With the introduction of the WDQS lag in Wikidata's maxlag computation (T221774), we are now seeing the behaviour I feared: bots start and stop brutally as the lag rises and falls.
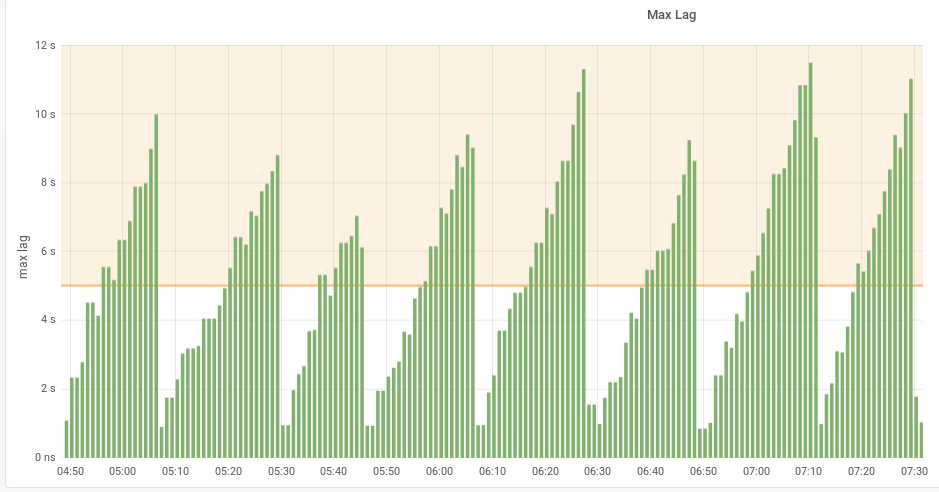
https://grafana.wikimedia.org/dashboard/snapshot/mbbjQjo7FMnDAath4tuRyP7F9300Wj2S?orgId=1
This morning, bots which used maxlag=5 for their edits (as advised) could only edit about half of the time. This start and stop behaviour is not desirable: bots should slow down gradually as the lag increases instead of running at full speed until the lag reaches 5.
We should agree on a better throttling policy and implement it in most bot editing frameworks (QuickStatements, Pywikibot, OpenRefine, …) to improve everyone's experience with the service.
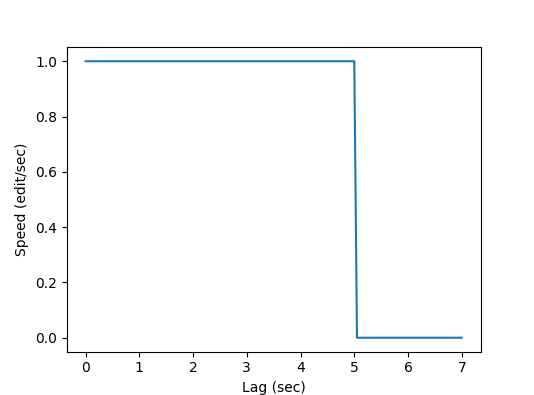
The current policy looks like this, assuming a default rate of 1 edit/sec:
We could instead try something like this, with a gradual slowdown as soon as maxlag goes above 2.5 sec (half the threshold where it should stop), for instance:
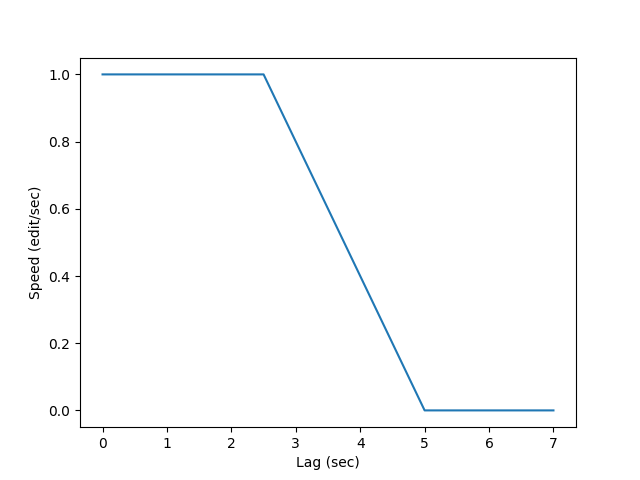
Would this be a sensible throttling policy to encourage? I believe this should avoid the start/stop behaviour shown above, once such a behaviour is adopted by most bots (which should not be super hard: by patching the most popular editing backends, we should cover most of it).