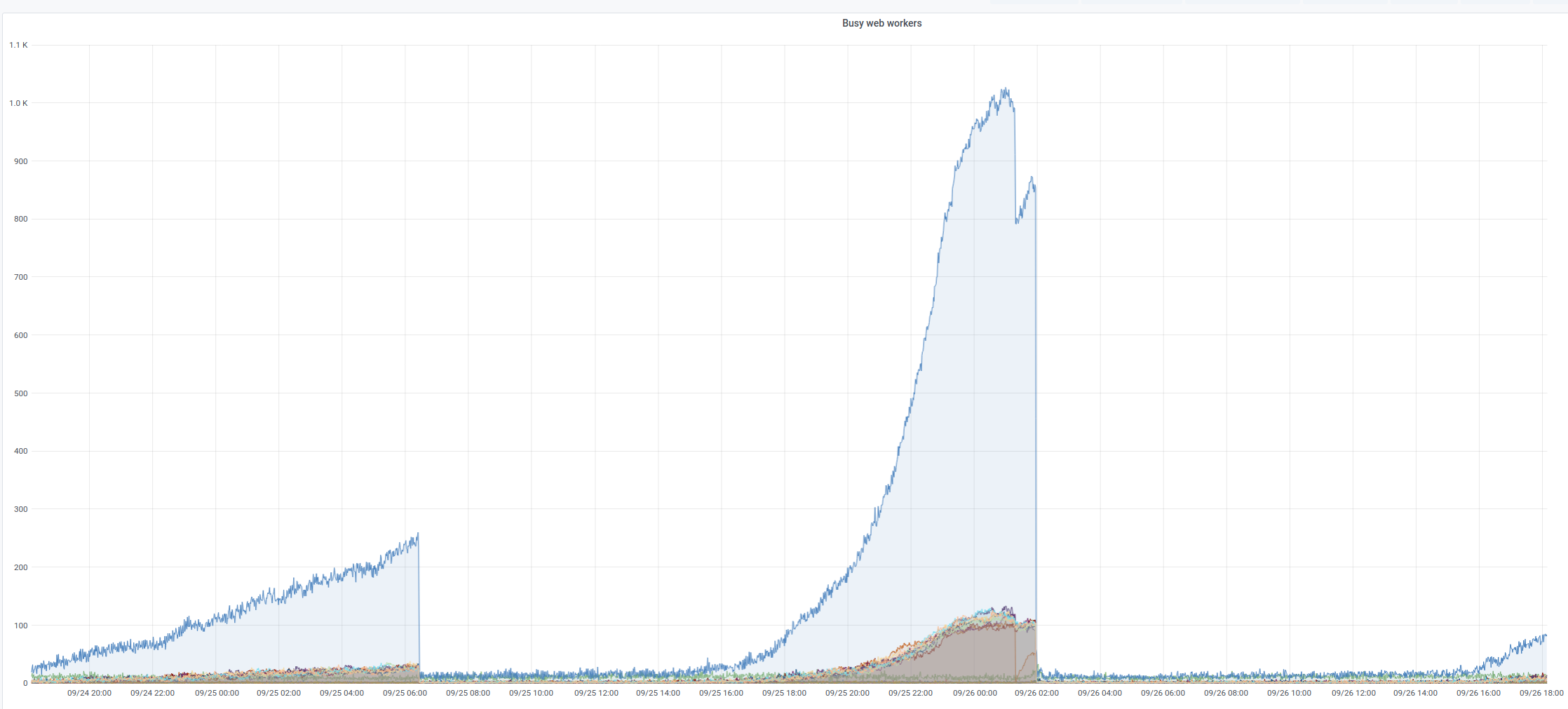
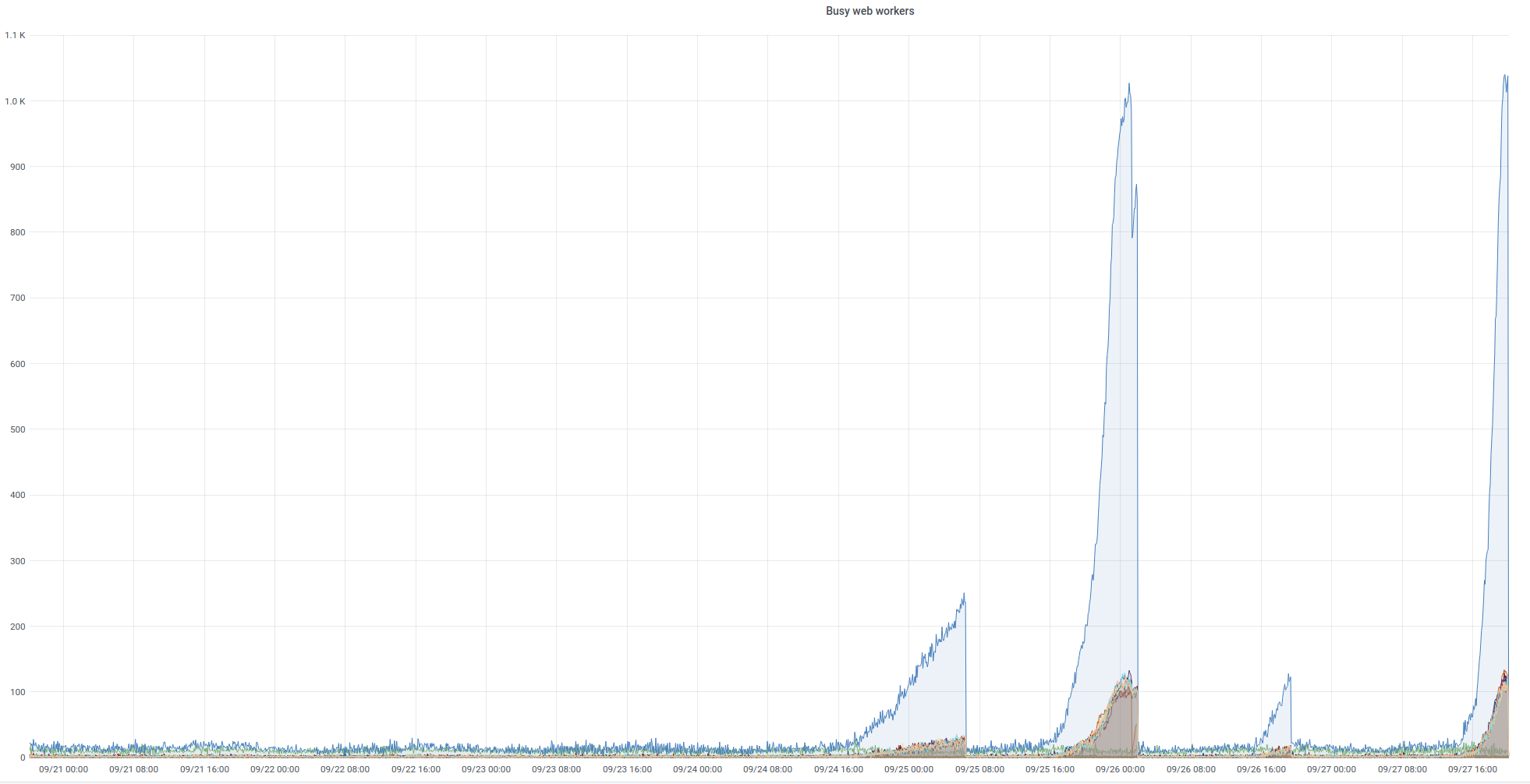
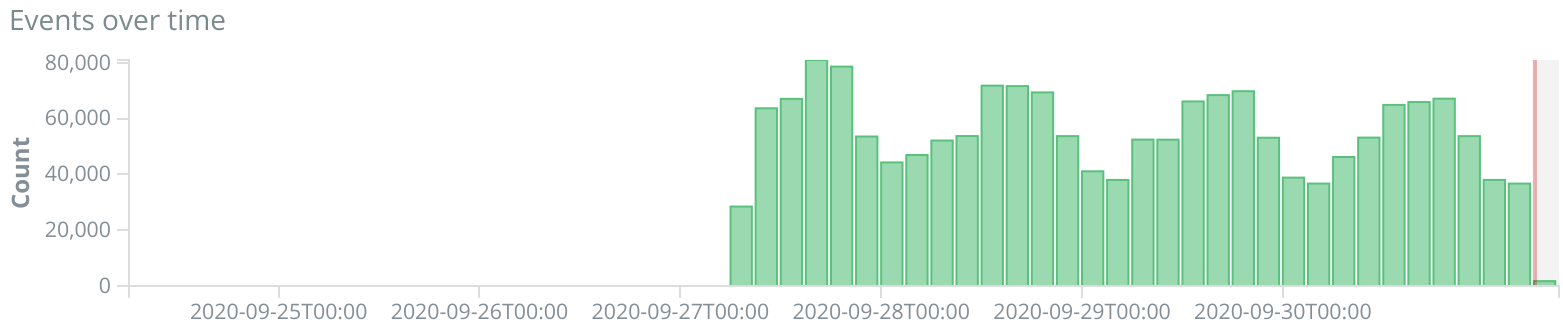
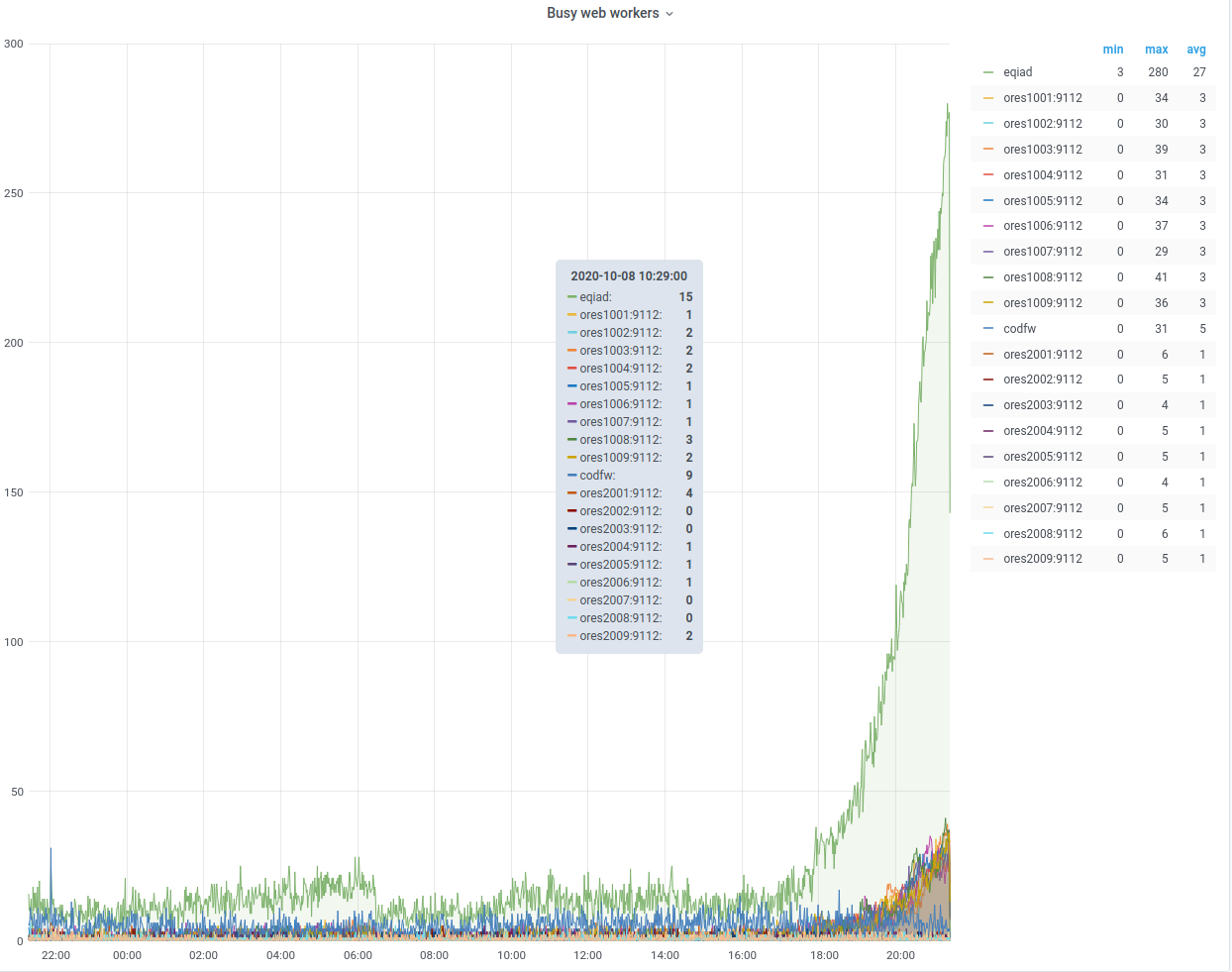
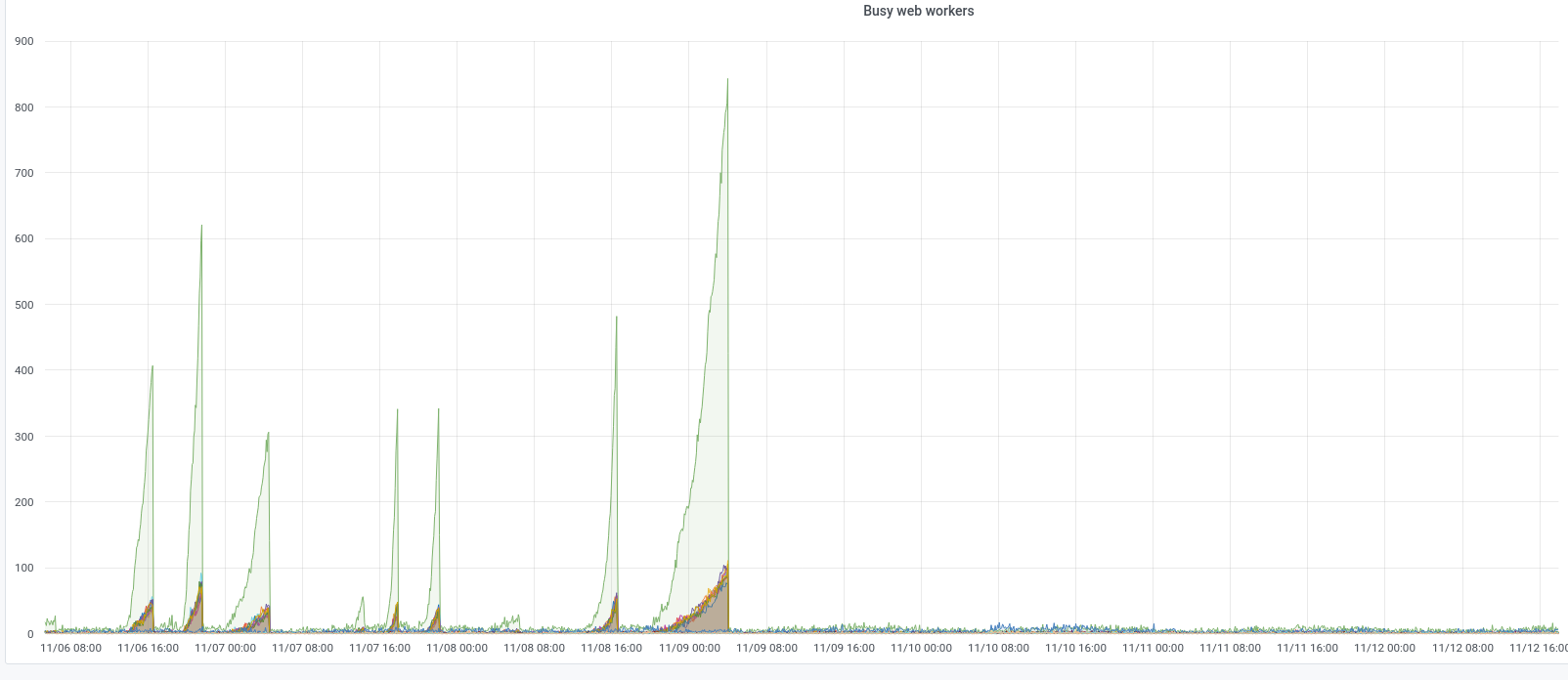
On Sept 26 ~ 01:05 UTC we found out that ores was erroring with redis complaining that max number of clients reached...
@CDanis restarted celery workers, and uwsgi and later depooled codfw and pooled eqiad. It appears this brought the service back.
https://grafana.wikimedia.org/d/HIRrxQ6mk/ores?orgId=1&from=1601066376291&to=1601089247711

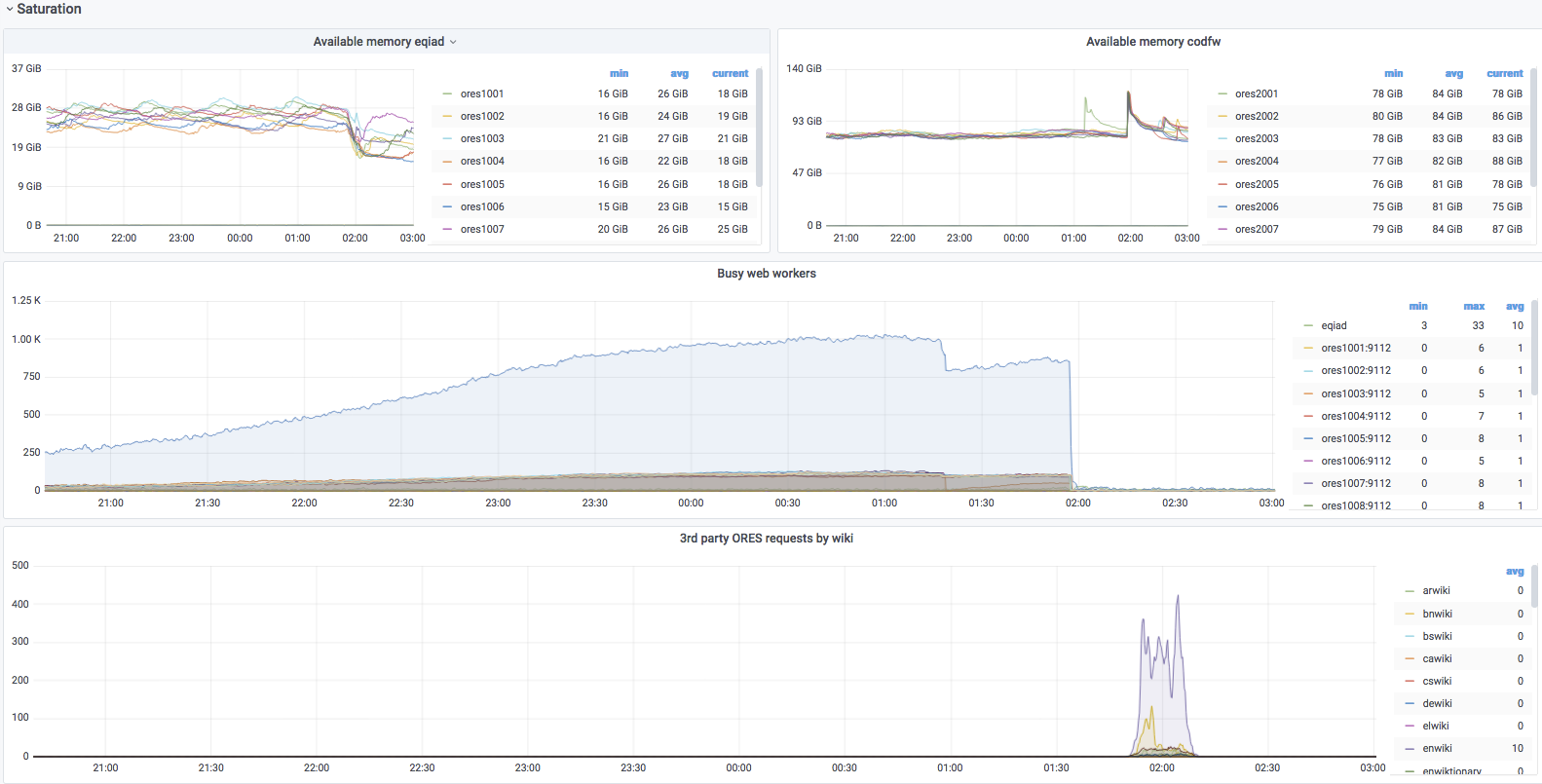
SAL:
02:04 cdanis@cumin2001: conftool action : set/pooled=false; selector: dnsdisc=ores,name=eqiad 02:04 cdanis@cumin2001: conftool action : set/pooled=true; selector: dnsdisc=ores,name=codfw 01:56 cdanis: ❌cdanis@cumin2001.codfw.wmnet ~ 🕙🍺 sudo cumin 'A:ores and A:codfw' 'systemctl restart celery-ores-worker.service uwsgi-ores.service ' 01:48 cdanis@cumin1001: conftool action : set/pooled=false; selector: dnsdisc=ores,name=codfw 01:48 cdanis@cumin1001: conftool action : set/pooled=true; selector: dnsdisc=ores,name=eqiad 01:17 cdanis: ❌cdanis@ores2001.codfw.wmnet ~ 🕤🍺 sudo systemctl restart uwsgi-ores.service 01:11 cdanis: ✔️ cdanis@ores2001.codfw.wmnet ~ 🕘🍺 sudo systemctl restart celery-ores-worker.service