List of steps to reproduce (step by step, including full links if applicable):
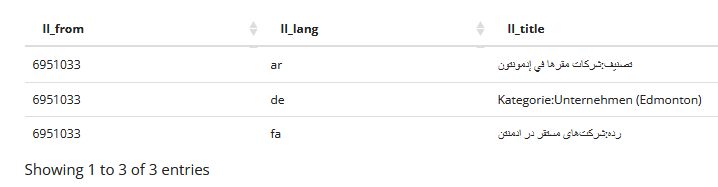
Here is a piece of python code that uses Pywikibot to query Wikidata and find which Persian Wikipedia page corresponds with the English Wikipedia page Category:Companies based in Edmonton
import pywikibot page = pywikibot.Page(pywikibot.Site('en'), 'Category:Companies based in Edmonton') print(page.langlinks())
What happens?:
Here is the response you get:
[pywikibot.page.Link('شركات مقرها في إدمونتون', APISite("ar", "wikipedia")), pywikibot.page.Link('Unternehmen (Edmonton)', APISite("de", "wikipedia")), pywikibot.page.Link('شرکت\u200cهای مستقر در ادمنتن', APISite("fa", "wikipedia"))]This indicates that the fa equivalent page would be titled "شرکتهای مستقر در ادمنتن" (don't be confused by \u200c which is the zero-width-non-joiner character)
What should have happened instead?:
Per the Wikidata page and as shown on the right side of the screenshot below, the expected answer would have been "شرکتهای ادمنتن" (more specifically, "رده:شرکتهای ادمنتن").
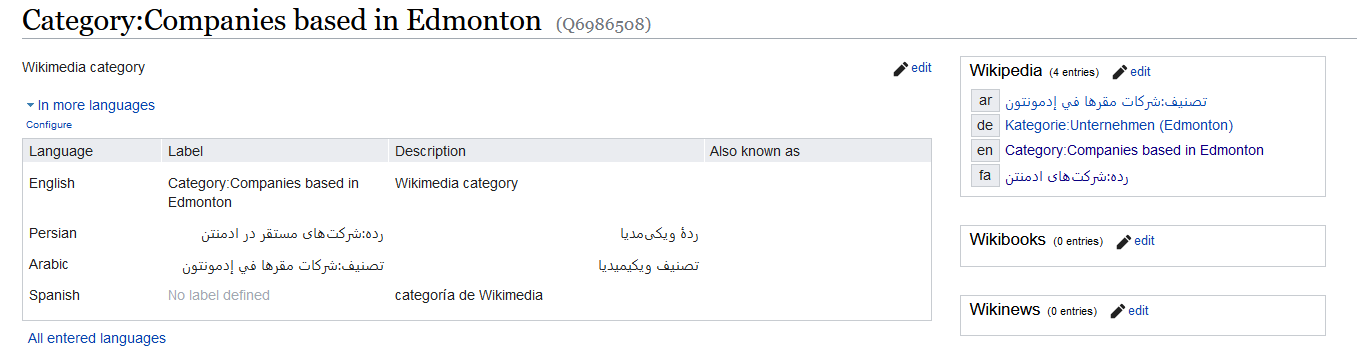
It seems like langlinks() is not returning the links, but rather the labels of the descriptions in different languages. Case in point, the namespace prefix is also missing in the responses. This contradicts what the function claims to do: "Return a list of all inter-language Links on this page"
Software version (if not a Wikimedia wiki), browser information, screenshots, other information, etc:
Tested on 05ce190809b