From #wikimedia-operations
04:24 < icinga-wm> PROBLEM - MediaWiki exceptions and fatals per minute on graphite1001 is CRITICAL: CRITICAL: 90.00% of data above the critical threshold [50.0] https://grafana.wikimedia.org/dashboard/db/mediawiki-graphite-alerts?orgId=1&panelId=2&fullscreen 04:24 < icinga-wm> PROBLEM - MariaDB Slave Lag: s8 on db2085 is CRITICAL: CRITICAL slave_sql_lag Replication lag: 604.57 seconds 04:24 < icinga-wm> PROBLEM - MariaDB Slave Lag: s8 on db1099 is CRITICAL: CRITICAL slave_sql_lag Replication lag: 623.85 seconds 04:24 < icinga-wm> PROBLEM - MariaDB Slave Lag: s8 on db2086 is CRITICAL: CRITICAL slave_sql_lag Replication lag: 628.36 seconds 05:18 < icinga-wm> PROBLEM - High lag on wdqs1005 is CRITICAL: 3.041e+04 ge 3600 https://grafana.wikimedia.org/dashboard/db/wikidata-query-service?orgId=1&panelId=8&fullscreen 05:20 < icinga-wm> PROBLEM - wikidata.org dispatch lag is REALLY high ---4000s- on www.wikidata.org is CRITICAL: HTTP CRITICAL: HTTP/1.1 200 OK - pattern not found - 1979 bytes 05:22 < icinga-wm> RECOVERY - MariaDB Slave Lag: s8 on db2086 is OK: OK slave_sql_lag Replication lag: 0.33 seconds 05:22 < icinga-wm> RECOVERY - MariaDB Slave Lag: s8 on db2085 is OK: OK slave_sql_lag Replication lag: 0.00 seconds 05:29 < icinga-wm> RECOVERY - MariaDB Slave Lag: s8 on db1099 is OK: OK slave_sql_lag Replication lag: 0.00 seconds
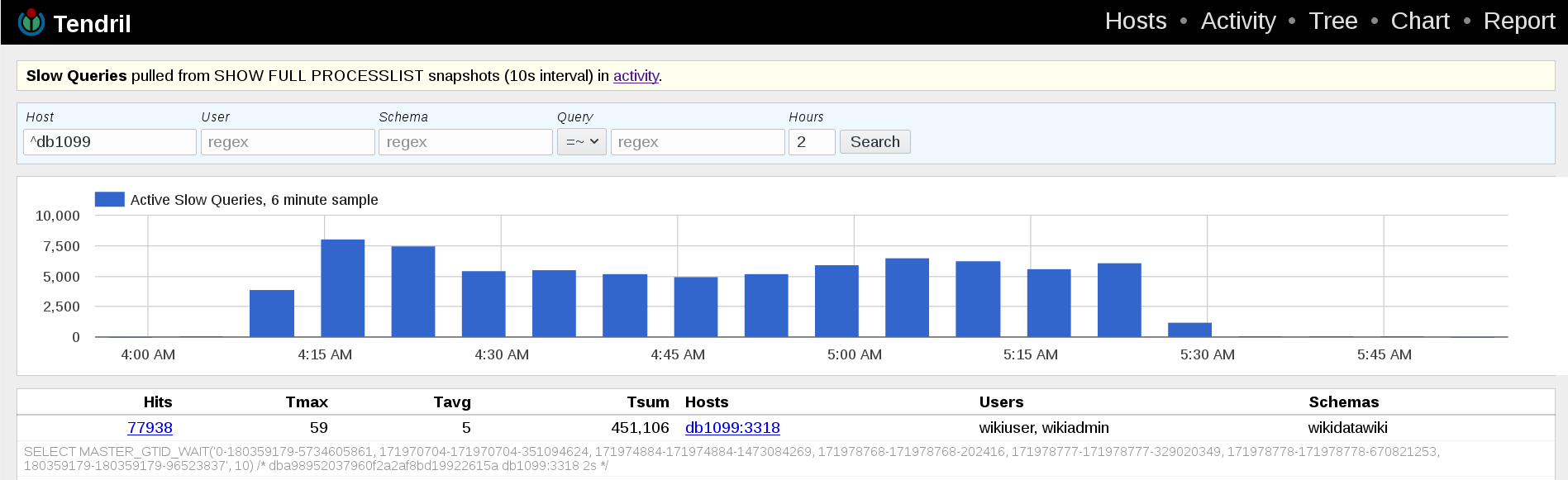
db1099 a recentchanges slave was indeed lagging: https://grafana.wikimedia.org/dashboard/db/mysql-replication-lag?orgId=1&panelId=12&fullscreen&from=1529898238254&to=1529905275896&var-dc=eqiad%20prometheus%2Fops
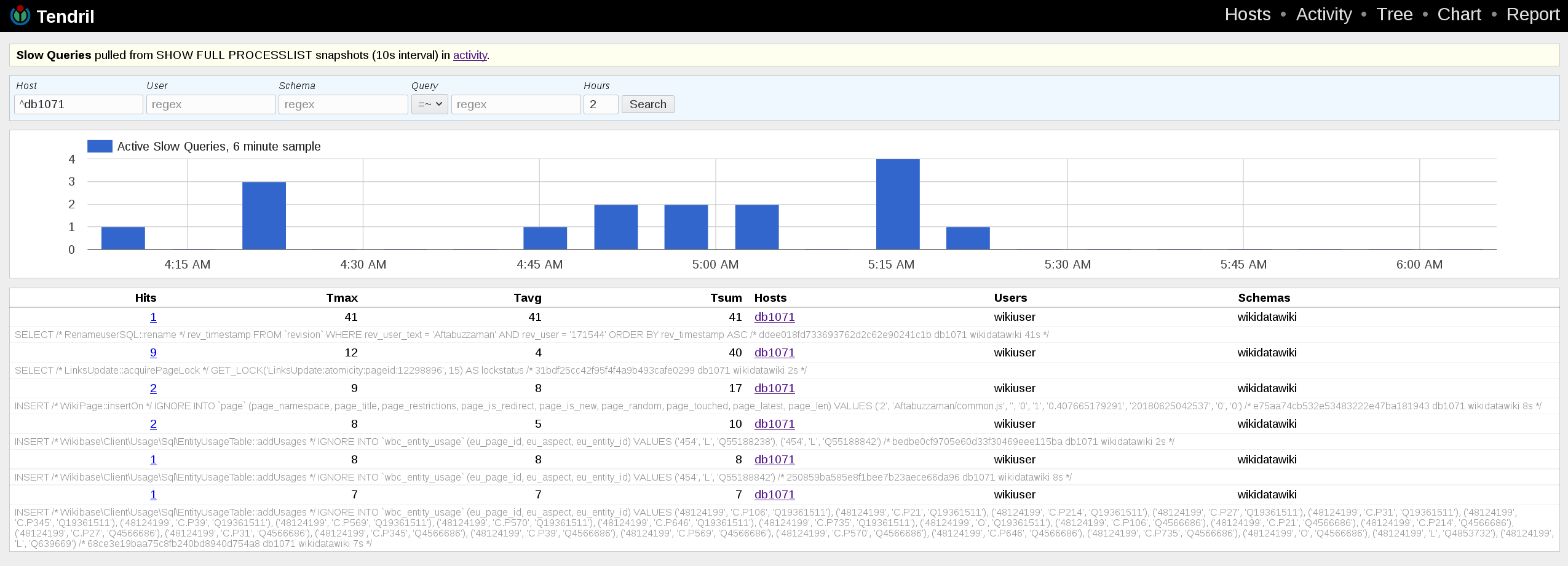
db1071, the master, had no writes: https://grafana.wikimedia.org/dashboard/db/mysql?panelId=2&fullscreen&orgId=1&var-dc=eqiad%20prometheus%2Fops&var-server=db1071&var-port=9104&from=1529862857226&to=1529906057227
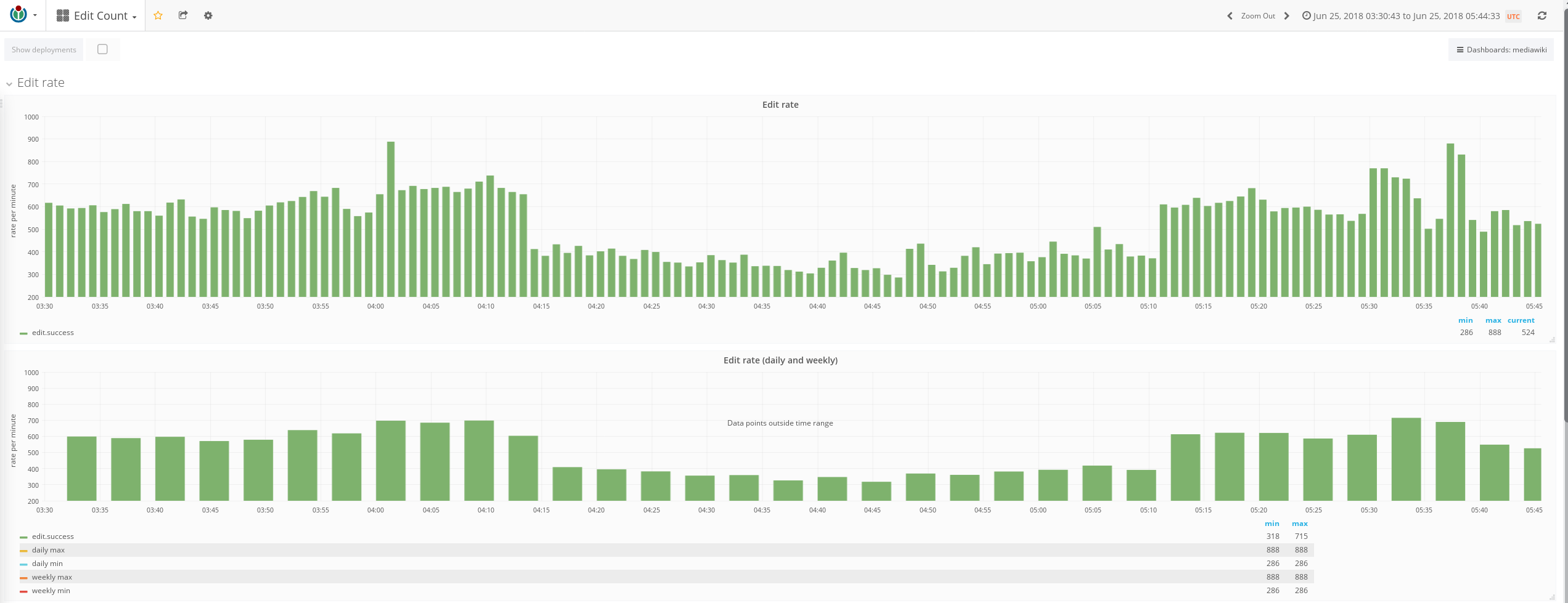
This could have possible caused a writes incident, it needs to be investigated.
Could this be a consequence of the load balancer misbehaviour (T180918) where a single slave brings down the entire section?