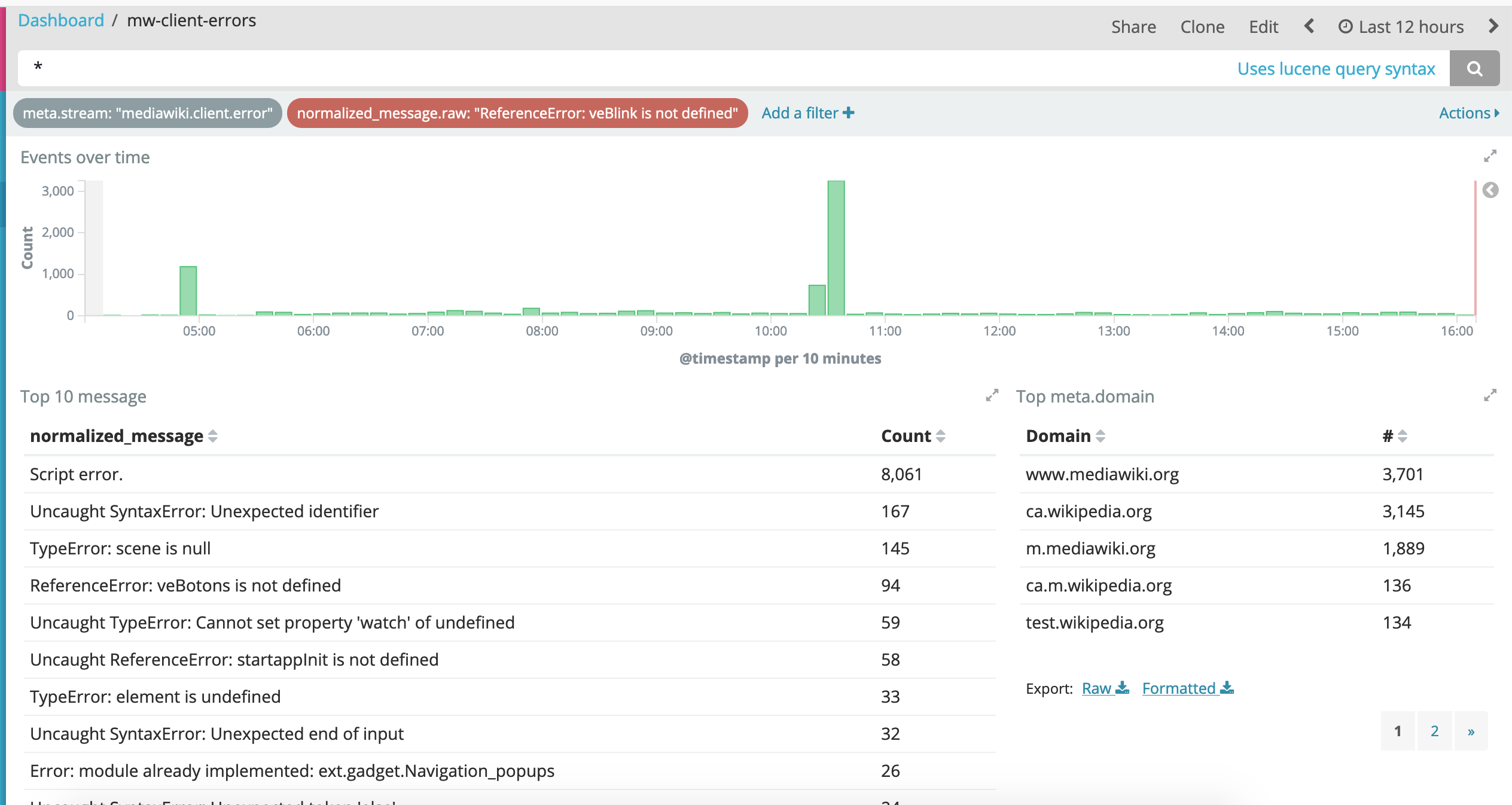
The rather unhelpful "Script Error" accounts for a large chunk of the errors recorded as client side errors. These come from scripts running on a different domain so possibly sourced via global gadgets or loaded across wiki. In the last 12 hrs, excluding 2 known errors which are being resolved, 90% of errors recorded to mediawiki.org and catalan wikipedia were reported with this unhelpful inactionable message.
https://logstash.wikimedia.org/goto/da15ba157025c9c1d8ab0041baff45cf