@kevinbazira this is very helpful, thank you!
Feed Advanced Search
Mar 11 2024
Mar 11 2024
MunizaA added a comment to T355742: Assess runtime performance impact of pydantic data models in the RRLA model-server.
Jan 18 2024
Jan 18 2024
MunizaA added a comment to T352839: RevertRisk model readiness for temporary accounts.
Nov 16 2023
Nov 16 2023
MunizaA closed T350389: Upgrade xgboost in knowledge_integrity, a subtask of T349844: Increased latencies with Kserve 0.11.1 (cgroups v2), as Resolved.
MunizaA added a comment to T350389: Upgrade xgboost in knowledge_integrity.
Knowledge Integrity v0.5.0 has been released which now depends on xgboost 2.x. Upgrading xgboost also required serializing the classifier with the new version so the version for RevertRiskModel has also been bumped to v3. I've shared the model file with @achou. The SHA512 sum for RevertRiskModel v3 is:
fb6d76b105b7e8198cee47f779c69f1bd85be61075061665bdd0811e8d52e1d4f793dacb4a00fc3776ace8c518f1fa5f653879cec81777854cf235b0483156e7 *revert_risk_language_agnostic_model_v3.pkl
Going to resolve this now but please feel free to reopen if something does not look right!
Nov 8 2023
Nov 8 2023
MunizaA added a comment to T350389: Upgrade xgboost in knowledge_integrity.
Hi, I've opened an MR for dropping support for Python 3.7 in KI since this was already on the roadmap after its EOL in June 2023 and it also helps support this change (xgboost 2.x requires minimum Python 3.8).
Oct 31 2023
Oct 31 2023
MunizaA added a comment to T350061: [Annotool] Errors loading edits.
@diego, looking at the revisions in this project I see that the wiki_db is wikidatawiki when it should be wikidata. Can you try fixing the wiki and importing again?
Oct 16 2023
Oct 16 2023
MunizaA updated the task description for T348822: Choose vector search framework.
Oct 2 2023
Oct 2 2023
MunizaA updated the task description for T347330: Expand language support for Revert Risk Model.
Sep 29 2023
Sep 29 2023
MunizaA updated the task description for T347330: Expand language support for Revert Risk Model.
Sep 27 2023
Sep 27 2023
MunizaA updated the task description for T347330: Expand language support for Revert Risk Model.
Sep 26 2023
Sep 26 2023
MunizaA added a comment to T347330: Expand language support for Revert Risk Model.
@diego, it's possible I'm missing something but while updating these constants I noticed that the values for be-x-old and be-tarask are different and according to the information here, the former redirects to the latter. be-tarask is one of the new wikis that we're adding these values for, so I wanted to check with you if this is okay. Thanks!
MunizaA updated the task description for T347330: Expand language support for Revert Risk Model.
Sep 25 2023
Sep 25 2023
MunizaA moved T347330: Expand language support for Revert Risk Model from Backlog to In Progress on the Research board.
MunizaA set Due Date to Sep 28 2023, 7:00 AM on T347330: Expand language support for Revert Risk Model.
MunizaA changed the status of T347330: Expand language support for Revert Risk Model from Open to In Progress.
Sep 5 2023
Sep 5 2023
MunizaA moved T344613: Improve knowledge gap project setup from Staged to In Progress on the Research board.
Aug 30 2023
Aug 30 2023
MunizaA added a comment to T343064: Expand types of edits for Wikidata revert risk model.
Hi @Miriam, I'll need some more time to work on this. I did some initial exploration here but then had to pause to work on Annotool bug fixes and improvements, which is the tool currently being used to collect annotations for this model. Thank you!
Aug 21 2023
Aug 21 2023
MunizaA closed T344152: Allow users to edit annotations in Annotool, a subtask of T344016: Improvements to Annotool, as Resolved.
Aug 14 2023
Aug 14 2023
MunizaA moved T344152: Allow users to edit annotations in Annotool from FY2023-24-Research-July-September to In Progress on the Research board.
MunizaA added a comment to T343973: Fix relative links for Qids in Annotool.
Hi @wolfgang8741, I deployed a patch Friday that fixes this but if you're still running into it, please let me know. Thanks!
MunizaA added a comment to T341820: Evaluate and improve the Revert Risk model for Wikidata..
Hi @Danny_Benjafield_WMDE, thanks for the feedback!
Jul 28 2023
Jul 28 2023
MunizaA added a comment to T340811: Index out of range in revert risk multi-lingual.
I rewrote some parts of RRML earlier this week to replace StructuredEditTypes with SimpleEditTypes in this MR, using pointers from your comments above. The changes are still being tested by @Trokhymovych, the original author of this code, to make sure there isn't a significant drift in the predictions made by the model
Jul 21 2023
Jul 21 2023
MunizaA added a comment to T340811: Index out of range in revert risk multi-lingual.
I managed to separate the headers from sections in the code so it's much cleaner now and seems to run fine for your list of revisions with timeout set to True.
@Isaac that's awesome, thank you!
Jul 14 2023
Jul 14 2023
MunizaA added a comment to T340811: Index out of range in revert risk multi-lingual.
@Isaac thanks so much for the pointers! It seems like this model is also using node edit info for some of the features but in any case, we should be able to simplify the text diffing code using functionality from mwedittypes.
MunizaA added a comment to T340811: Index out of range in revert risk multi-lingual.
Hi @elukey, the dependency contraint we have for mwedittypes in KI is "1.2.1" so unfortunately this new version is not a drop-in replacement. There are some minor API changes but more importantly, the diff processing code in get_edit_info will have to be modified in order to adapt to this new version. I can look into making these modifications but looking at the changelog for mwedittypes, it seems like there have also been some changes to how certain types of edits are captured since v1.2.1 and I'm not sure how this would impact the performance of the model so I'm discussing these changes with @Trokhymovych and will make the switch as soon as we're sure about its impact.
Feb 22 2023
Feb 22 2023
MunizaA updated the task description for T330148: Support the Revert-Review API/tool on Toolforge.
Jan 24 2023
Jan 24 2023
MunizaA added a comment to T323107: [M] Upgrade code base to Spark 3.
@xcollazo I think the reason why Spark2 does not push this filter down is because it does not infer filters from generators as the optimizer rule InferFiltersFromGenerate in Spark 3.1.2 does not seem to exist in Spark 2.4.4
Jan 20 2023
Jan 20 2023
MunizaA added a comment to T323107: [M] Upgrade code base to Spark 3.
I looked into this a little because I wasn't sure why Spark was pushing down the parse UDF. Looking at the query plan for Spark 3, I think what's happening is that because the job does an explode on the UDF's result, Spark pushes down the UDF to filter out any rows with nulls or empty arrays early:
Dec 19 2022
Dec 19 2022
Dec 5 2022
Dec 5 2022
MunizaA added a comment to T323613: Test MultilingualRevertRiskModel inference service on ml-sandbox.
This is also related to T323023 but could it be that since we're sharing a client session between requests, the host header is not getting updated correctly? Maybe we should also log successful request responses to see that we're getting the right language back? For example, all of the above revisions exist in de wikipedia except for the en ones and if I query for those I get 'badrevids'.
Nov 2 2022
Nov 2 2022
MunizaA added a comment to T321594: Deploy revert-risk-model to production.
Thanks a lot for sharing these results here, @achou! I do see that we're seeing more socket connect errors with increased connections. Is that something we should be concerned about? Wrk docs don't seem to say anything about these errors but some issues on the repo mention that connect errors in particular can also occur when wrk runs out of file descriptors but they also report opening hundreds of connections so not sure if that's the case here.
Aug 4 2022
Aug 4 2022
Apr 26 2022
Apr 26 2022
MunizaA added a comment to T293511: Expand section aligment to more languages, and share dumps.
Apr 3 2022
Apr 3 2022
MunizaA added a comment to T293511: Expand section aligment to more languages, and share dumps.
The following results include the top 100 language pairs by number of section pairs tested. The precision here denotes the probability that, of all the aligned target sections for a source section in our extracted data, the cx dataset translation was among the top 5. Please note that any source sections occurring more than once per (source language, target language) in the cx dataset were counted as one pair and tested by checking if any of the corresponding targets ended up among the top 5.
Jan 12 2022
Jan 12 2022
MunizaA added a comment to T293511: Expand section aligment to more languages, and share dumps.
In order to assess the accuracy of our current language model, we tried to replicate the experiment that @diego had run with the FastText embeddings. This involved training a classifier on a portion of the ground truth and then using it to predict the similarity of the remaining section pairs in the ground truth. More specifically, we took our previously generated set of all possible section pairs for the 6 languages used in this experiment and for each pair extracted a bunch of features that describe that pair (the number of times the two sections in it occur together, how similar the links that they contain are on average etc.) which happen to be a subset of the features that Diego used. We then labelled all pairs that are found in the ground truth as 'True' and the rest as 'False'. A classifier using gradient boosting was trained on a portion of this data and was then used to classify the rest of it. We then dense ranked the results from this classifier to evaluate the probability of a pair from the ground truth ending up in the top 5 (precision @ 5).
The results from this experiment came out to be comparable to the previously documented ones. This means that we can use a multilingual model in place of FastText which is monolingual (meaning that while similar words within a language share similar vectors, translation words from different languages do not do so) eliminating the need to align vectors from two languages in a single vector space before they can be compared and expect similar results.
The following image depicts the results from the experiment mentioned above. Empty boxes in the chart represent cases where we didn't have enough ground truth.
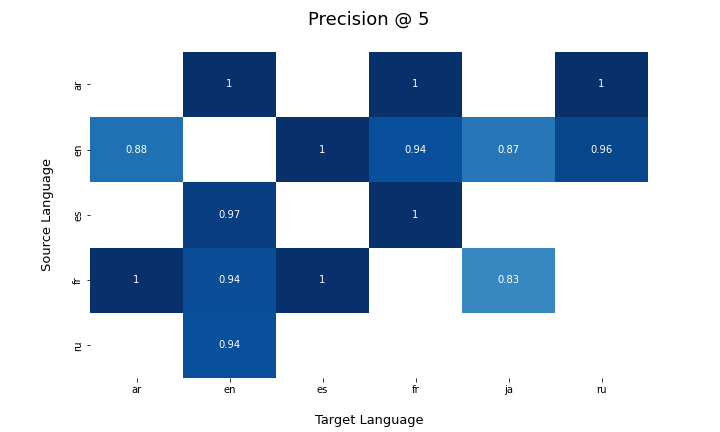
Dec 6 2021
Dec 6 2021
MunizaA added a comment to T293511: Expand section aligment to more languages, and share dumps.
We experimented with multiple pre-trained models from sentence-transformers to find a multilingual model that can accurately and efficiently encode section headings. We've found that paraphrase-xlm-r-multilingual-v1 provides the most accurate and consistent results across multiple languages for our use case. It maps sentences to a 768 dimensional shared vector space and the resulting vectors can then be used to calculate cosine similarity between co-occurring sections.
The following results were obtained by running the same model evaluation experiments for different language pairs. We evaluate models by first aligning articles in two languages using their wikidata id. We then take the sections from those aligned articles and generate all possible combinations. The selected model is then used to encode these section pairs and calculate their similarity. We then rank these pairs by similarity for each section and check the rank of the true section translation (the one that's in our dataset). Note that these results only contain language pairs for which we had more than 20 records in our dataset.
Oct 13 2021
Oct 13 2021
MunizaA added a comment to T292955: Requesting access to Analytic Cluster for Muniza.
MunizaA added a comment to T292955: Requesting access to Analytic Cluster for Muniza.
@CDanis I've signed it now. Thanks!
Oct 12 2021
Oct 12 2021
MunizaA updated the task description for T292955: Requesting access to Analytic Cluster for Muniza.
Mar 31 2021
Mar 31 2021