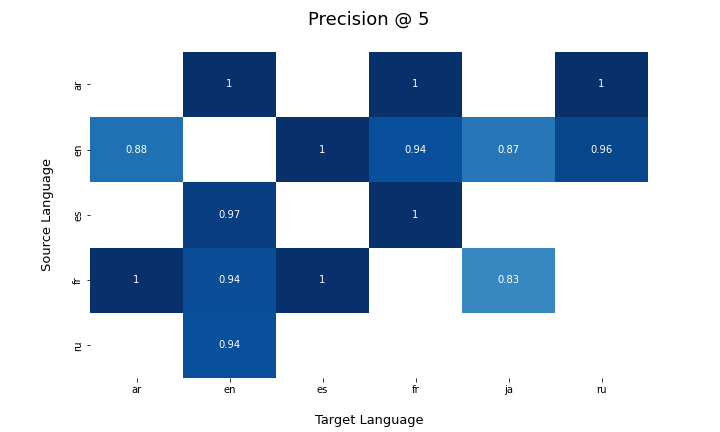
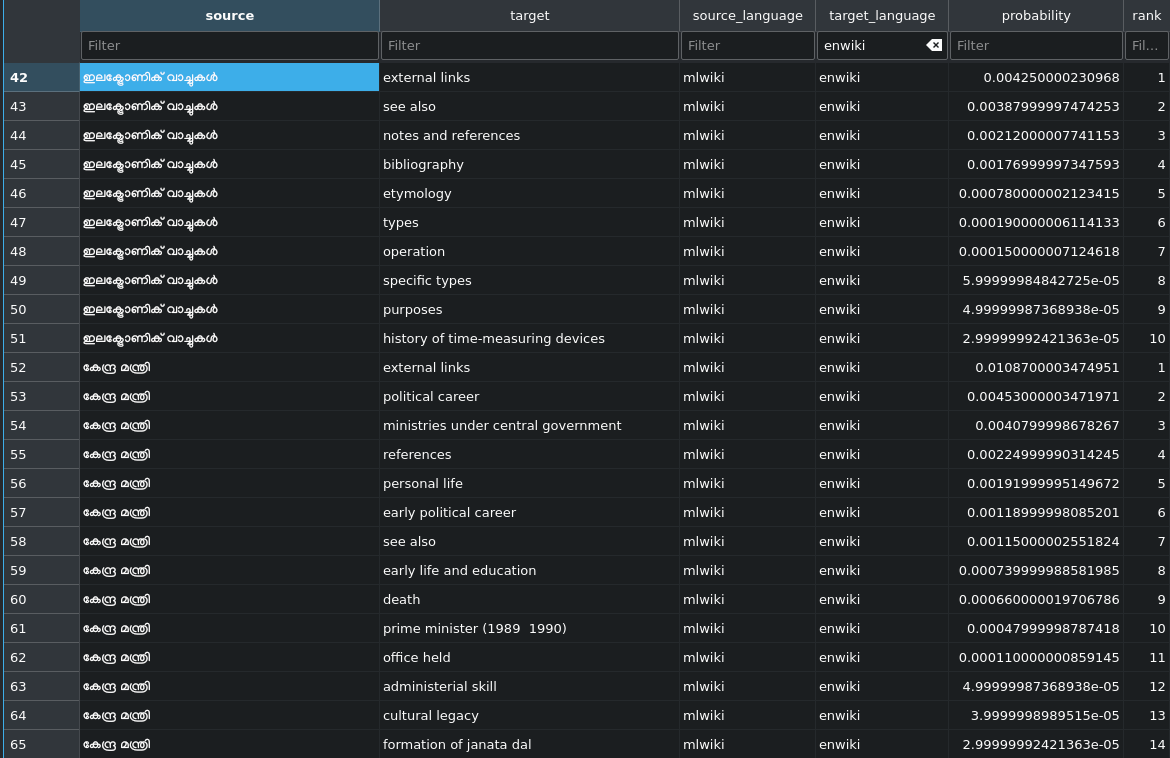
The goal of this task is to expand the existing section alignment prototype, creating alignments in more languages and share this DB with language team.
- Hire and onboard a contractor.
- Move the existing code to the PySpark.
- Explore new cross-lingual embeddings system that help to escalate to more languages in a more efficient way.
- Share DB with the Language team.
Update: The language team prefers to receive the alignments as dumps, to incorporate this on their pipelines instead of separated API.