I has happened twice recently and affected the cirrusSearchLinksUpdatePrioritized queue.
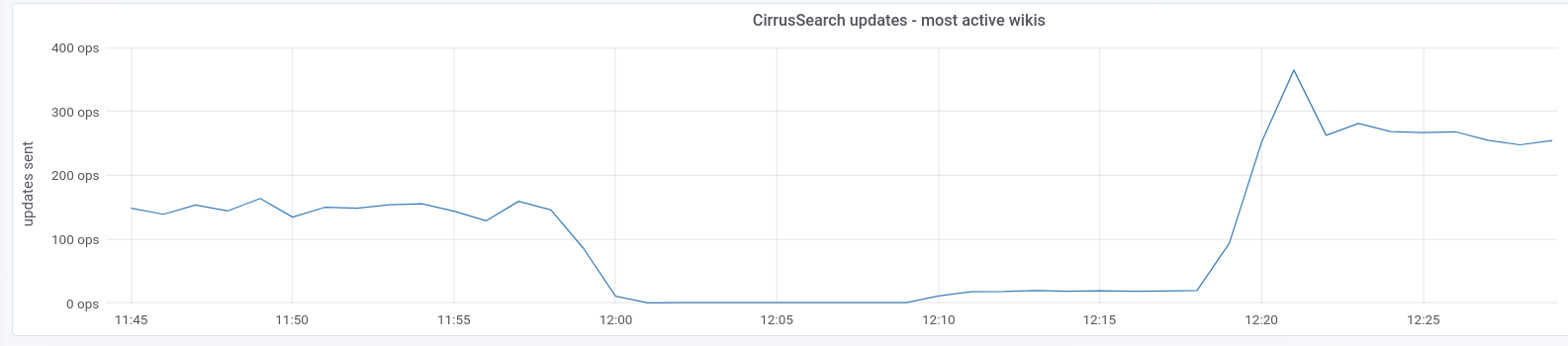
The impact on Cirrus updates is visible as we nearly stop pushing data to elastic from CirrusSearch:
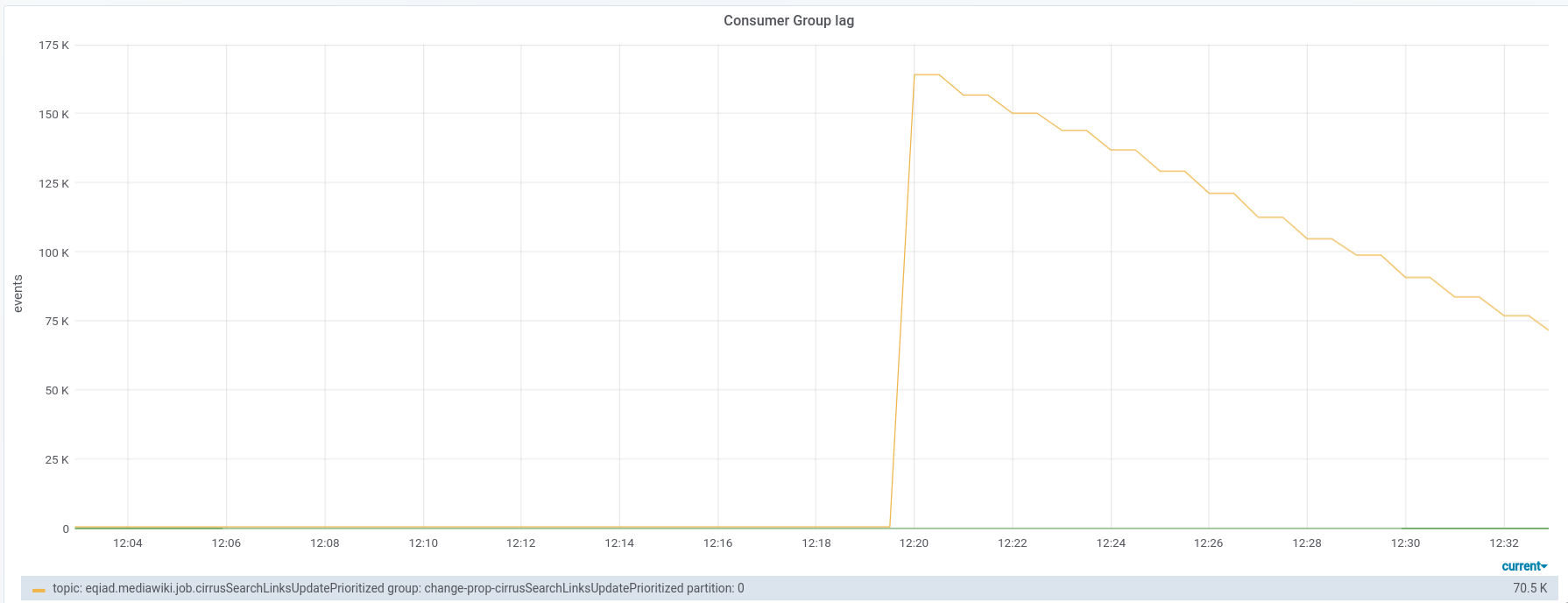
From Kafka Consumer lag just (when we seem to resume consuming 12:20) we have enqueued 164k doc to this queue (template update?):
In this example we seem to have stopped consuming this queue for about 20 minutes (2019-05-27 from 12:00 to 12:20).