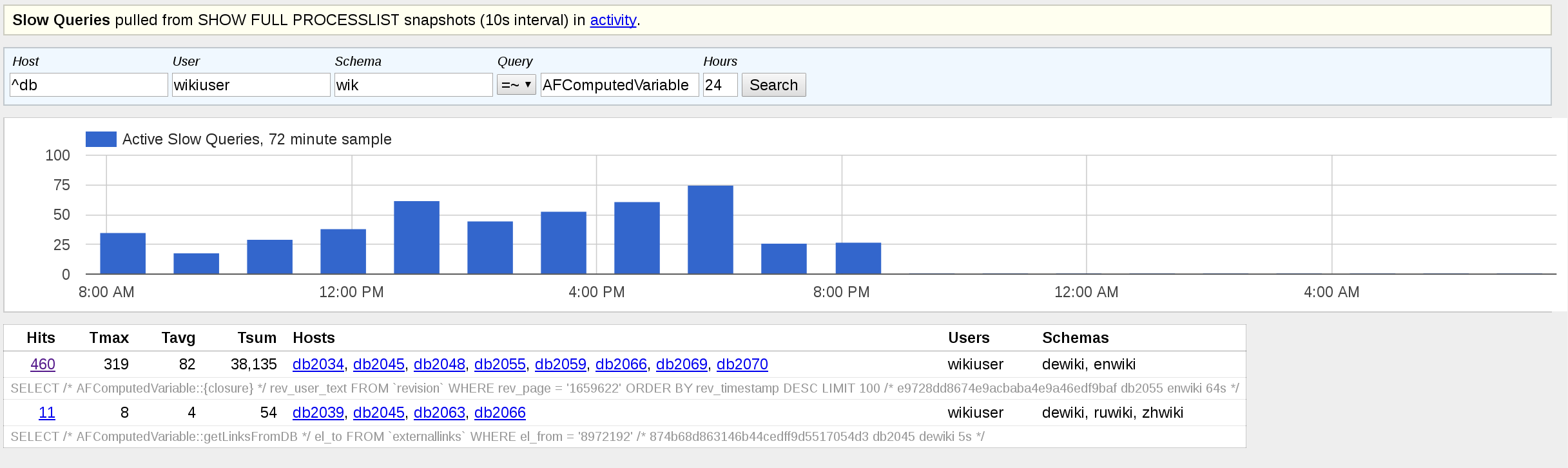
Lots of these in the logs at https://logstash.wikimedia.org/#/dashboard/elasticsearch/wfLogDBError:
AFComputedVariable::compute 10.64.32.21 2013 Lost connection to MySQL server during query (10.64.32.21) SELECT rev_user_text FROM (SELECT rev_user_text,rev_timestamp FROM `revision` WHERE rev_page = '8972734' AND (rev_timestamp < '20151025233104') ORDER BY rev_timestamp DESC LIMIT 100 ) AS tmp GROUP BY rev_user_text ORDER BY MAX(rev_timestamp) DESC LIMIT 10
Seems to affect the enwiki API DBs (not sure if that is page/traffic pattern or something with those DBs). The query plan on those looks similar to other servers *except* for the index "key length" used and ref vs range scans. The ones with less errors say 4 (vs 20 for the API ones).
> aaron@terbium:~$ mwscript sql.php --wiki=enwiki --slave=db1065
> EXPLAIN SELECT rev_user_text FROM (SELECT rev_user_text,rev_timestamp FROM `revision` WHERE rev_page = '36395484' AND (rev_timestamp < '20151025072035') ORDER BY rev_timestamp DESC LIMIT 100 ) AS tmp GROUP BY rev_user_text ORDER BY MAX(rev_timestamp) DESC LIMIT 10;
stdClass Object
(
[id] => 1
[select_type] => PRIMARY
[table] => <derived2>
[type] => ALL
[possible_keys] =>
[key] =>
[key_len] =>
[ref] =>
[rows] => 100
[Extra] => Using temporary; Using filesort
)
stdClass Object
(
[id] => 2
[select_type] => DERIVED
[table] => revision
[type] => range
[possible_keys] => rev_page_id,rev_timestamp,page_timestamp
[key] => page_timestamp
[key_len] => 20
[ref] =>
[rows] => 173152
[Extra] => Using where
)> aaron@terbium:~$ mwscript sql.php --wiki=enwiki --slave=db1073
> EXPLAIN SELECT rev_user_text FROM (SELECT rev_user_text,rev_timestamp FROM `revision` WHERE rev_page = '36395484' AND (rev_timestamp < '20151025072035') ORDER BY rev_timestamp DESC LIMIT 100 ) AS tmp GROUP BY rev_user_text ORDER BY MAX(rev_timestamp) DESC LIMIT 10;
stdClass Object
(
[id] => 1
[select_type] => PRIMARY
[table] => <derived2>
[type] => ALL
[possible_keys] =>
[key] =>
[key_len] =>
[ref] =>
[rows] => 100
[Extra] => Using temporary; Using filesort
)
stdClass Object
(
[id] => 2
[select_type] => DERIVED
[table] => revision
[type] => ref
[possible_keys] => rev_page_id,rev_timestamp,page_timestamp
[key] => page_timestamp
[key_len] => 4
[ref] => const
[rows] => 189680
[Extra] => Using where
)