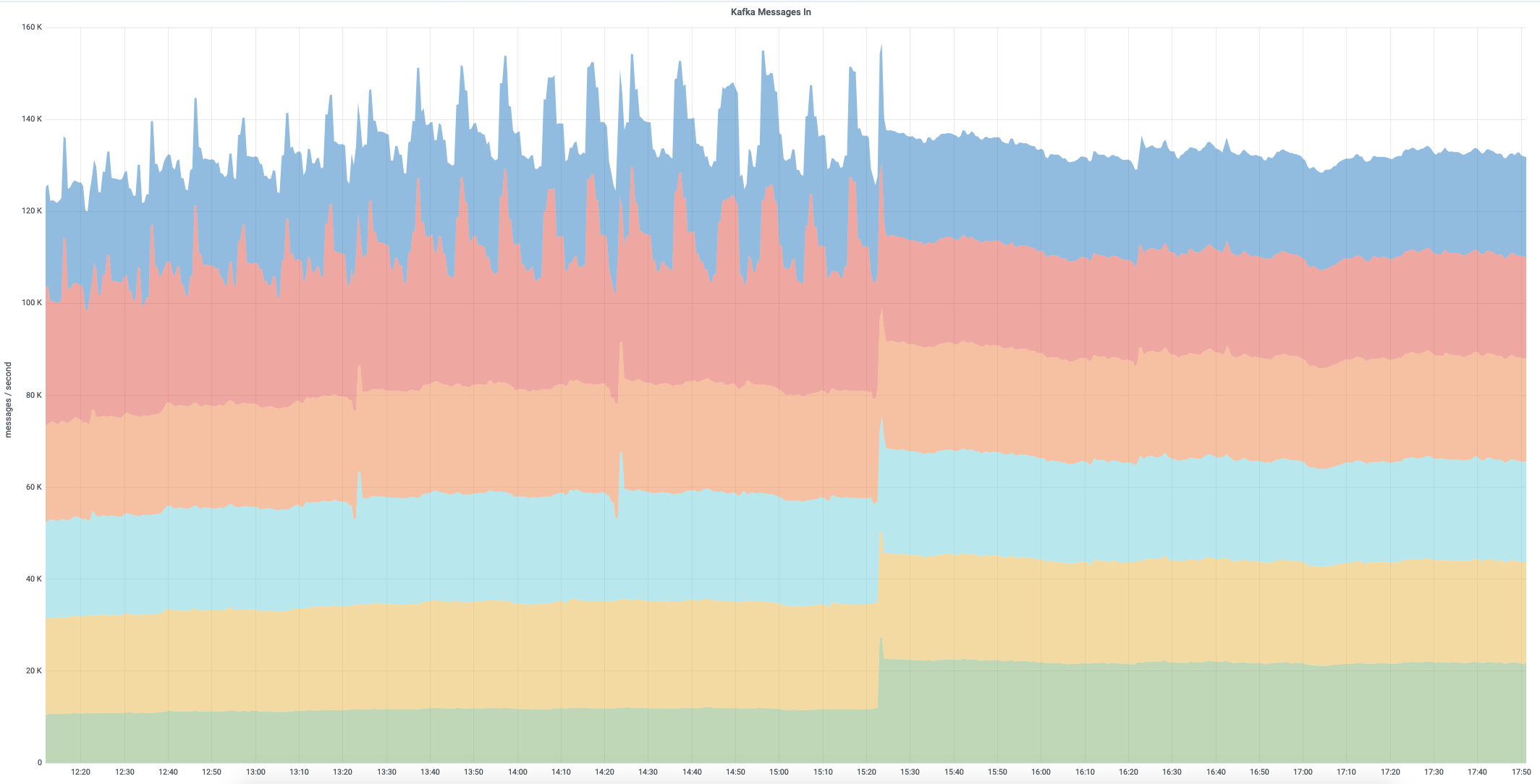
Incident documentation: https://wikitech.wikimedia.org/wiki/Incident_documentation/20190402-0401KafkaJumbo
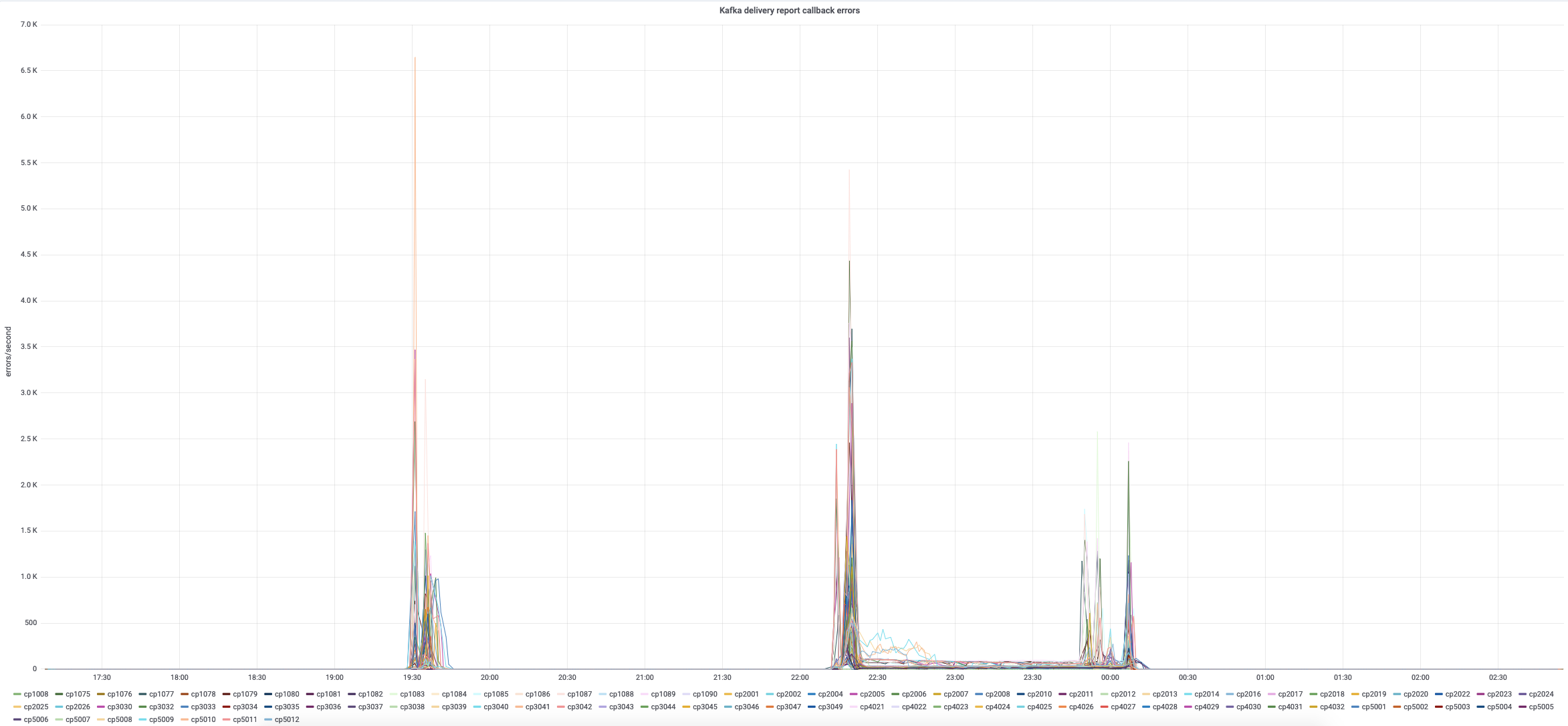
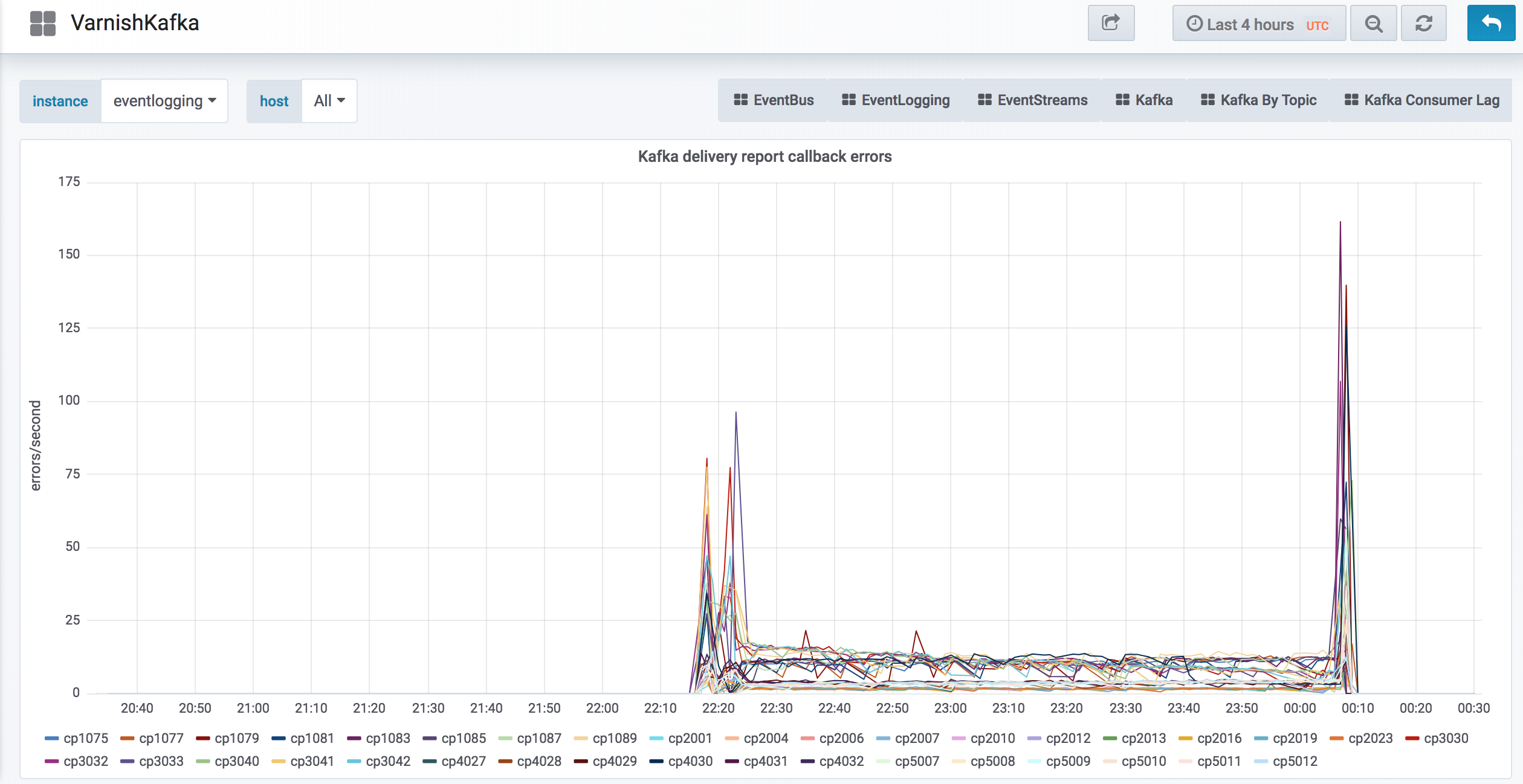
Tons of callback errors on varnishkafka: https://grafana.wikimedia.org/d/000000253/varnishkafka?orgId=1&var-instance=eventlogging&var-host=All&from=1554074545652&to=1554160945652
See call back errors in varnishkafka while incident is going on:
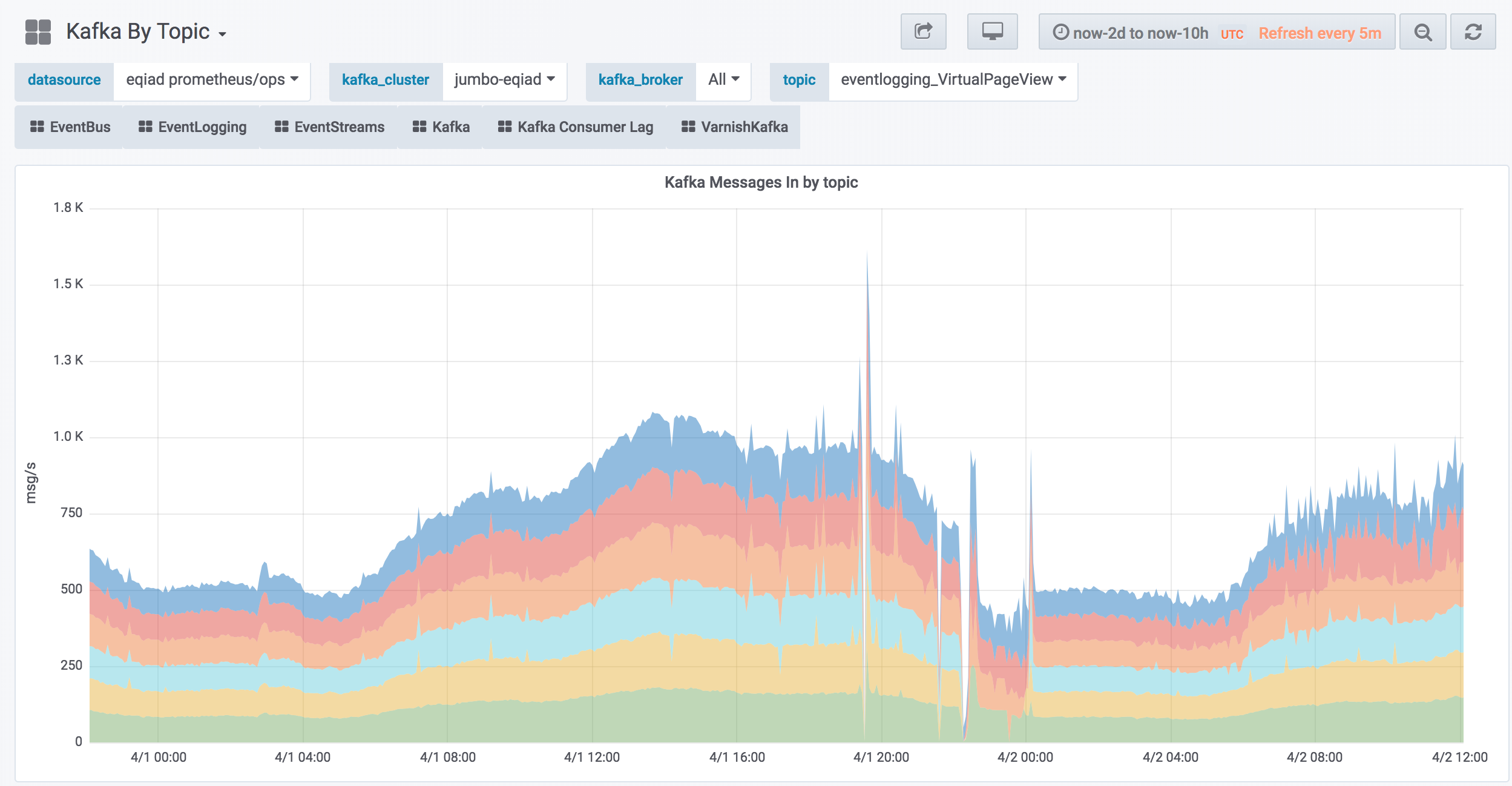
See how two brokers "disappear" from a topic while incident is going on: