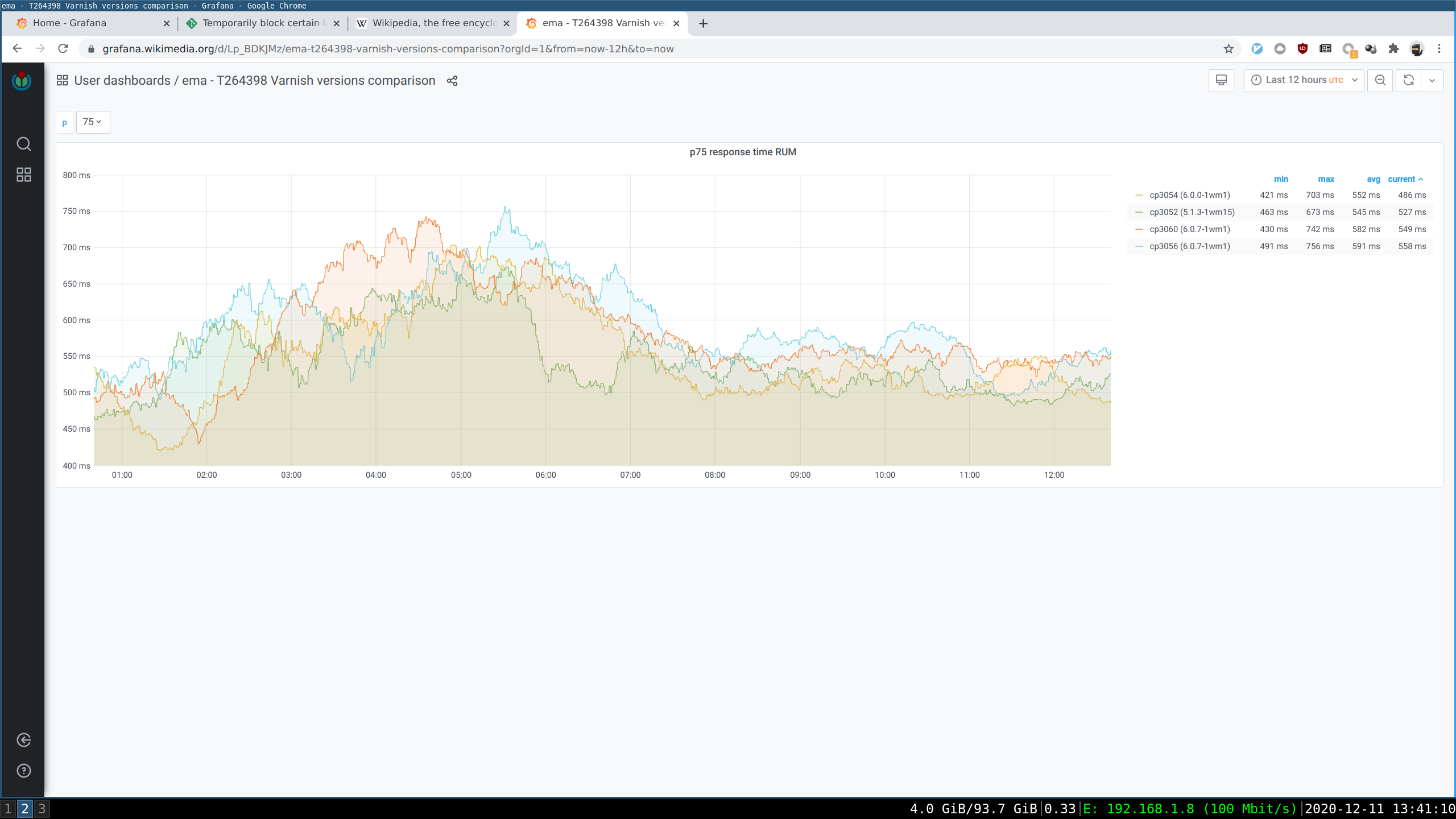
After seeing strong time-correlation between the response start regression and the rollout of Varnish 6 per DC for Eqsin on 2020-09-25:

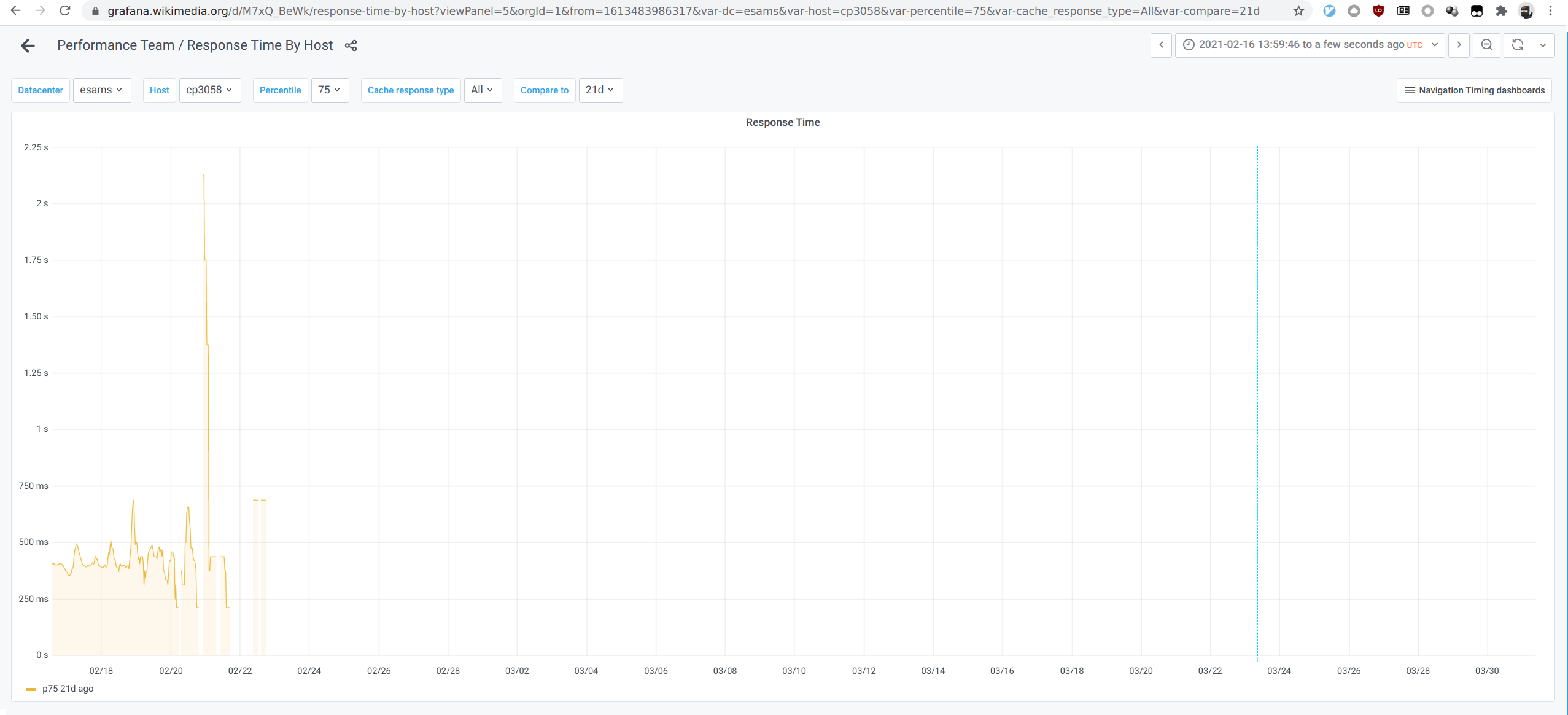
And for Esams on 2020-09-29:

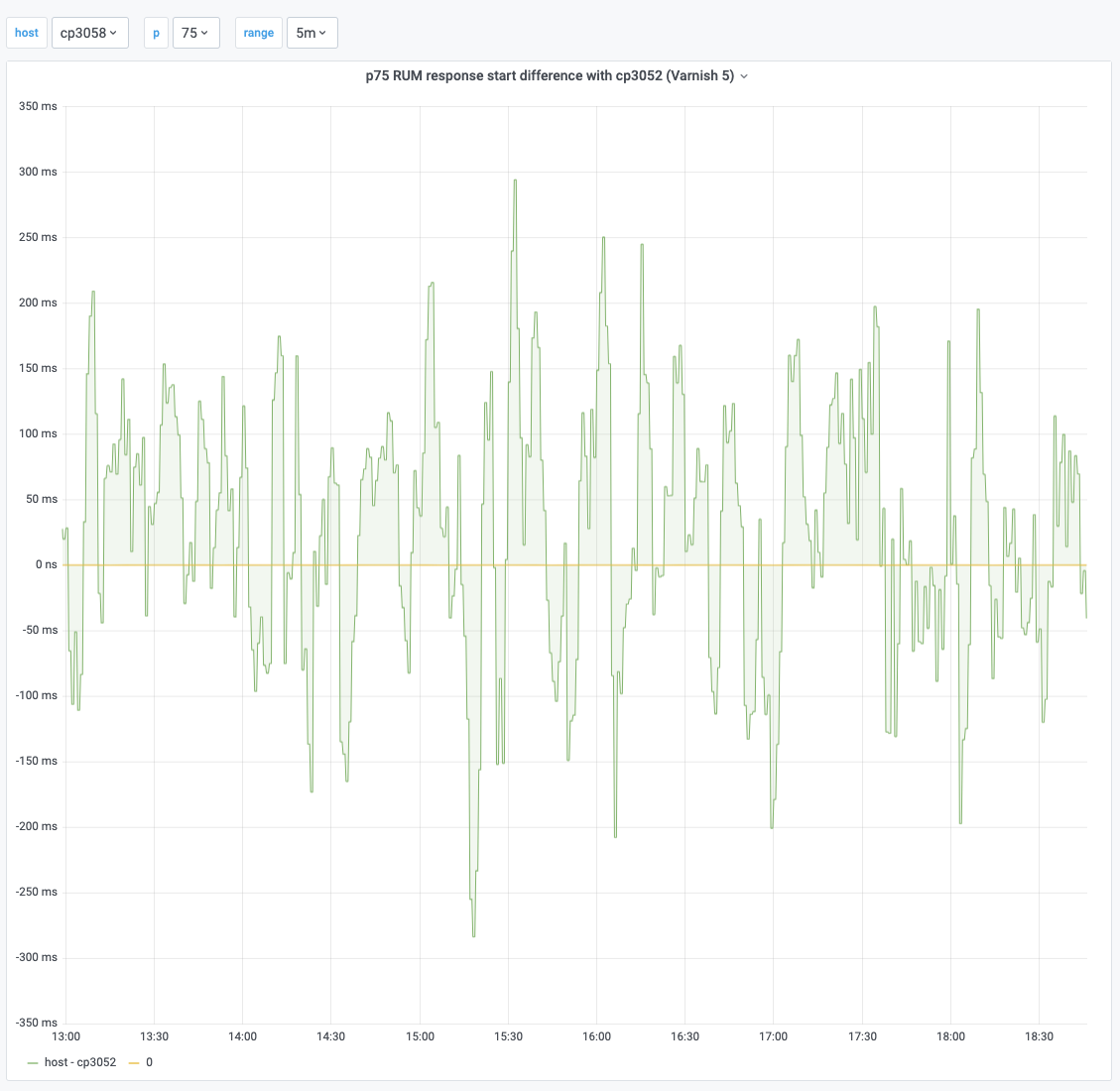
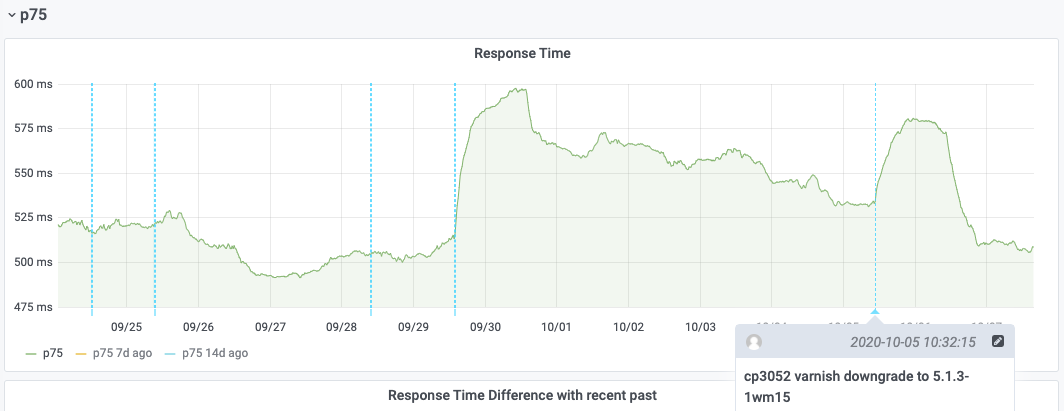
Varnish was rolled back to its previous version on 2020-10-05 on Esams host cp3052. Once the cache populated again, we can see that response start performance goes back to its pre-upgrade levels:
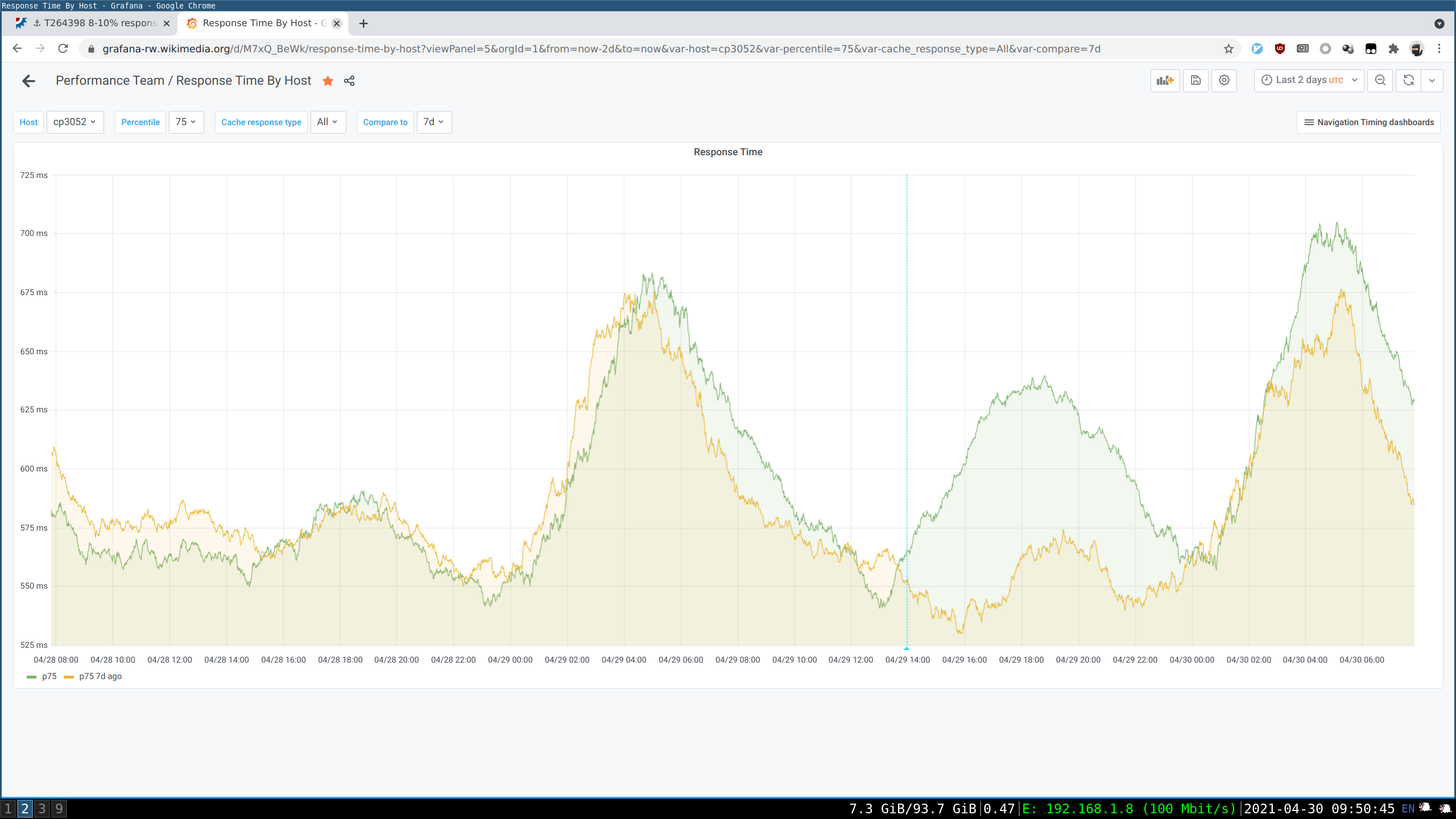
Which isn't the case for the rest of Esams hosts, which were not rolled back and whose response start stayed elevated:
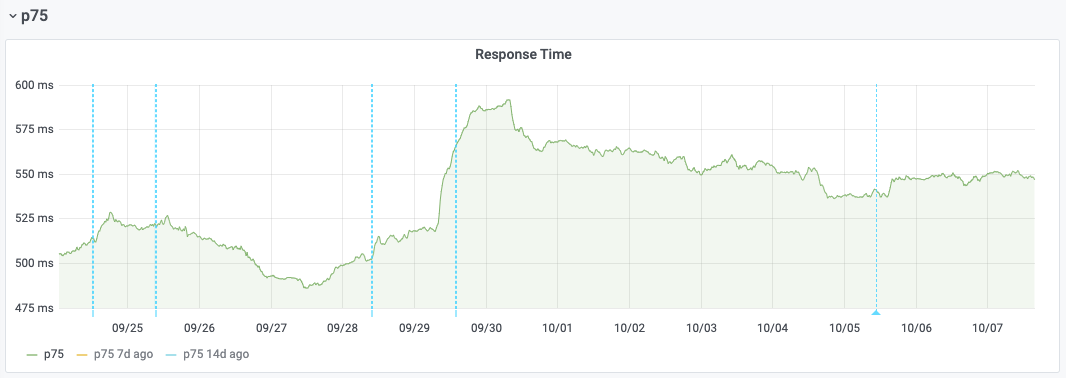

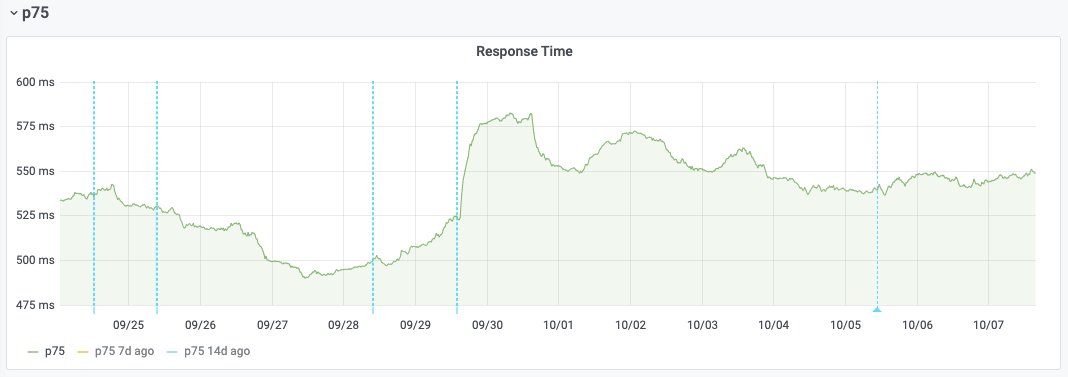
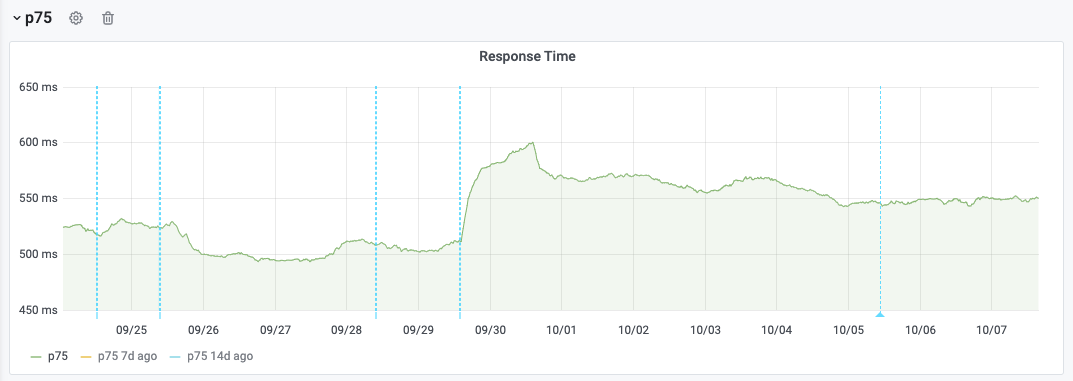
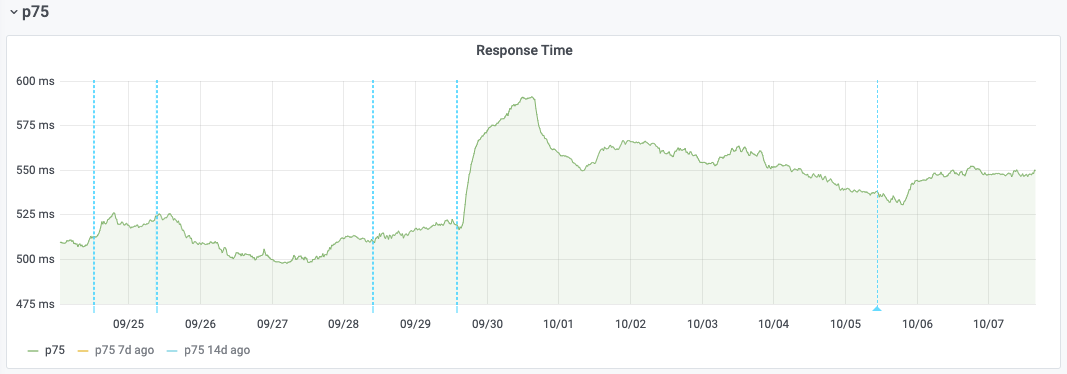
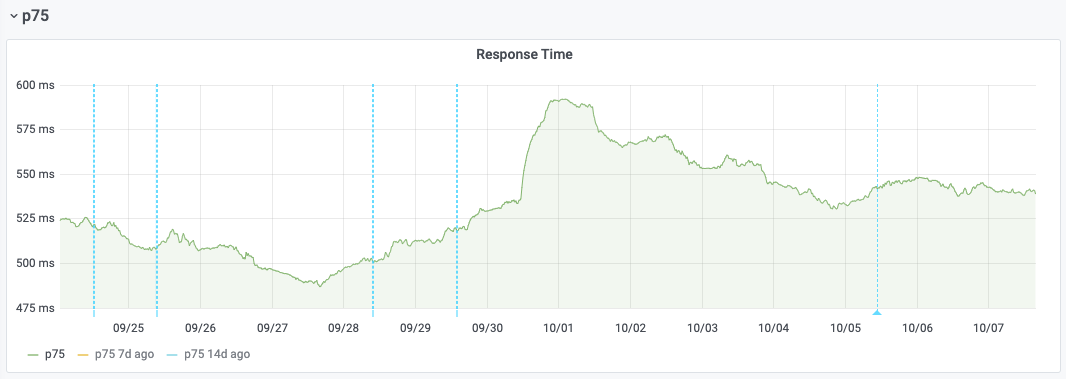
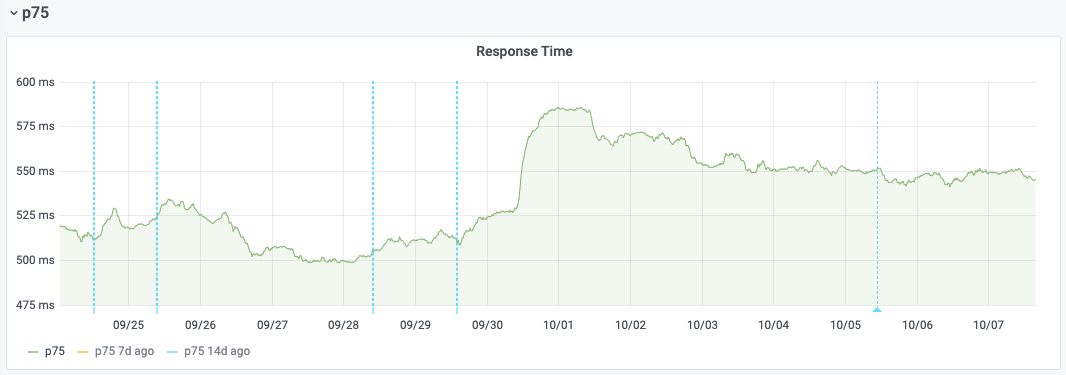
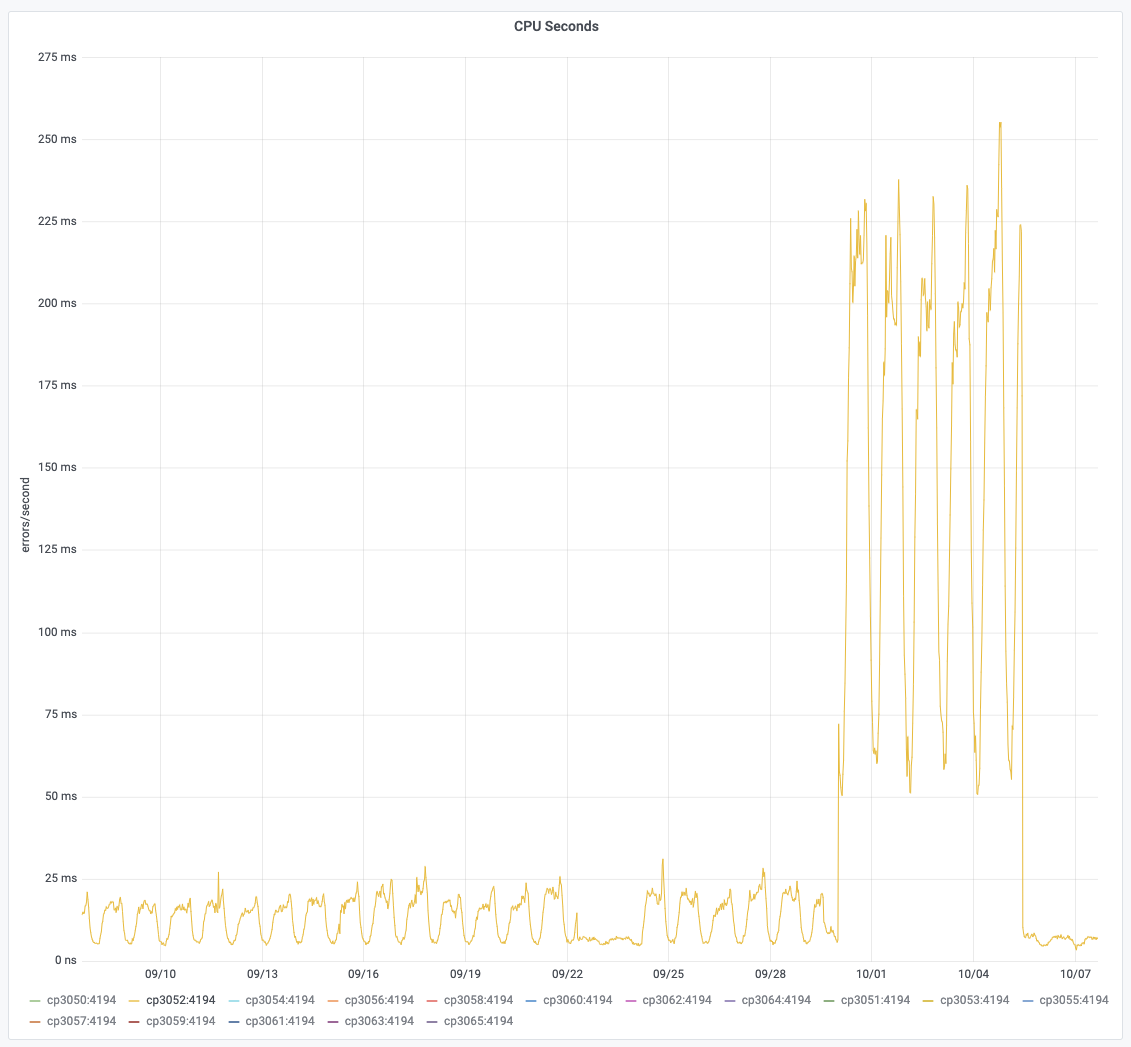
This regression could be a side-effect of T264074: varnishkafka 1.1.0 CPU usage increase, which happens alongside the upgrade. For that issue as well, we can see that the rollback gets rid of the CPU spikes on cp3052: