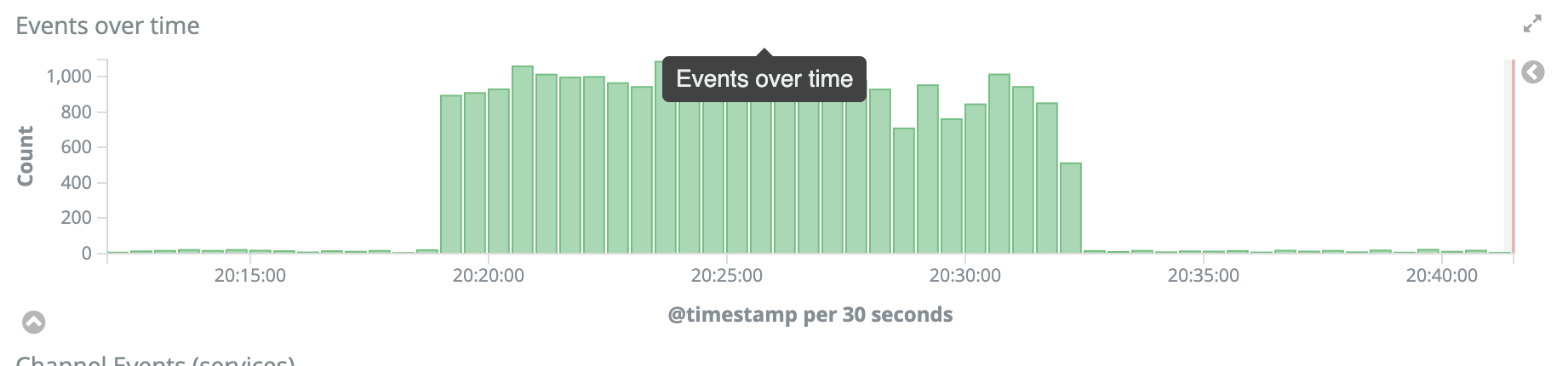
Impact
Spike in Varnish 5xx errors (~ 2k/min) following all-wiki promotion of 1.35.0-wmf.19.

Notes
Timeline from SAL:
20:33 marxarelli: rollback to group1 due to 500 spike (2k/min) (T233867) 20:32 dduvall@deploy1001: rebuilt and synchronized wikiversions files: (no justification provided) 20:30 marxarelli: varnish 500 spike. rolling back 20:20 gehel: restarting blazegraph + updater on wdqs2006 20:19 dduvall@deploy1001: rebuilt and synchronized wikiversions files: all wikis to 1.35.0-wmf.19