It has been showing 'latest edits may not currently be reflected in the tool' and is lagging behind almost 2 days.
Description
Description
| Status | Subtype | Assigned | Task | ||
|---|---|---|---|---|---|
| Resolved | jsn.sherman | T343104 Hashtags not reflecting new changes | |||
| Open | None | T361567 Identify bottlenecks in Hashtags tool data collection performance | |||
| Resolved | jsn.sherman | T361848 port wikilink events collection optimizations to hashtags collection script | |||
| Resolved | jsn.sherman | T361675 Stop tracking quickstatements in the Hashtags tool |
Event Timeline
There are a very large number of changes, so older changes are hidden. Show Older Changes
Comment Actions
Hi @Samwalton9. Yes it worked. But it's stuck again since August 4 (the day you made this comment)
Comment Actions
I am at Wikimania this week but will investigate next week. @Surlycyborg may have time to look into this in the meantime.
Comment Actions
A simple query like https://hashtags.wmcloud.org/?query=proveit can reproduce this. Right now I don't see any edits post August 4th.
Running locally, I am able to fetch edits from later than that, which leads me to suspect something is wrong in production.
I also don't see errors in the developer console for the URL above, so I think it's not very likely to be a client-side issue.
Sam, maybe you can check the status of the scripts container in production please?
Comment Actions
Thanks for confirming. I found time to take a look at the issue is pretty clear-cut:
mysql.connector.errors.DatabaseError: 1114 (HY000): The table 'hashtags_hashtag' is full
Comment Actions
I don't have time to backup/recreate a new instance with more disk space until next week. In the meantime I deleted an old backup freeing up a small amount of space, and restarted the scripts container, which means things should start catching up a little.
Comment Actions
Hi, thanks for identifying the cause and the temporary fix! Just to keep you updated, now it seems the tool has stopped recording changes since August 18, cheers!
Comment Actions
The hashtag tool seems not to be updating. The last update was on the 20th of August. Please look into this too.Thank you.
Comment Actions
So the best solution might be to attach a new volume to the Cloud instance, and store the database there (if such a thing is possible) but that goes beyond my current abilities, and I'd rather not have to drag our team's engineers into working on this. An alternative option would be to trim the database a little. The current top hashtag is flickr2commons (2.7 million entries; 38% of database rows). The tool already times out if you try to load a search for flickr2commons, and flickr2commons edits can be easily tracked via tags since they're only happening on Wikimedia Commons.
Given this, I think I'm going to delete all current flickr2commons database rows and exclude flickr2commons from tracking. This frees up nearly 40% of database capacity, giving us a lot more breathing room for a better solution in the future.
Comment Actions
Added flickr2commons to the hashtags exclusion list. We'll give this a week or so and see if we've caught up.
Because I was having some issues with disk space and backups I also added a new volume for backups, which is located at /backups
Comment Actions
Looks like this is resolved, though the flickr2commons exclusion didn't go through for some reason. I'll look into that soon.
Comment Actions
Hi @Samwalton9-WMF, we've used the Hashtag tool for one of WMCZ's competitions and we are just trying to pick winners. We found out that some edits were not detected by the tool until now. Please see the query and list of some manually picked examples of not detected edits below. Is there anything we can do about it?
- 8. 8. 2023, 01:15 KKDAII https://cs.wikipedia.org/w/index.php?title=Babi%C4%8Dky_(Babice)&action=history
- 8. 8. 2023, 19:26 KKDAII https://cs.wikipedia.org/w/index.php?title=Buda_(Muka%C5%99ov)&action=history
- 8. 8. 2023, 19:10 KKDAII https://cs.wikipedia.org/w/index.php?title=Brusy_(Lib%C4%9Bdice)&action=history
- 7. 8. 2023, 22:03 KKDAII https://cs.wikipedia.org/w/index.php?title=Vi%C5%A1%C5%88ovka&action=history
Comment Actions
Thank you Sam for the fix.
This issue actually affected everyone and for even longer period. The data seem to be missing for almost four days. I have filed T346206 to track that separately since this one effectively resolved the main issue of failing continuous update.
Comment Actions
Hi! The hashtags tool seems to have stopped recording changes again, since December 11. See for example https://hashtags.wmcloud.org/?query=proveit
Comment Actions
Apologies for the delay on this, I've been busy and this tool isn't one I'm particularly well suited to maintain at the moment. I'm seeing lots of this in the scripts container log:
Traceback (most recent call last):
File "/scripts/scripts/collect_hashtags.py", line 144, in <module>
hashtag_matches = hashtag_match(change['comment'])
KeyError: 'comment'Not immediately obvious to me why this would be. Maybe 'comment' data isn't sent for stream events with no edit summary anymore. Looks like we have data up to 11th December, then a little on the 15th and 20th, perhaps small gaps where there were edits which all had edit summaries. Trying a hotfix.
Comment Actions
It doesn't help that I can't rebuild the app because of insufficient disk space. That was going to come back to bite us one way or another so this probably warrants a better fix.
Comment Actions
The disk space issue (T355176) is resolved.
This is also resolved courtesy of a quick hotfix to check for comment in the response data.
SELECT COUNT(*) as cnt, DATE(timestamp) FROM hashtags_hashtag WHERE timestamp > '2023-12-01' GROUP BY DATE(timestamp) ORDER BY DATE(timestamp) ASC; +------+-----------------+ | cnt | DATE(timestamp) | +------+-----------------+ | 2413 | 2023-12-01 | | 1882 | 2023-12-02 | | 3010 | 2023-12-03 | | 3591 | 2023-12-04 | | 2918 | 2023-12-05 | | 3005 | 2023-12-06 | | 2792 | 2023-12-07 | | 2489 | 2023-12-08 | | 2900 | 2023-12-09 | | 1830 | 2023-12-10 | | 1832 | 2023-12-11 | | 5 | 2023-12-15 | | 97 | 2023-12-20 | | 37 | 2024-01-10 | +------+-----------------+
Data is now collecting from the 10th January and will gradually catch up to recording live data again.
Comment Actions
Thanks for looking into this! However, I'm currently getting a 502 Bad Gateway error.
Comment Actions
Hm, yep, seeing that.
No errors in the app container, but the nginx container is showing connection refused. We'll look into it.
Comment Actions
This seems to still be on a happy journey back to being up to date:
+------+-----------------+ | cnt | DATE(timestamp) | +------+-----------------+ | 2413 | 2023-12-01 | | 1882 | 2023-12-02 | | 3010 | 2023-12-03 | | 3591 | 2023-12-04 | | 2918 | 2023-12-05 | | 3005 | 2023-12-06 | | 2792 | 2023-12-07 | | 2489 | 2023-12-08 | | 2900 | 2023-12-09 | | 1830 | 2023-12-10 | | 1832 | 2023-12-11 | | 5 | 2023-12-15 | | 97 | 2023-12-20 | | 253 | 2024-01-10 | | 526 | 2024-01-11 | | 1142 | 2024-01-12 | | 1813 | 2024-01-13 | | 324 | 2024-01-14 | +------+-----------------+
It looks like data from the 10th and 11th may be incomplete - the event streams only officially have 7 days of historical data so this would make sense. Data should be complete from the 12th onwards.
Comment Actions
I added the #1Lib1Ref hashtag in multiple edits of mine for a competition that's currently taking place on the Czech Wikipedia, but my edits (with the first edit made on Jan 18) aren't showing up in the list. Apparently, I am not the only user whose edits aren't showing up as they should (see here). I was advised by Janbery to let you know.
Comment Actions
The data collection process is still catching up to live data - we're currently collecting data for the 18th January:
| 1813 | 2024-01-13 | | 1138 | 2024-01-14 | | 2673 | 2024-01-15 | | 3081 | 2024-01-16 | | 2105 | 2024-01-17 | | 83 | 2024-01-18 | +------+-----------------+
Comparing to above, we've moved up 4 days in a bit less than 3, so by my estimate we should catch up to live data around the start of February if this pace keeps up. I don't remember it being quite this slow in the past but it is what it is. Either way all the data from Jan 18 should be in the tool by the end of today.
Comment Actions
Hi! Thanks for fixing it, but it seems like its broken again, since January 28. Cheers!
Comment Actions
@Samwalton9-WMF Ah, I see you've unassigned yourself from this task. Does that mean we should find someone else to fix this?
Comment Actions
@Sophivorus I checked the server and it is still processing events, I believe that it simply has not finished catching up. It is almost done with 2024-01-28. Take any time estimate to catch up with a grain of salt: the volume of events that need processed can vary greatly over time.
Comment Actions
@jsn.sherman in ballpark figures in a week it recovered a day, during what I suspect is peak usage. Maybe it makes sense to give a few more resources to the process, at least while recovering from an outage?
Comment Actions
| 5144 | 2024-01-28 | | 4169 | 2024-01-29 | | 4429 | 2024-01-30 | | 1442 | 2024-01-31 | +------+-----------------+
We're at yesterday's data now so I don't think it's worth our while to put effort into increasing resources here right now :)
Comment Actions
As of Mon Feb 5 18:08:21 UTC 2024, the system was at Mon Feb 5 16:10:31 UTC 2024. With less than 2 hours of lag, I think we can consider this resolved.
Comment Actions
It took about two weeks for data to be synchronous with the current date last time.
I'm sure the tool used to be faster than this in the past, so I'm not sure what the bottleneck is.
Comment Actions

I didn't know if that was expected since this system uses a different method of deploying containers from our other servers
I noticed both on the first stoppage and this one that system load is pretty low on the server:

I didn't know if that was expected since this system uses a different method of deploying containers from our other servers
Comment Actions
@Samwalton9 I just checked in on the the database, and we're not catching up yet. It looks like we're gaining 10 seconds about every 10 minutes.
| system time | latest timestamp |
| Wed Feb 28 17:36:23 UTC 2024 | 2024-02-20 23:25:41.000000 |
| Wed Feb 28 17:38:33 UTC 2024 | 2024-02-20 23:25:45.000000 |
| Wed Feb 28 17:38:47 UTC 2024 | 2024-02-20 23:25:47.000000 |
| Wed Feb 28 17:42:56 UTC 2024 | 2024-02-20 23:25:47.000000 |
| Wed Feb 28 17:45:49 UTC 2024 | 2024-02-20 23:25:51.000000 |
Comment Actions
Hm, not ideal. We've only introduced one trivial additional check, so I don't know why that would have slowed things down so much.
Comment Actions
I just checked in on it, and it looks like progress was made overnight:
| system time | latest timestamp |
| Thu Feb 29 12:36:13 UTC 2024 | 2024-02-23 04:38:05.000000 |
Comment Actions
progress update: it looks like we're running at about 1.89x real time; e.g. we're catching up.
| system time | latest timestamp |
| Fri Mar 1 17:26:37 UTC 2024 | 2024-02-24 17:56:35.000000 |
That makes the current gap:
5 days 23 hours 30 minutes
(or ~143 hours)
once we were back, we were here:
| system time | latest timestamp |
| Wed Feb 28 17:36:23 UTC 2024 | 2024-02-20 23:25:41.000000 |
which was a gap of:
7 days 18 hours 11 minutes 0 second
(or ~186 hours)
That means we've reduced the gap by 43 hours between the first and last check
The time between the checks was 1 days 23 hours 50 minutes
(or ~48 hours)
That puts our overal average at about 1.89x real time since the first check mentioned here.
Comment Actions
I just checked in on it, and it looks like the gap widened again:
| system time | latest timestamp |
| Mon Mar 4 14:16:05 UTC 2024 | 2024-02-29 19:09:49.000000 |
It's back up to 5 days 19 hours 7 minutes
The script container has been running and logging, so things are working on a system level. System load is really low. Uptime shows 46 days, 22:45. I'm restarting the server as a basic troubleshooting step that does not require understanding the problem.

Comment Actions
I just checked in on it, and it looks like the gap narrowed again after the restart:
| system time | latest timestamp |
| Tue Mar 5 17:52:24 UTC 2024 | 2024-03-02 23:58:08.000000 |
It's currently 2 days 17 hours 54 minutes
I'll continue monitoring it.
Comment Actions
Tool is no longer displaying a data notice and data is within 1 minute of the live time.
Comment Actions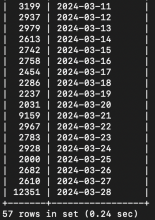
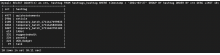
Hmm. The scripts container is still happy. We seem to have an inordinately large number of edits tracked on 28th March.
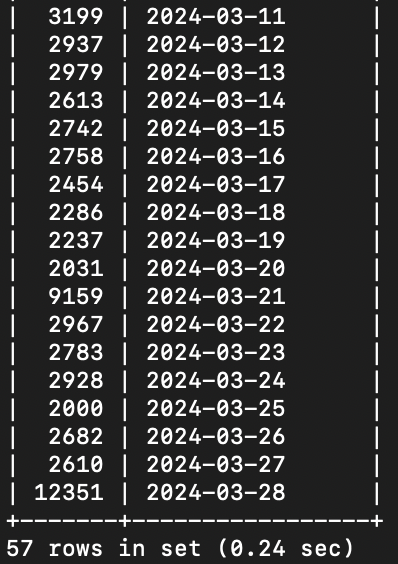
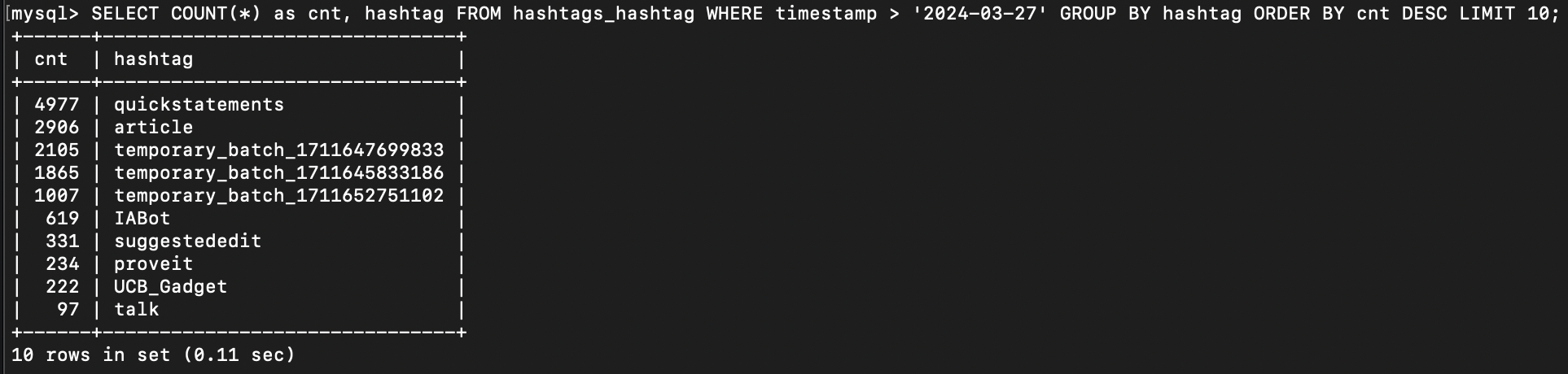
Seems to mostly be Quickstatements
Data capture is continuing, it's just very slow. We may need to prioritise some work to understand what the bottleneck is.