In preparation for the trailblaze that should be starting in March
Description
Description
| Status | Subtype | Assigned | Task | ||
|---|---|---|---|---|---|
| Resolved | Addshore | T208425 [EPIC] Kill the wb_terms table | |||
| Resolved | Addshore | T219176 Investigate normalization of wb_terms table 2019 | |||
| Resolved | Addshore | T215902 Investigate normalization of data stored in wb_terms table | |||
| Resolved | • Marostegui | T211338 Make a copy of the current wb_terms table on the MCR testing DB servers |
Event Timeline
Comment Actions
My first investigation into table normalization went for full normalization:
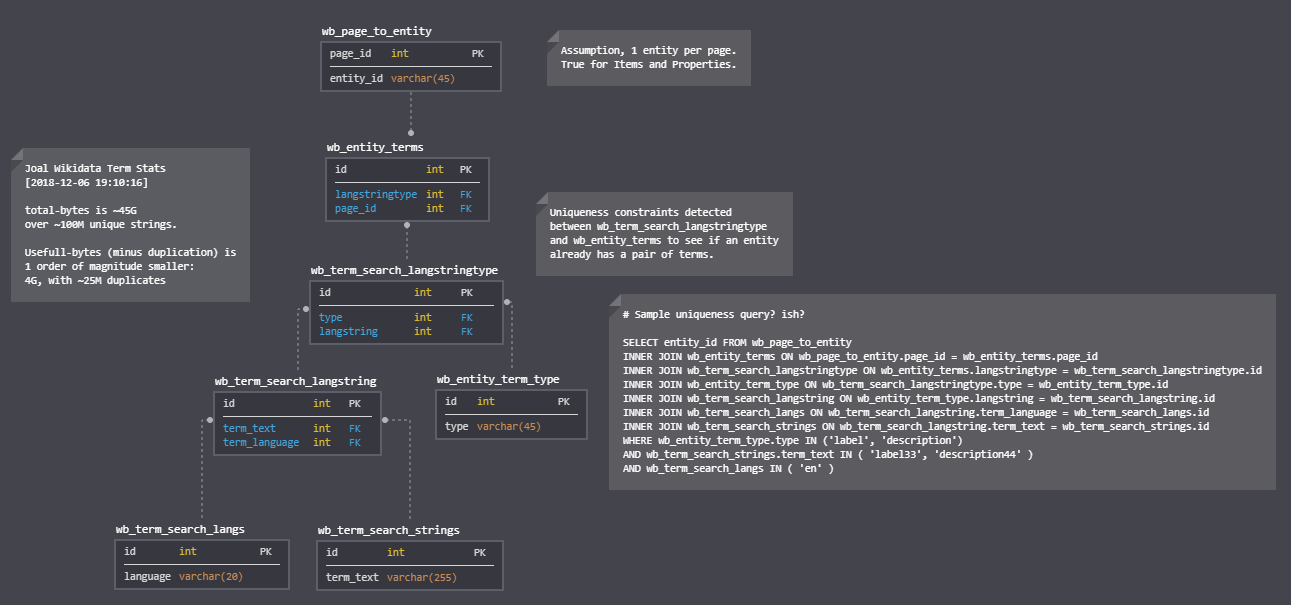
The queries to get there from the wb_terms table can be found @ P8075 and have been running on the test servers over the past week.
- term_type, small table holding the types of strings to be indexed in the db, right now this would be labels, descriptions and aliases, but this would scale to allowing more similar terms into the index (if desired) It might be the case not having a table here would be better and just keep INT ids in code.
- languages, table giving language codes numeric IDs.
- strings, the strings used in terms
- langstring, representing a string in a set language
- langstringtype, representing a langstring as a given type
- page_entity, one row for each entity, providing a direct lookup to a pageid
- entity_terms, representing a term on an entity (using reference to page_id)
Results
| Data | Index | Compressed Data | Compressed Index | rows | |
|---|---|---|---|---|---|
| term_type | 16KB | 16KB | 8KB | 8KB | 3 |
| languages | 16KB | 16KB | 24KB | 8KB | 432 |
| strings | 6.5GB | 5GB | 3.7GB | 2.6GB | 108,059,306 |
| langstring | 9.8GB | 9.1GB | 6.6GB | 2.7GB | 310,983,369 |
| langstringtype | 9.8GB | 8.9GB | 6.1GB | 2.7GB | 313,554,459 |
| page entity | 1.6GB | 1GB | 0.95GB | 0.5GB | 50,276,496 |
| entity terms | 58.5GB | 53.1GB | 37.5GB | 16.4GB | 1,809,036,849 |
| TOTAL | 86GB | 77GB | 54.8GB | 24.9GB | |
Down from the current size of wb_terms on the test server, 107GB data, 288GB index = 395GB total
Things to note
- There may be little point in normalizing the term_type for example. This thing only has 3 rows. (languages is also pretty small)
- The page table would be used for joins as part of this normalization, and this normalization currently has the assumption that there is a 1:1 relationship between page and entity.
- entity_type is in old wb_terms table, but not in this new normalization, given the assumption of 1:1 with pages and 1 NS per entity type right now it would be safe to do queries joined on the page table when looking or entities of a given type.
- The insertion logic for terms is more complex than we currently have, deletion logic to be decided, do we even have to remove values from tables such as langstring and langstring type when an entity term is removed? probably not...
- There is only likely to be duplication between aliases and labels in terms of string usage currently, descriptions and labels are less likely to have this space saving duplication
- langstring has 310983369 rows, langstringtype has 313554459 rows. This might indicate slightly too much normalization here (at least for now) and we could remove the complexity by having a single langstring type table with id, lang_id, string_id, type_id
Next steps
- Investigate what the queries would look like with this schema for reading in the various ways that we do, insertions and deletions.
- Would we be able to maintain a wb_terms view from this data for labs? Would we even want to do that?
- DBA review of this comment
- What would the migration look like?
- TBA
Comment Actions
Thanks for working on this! :-)
The queries to get there from the wb_terms table can be found @ P8075 and have been running on the test servers over the past week.
- term_type, small table holding the types of strings to be indexed in the db, right now this would be labels, descriptions and aliases, but this would scale to allowing more similar terms into the index (if desired) It might be the case not having a table here would be better and just keep INT ids in code.
- languages, table giving language codes numeric IDs.
- strings, the strings used in terms
- langstring, representing a string in a set language
- langstringtype, representing a langstring as a given type
- page_entity, one row for each entity, providing a direct lookup to a pageid
- entity_terms, representing a term on an entity (using reference to page_id)
Results
Data Index Compressed Data Compressed Index rows term_type 16KB 16KB 8KB 8KB 3 languages 16KB 16KB 24KB 8KB 432 strings 6.5GB 5GB 3.7GB 2.6GB 108,059,306 langstring 9.8GB 9.1GB 6.6GB 2.7GB 310,983,369 langstringtype 9.8GB 8.9GB 6.1GB 2.7GB 313,554,459 page entity 1.6GB 1GB 0.95GB 0.5GB 50,276,496 entity terms 58.5GB 53.1GB 37.5GB 16.4GB 1,809,036,849 TOTAL 86GB 77GB 54.8GB 24.9GB Down from the current size of wb_terms on the test server, 107GB data, 288GB index = 395GB total
Things to note
- There may be little point in normalizing the term_type for example. This thing only has 3 rows. (languages is also pretty small)
Agreed, probably no need to do that with either term_type and languages.
- The page table would be used for joins as part of this normalization, and this normalization currently has the assumption that there is a 1:1 relationship between page and entity.
- entity_type is in old wb_terms table, but not in this new normalization, given the assumption of 1:1 with pages and 1 NS per entity type right now it would be safe to do queries joined on the page table when looking or entities of a given type.
- The insertion logic for terms is more complex than we currently have, deletion logic to be decided, do we even have to remove values from tables such as langstring and langstring type when an entity term is removed? probably not...
Why is that? (just trying to understand the logic)
- There is only likely to be duplication between aliases and labels in terms of string usage currently, descriptions and labels are less likely to have this space saving duplication
- langstring has 310983369 rows, langstringtype has 313554459 rows. This might indicate slightly too much normalization here (at least for now) and we could remove the complexity by having a single langstring type table with id, lang_id, string_id, type_id
Why not combining strings langstring and langstringtype on the same table?
Is that what you mean with: we could remove the complexity by having a single langstring type table with id, lang_id, string_id, type_id?
Keep in mind that I could be saying nosenses! I don't have the full context of how all the logic behind wb_terms.
Next steps
- Investigate what the queries would look like with this schema for reading in the various ways that we do, insertions and deletions.
Indeed, that is a key point. We'd need to check their query plans and all that beforehand?
- Would we be able to maintain a wb_terms view from this data for labs? Would we even want to do that?
What do you mean? Create a view to query all the new tables to produce the same results as we currently have with wb_terms?
- DBA review of this comment
- What would the migration look like?
I guess the easiest is to migrate things while writing to both and at some point once both set of tables are in sync switch the writes to the new tables only?
Comment Actions
term_type, small table holding the types of strings to be indexed in the db, right now this would be labels, descriptions and aliases, but this would scale to allowing more similar terms into the index (if desired) It might be the case not having a table here would be better and just keep INT ids in code.
There may be little point in normalizing the term_type for example. This thing only has 3 rows. (languages is also pretty small)
We could also turn term types and languages into short IDs via a hash function: as far as I’m aware, Wikibase only needs the string→ID direction (hash function), and if we need the ID→string direction (e. g. during manual investigation) we can hash all the known term types / language codes and look for the value we have.
Why not combining strings langstring and langstringtype on the same table?
For certain common types of items – especially people, but also e. g. cities – it is common to have the same label in a lot of different languages (see also T188992#4026839), so I think a strings table without a language code should help a lot. I’m not sure about the distinction between langstring and langstringtype though.
I guess the easiest is to migrate things while writing to both and at some point once both set of tables are in sync switch the writes to the new tables only?
Do the DB servers have enough storage space for this?
Comment Actions
The old ones certainly not (ie: the master or codfw) - we are discussing now how to proceed in regard to those old servers, but we are on early stages of this.
I should have been clearer though, my point was to, while you move stuff from one table to the other(s) you keep delete rows from wb_terms - we might need to optimize the table along the way to actually claim back all that disk space on the servers.
Comment Actions
"Why is that?", is that referring to insertion or deletion logic?
Well, with the wb_terms table, we are just adding a row for each term on an entity.
The normalization of course introduces more tables so for a single term entry 7 inserts may be needed (at least with the initial draft first introduced in this ticket)
Using a hashing approach for languages and term types of course brings this from 7 to 5.
The Mapping from page_id to entity ID could also be seen as not relating to the terms index specifically and could then be assumed to already be there.
For deletions the same applies, just deleting rows.
For the normalized version we will likely only remove entries from wb_entity_terms in real time, which has the potential to leave "dead data" in all of the other tables.
Initially this is not something that we will need to think about, but at some stage we might want to think about cleanup measures (could just be a maint script etc).
- There is only likely to be duplication between aliases and labels in terms of string usage currently, descriptions and labels are less likely to have this space saving duplication
- langstring has 310983369 rows, langstringtype has 313554459 rows. This might indicate slightly too much normalization here (at least for now) and we could remove the complexity by having a single langstring type table with id, lang_id, string_id, type_id
Why not combining strings langstring and langstringtype on the same table?
Is that what you mean with: we could remove the complexity by having a single langstring type table with id, lang_id, string_id, type_id?
Keep in mind that I could be saying nosenses! I don't have the full context of how all the logic behind wb_terms.
It looks like it will make sense to merge the langstring and langstringtype tables together, resulting in a single table that looks something like (below example also including the hashing of types and language codes rather than relating to another table):
id, stringId, langHashInt, stringTypeInt 1, 1, 421809, 511251 2, 3, 21424, 511251
Next steps
- Investigate what the queries would look like with this schema for reading in the various ways that we do, insertions and deletions.
Indeed, that is a key point. We'd need to check their query plans and all that beforehand?
Yes we should probably check the query plans before hand.
In theory all queries plans should be pretty straightforward for mysql to not mess up, and should also be the "most efficient".
- Would we be able to maintain a wb_terms view from this data for labs? Would we even want to do that?
What do you mean? Create a view to query all the new tables to produce the same results as we currently have with wb_terms?
Yes. This could be useful for an easier migration, but also we might want to leave this view around for a while for users of the wb_terms table on the labs db replicas.
- What would the migration look like?
I guess the easiest is to migrate things while writing to both and at some point once both set of tables are in sync switch the writes to the new tables only?
That would be the easiest IMO.
Something more complex could include creating a set of filled tables at a point in time (perhaps in alternate DC) then switching traffic, then running a maint script to catch the tables back up to reality, and then start reading from them (would likely be faster, but probably more active work?
Yup, removing these 2 tables would be possible with some simple hashing.
This would make the tables slightly harder for people to work with on the labsdb replicas however (something to consider).
Deleting rows from wb_terms as we go could be possible, but in the perfect situation we would avoid touching this table at all, until the point that we can drop it, to avoid anything odd happening with query plans and index decisions that could throw a spanner in the works.
How much disk does the old codfw master have?
Comment Actions
P8075 actually creates slightly wrong tables (well one of them with the wrong indexes).
The change would be to the _2 table here:
test_wikiadmin@db1111(wikidatawiki)> show index from wb_entity_terms; +-----------------+------------+----------------+--------------+----------------+-----------+-------------+----------+--------+------+------------+---------+---------------+ | Table | Non_unique | Key_name | Seq_in_index | Column_name | Collation | Cardinality | Sub_part | Packed | Null | Index_type | Comment | Index_comment | +-----------------+------------+----------------+--------------+----------------+-----------+-------------+----------+--------+------+------------+---------+---------------+ | wb_entity_terms | 0 | PRIMARY | 1 | id | A | 1809036849 | NULL | NULL | | BTREE | | | | wb_entity_terms | 0 | unique_content | 1 | page_id | A | 86144611 | NULL | NULL | | BTREE | | | | wb_entity_terms | 0 | unique_content | 2 | langstringtype | A | 1809036849 | NULL | NULL | | BTREE | | | +-----------------+------------+----------------+--------------+----------------+-----------+-------------+----------+--------+------+------------+---------+---------------+ 3 rows in set (0.00 sec) test_wikiadmin@db1111(wikidatawiki)> show index from wb_entity_terms_2; +-------------------+------------+---------------+--------------+----------------+-----------+-------------+----------+--------+------+------------+---------+---------------+ | Table | Non_unique | Key_name | Seq_in_index | Column_name | Collation | Cardinality | Sub_part | Packed | Null | Index_type | Comment | Index_comment | +-------------------+------------+---------------+--------------+----------------+-----------+-------------+----------+--------+------+------------+---------+---------------+ | wb_entity_terms_2 | 0 | PRIMARY | 1 | id | A | 1802836762 | NULL | NULL | | BTREE | | | | wb_entity_terms_2 | 1 | page_index | 1 | page_id | A | 78384207 | NULL | NULL | | BTREE | | | | wb_entity_terms_2 | 1 | content_index | 1 | langstringtype | A | 901418381 | NULL | NULL | | BTREE | | | +-------------------+------------+---------------+--------------+----------------+-----------+-------------+----------+--------+------+------------+---------+---------------+ 3 rows in set (0.00 sec)
This allows completing the last join needed to get from a (lang,string,type) to a page_id which can then be joined to find entity id (wb_page_to_entity)
Comment Actions
Queries end up going from something like this:
SELECT term_full_entity_id FROM wb_terms WHERE term_text = 'Berlin' AND (term_type = 'label' OR term_type = 'alias') AND term_language = 'en';
To something like this:
SELECT entity_id, wb_entity_term_type.type as type, wb_term_search_langs.language as lang, wb_term_search_strings.term_text as text FROM wb_page_to_entity INNER JOIN wb_entity_terms_2 ON wb_page_to_entity.page_id = wb_entity_terms_2.page_id INNER JOIN wb_term_search_langstringtype ON wb_entity_terms_2.langstringtype = wb_term_search_langstringtype.id INNER JOIN wb_term_search_langstring ON wb_term_search_langstringtype.langstring = wb_term_search_langstring.id INNER JOIN wb_term_search_langs ON wb_term_search_langstring.term_language = wb_term_search_langs.id INNER JOIN wb_term_search_strings ON wb_term_search_langstring.term_text = wb_term_search_strings.id INNER JOIN wb_entity_term_type ON wb_term_search_langstringtype.type = wb_entity_term_type.id WHERE wb_term_search_strings.term_text = 'Berlin' AND (wb_entity_term_type.type = 'label' OR wb_entity_term_type.type = 'alias') AND wb_term_search_langs.language = 'en';
Comment Actions
I don't know if this is being considered but we definitely should do join decomposition in most of these cases for example entity_type, term_type, etc. That way this can be cached in several layers (like MySQL cache, services cache in mediawiki). Pretty much similar to NameTableStore that's being used for normalized tables.
Comment Actions
I don't know if this is being considered but we definitely should do join decomposition in most of these cases for example entity_type, term_type, etc. That way this can be cached in several layers (like MySQL cache, services cache in mediawiki). Pretty much similar to NameTableStore that's being used for normalized tables.
That could probably be considered for the language and or term type, but also the idea of using a hash for these instead of having them in a separate table is quite appealing.
Comment Actions
Actually, I’m starting to dislike my hash idea again :D I feel like it unnecessarily complicates the situation with not much benefit over hard-coded IDs (const TERM_TYPE_LABEL = 1) or the full values (language codes are already pretty short). And if we keep the separate tables for language / term type IDs, we can still avoid querying them most of the time by caching their contents, similar to what we do for tags.