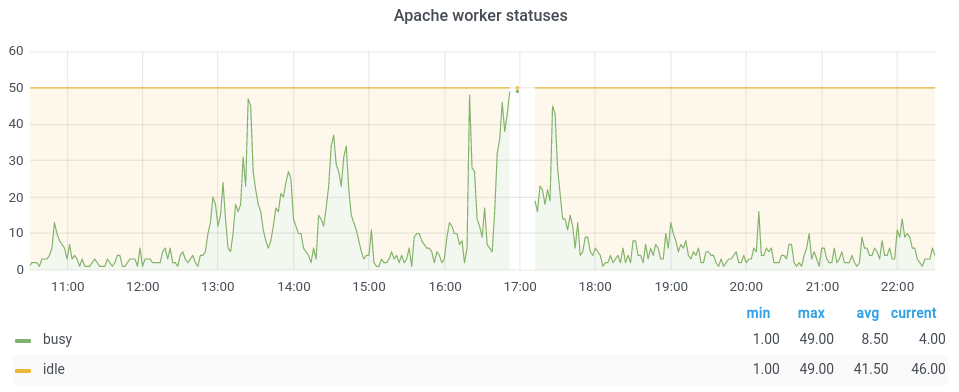
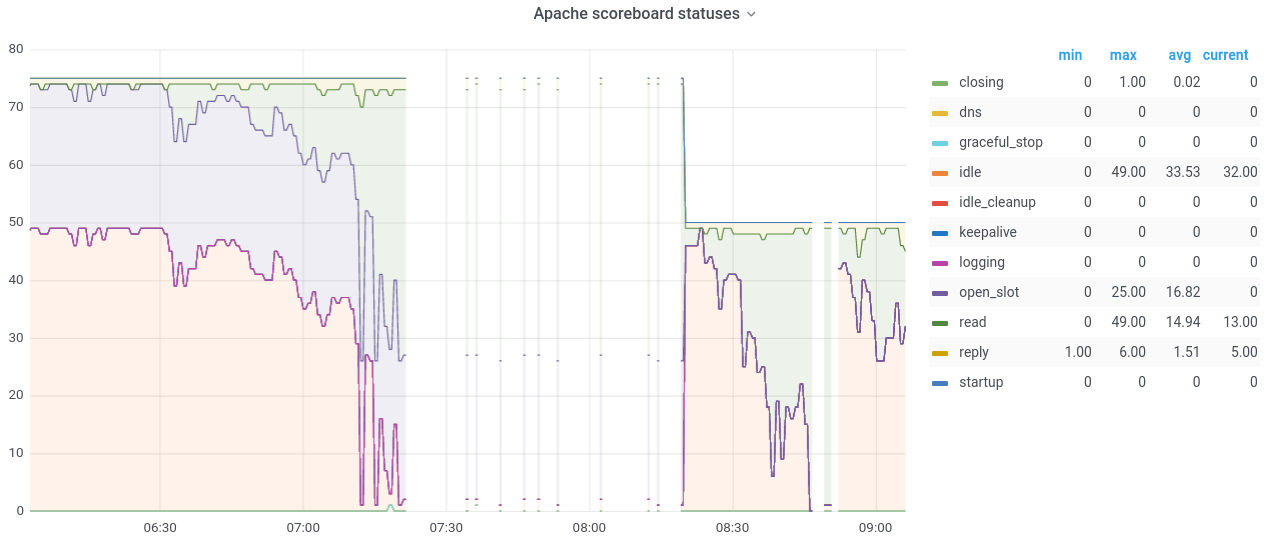
2021-03-11 05:03 UTC the apache process that is in front of gerrit ran out of workers:
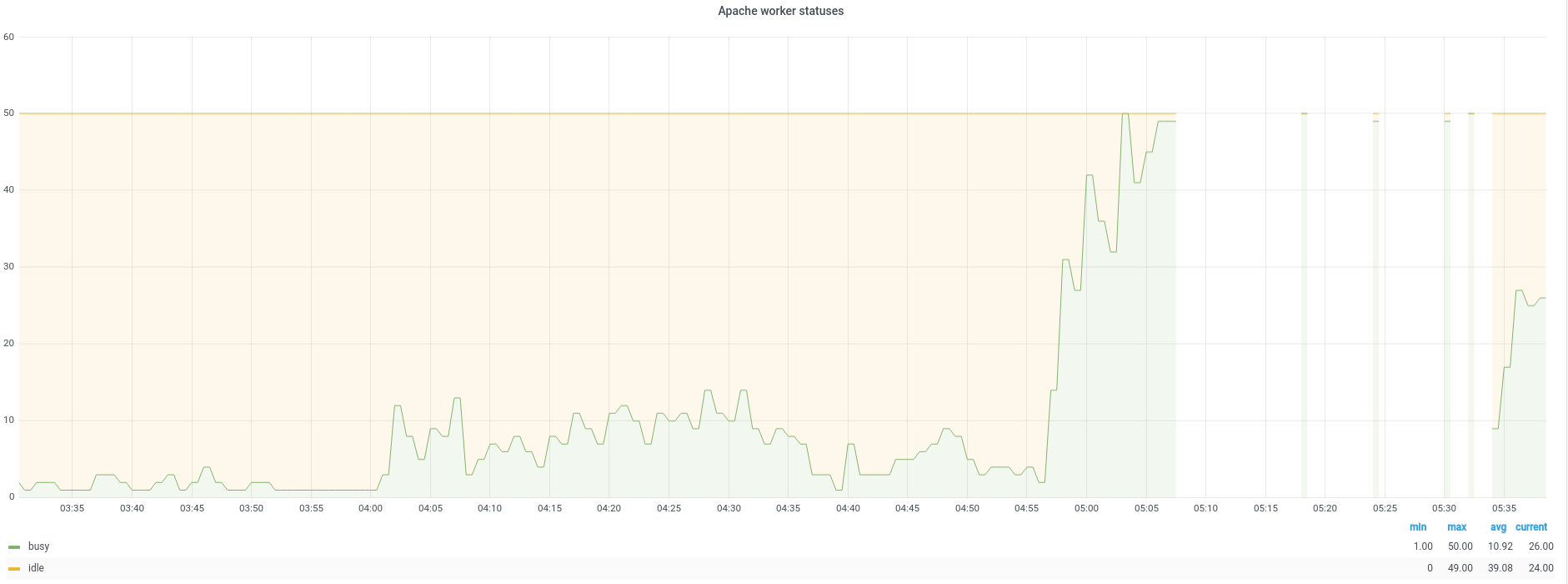
(https://grafana.wikimedia.org/d/L0-l1o0Mz/apache?orgId=1&refresh=1m&var-host=gerrit1001&var-port=9117)
Preliminary look at the access logs doesn't show anything particularly surprising: crawlers, lots of upload packs, gitiles requests. There are a few aggressive crawlers: in particular a local one looking at the changes api. This is the 2nd time I can recall having to restart apache to restore, so it could use a bit of investigation.
How to check
| Apache scoreboard | https://grafana.wikimedia.org/d/L0-l1o0Mz/apache?var-host=gerrit1001 |
| Gerrit HTTP threads view | https://grafana.wikimedia.org/d/Zh_ncGsWk/queues-upstream?viewPanel=20 |