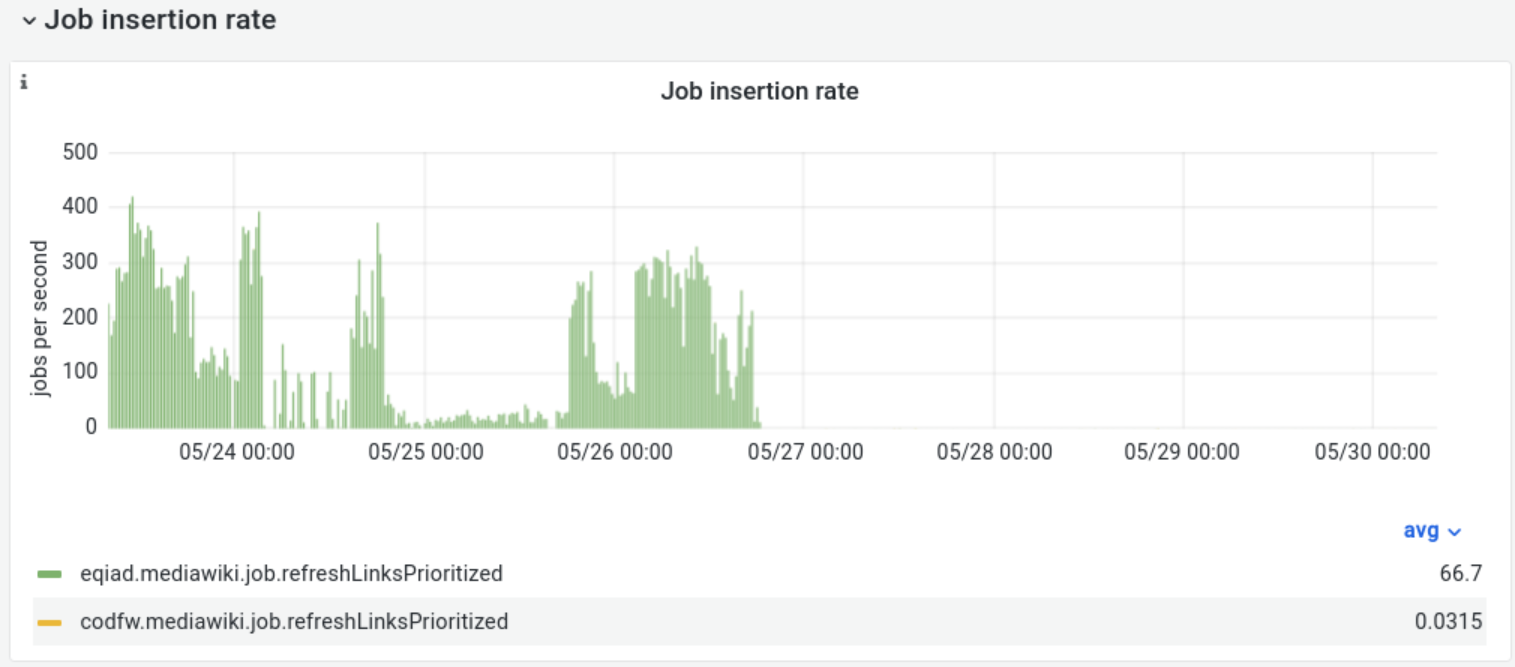
Looking at the rate of some CirrusSearch jobs we found that this rate is way higher in metawiki than the other wikis (~200 updates/sec out of 400/sec for all our sites).
Digging further it seems that the refreshLinksPrioritized queue is populated with jobs that are repeated over and over using the same meta.request_id UUID.
kafkacat -b kafka-main1005.eqiad.wmnet:9092 -t eqiad.mediawiki.job.refreshLinksPrioritized -e -o beginning | grep '"request_id":"5c452897402f7057c3b099a0"' | head -n 10000 | jq -r .params.title > 5c452897402f7057c3b099a0.lst sort -u 5c452897402f7057c3b099a0.lst | wc -l 39
Example titles:
B18_1128_WMCH_mob_lrg-WMCH-2018-moblrg-priceofcoffee/en B18_1128_WMCH_mob_lrg-WMCH-2018-moblrg-selectamount/en Centralnotice-B18_1128_WMCH_mob_lrg_clone-WMCH-2018-moblrg-allreaders Centralnotice-B18_1128_WMCH_mob_lrg_clone-WMCH-2018-moblrg-donatenow/it Centralnotice-B18_1128_WMCH_mob_lrg-WMCH-2018-moblrg-donationsaveraging/de Centralnotice-B18_1128_WMCH_mob_lrg-WMCH-2018-moblrg-gotoarticle/it Centralnotice-B18_1128_WMCH_mob_lrg-WMCH-2018-moblrg-selectpaymentmethod/de Centralnotice-Bridges_Across_Culture-line1/ar Centralnotice-CommunityInsightsResults2018_1-line1/fr Centralnotice-CommunityWishlistVote-CommunityWishlist-CNTranslationVote2-title/lb Centralnotice-CommunityWishlistVote-CommunityWishlist-CNTranslationVote3-title/ja Centralnotice-FR2015_translations-go-to-article/pl Centralnotice-FR2015_translations-how-often/pt Centralnotice-FR2015_translations-just-once/pl Centralnotice-FR2015_translations-mob-lg-greeting/pt Centralnotice-FR2015_translations-mob-lg-greeting/sk Centralnotice-FR2015_translations-mob-lg-pp-four/uk Centralnotice-FR2015_translations-mob-sm-pp-three/sk Centralnotice-FR2015_translations-now/sk Centralnotice-FR2015_translations-skip/pl Centralnotice-template-Bridges_Across_Culture Centralnotice-template-WikiMOOC_2018_B Centralnotice-template-WMCH1819_dsk_lg Centralnotice-WMCH1819_mob_conversion_nocss_robin-WMCH-2018-moblrg-allreaders/fr Centralnotice-WMCH1819_mob_conversion_nocss_robin-WMCH-2018-moblrg-donationsaveraging/de Centralnotice-WMCH1819_mob_conversion_nocss_robin-WMCH-2018-moblrg-noeasytime/it Centralnotice-WMCH1819_mob_conversion_nocss_robin-WMCH-2018-moblrg-oneminute/fr Centralnotice-WMCH1819_mob_conversion_nocss_robin-WMCH-2018-moblrg-selectpaymentmethod/de CommunityInsightsResults2018_3-line2/en TestBanner_AGreen-msg1/en WMCH1819_dsk_lg_clone-WMCH-2018-dsklrg-msg/en WMCH1819_dsk_sm-WMCH-2018-dsksm-text/en WMCH1819_mob_conversion_nocss_robin-WMCH-2018-moblrg-donatenow/en WMCH1819_mob_conversion_nocss_robin-WMCH-2018-moblrg-ifeveryone/en WMCH1819_mob_conversion_nocss_robin-WMCH-2018-moblrg-openknowledge/en WMCH1819_mob_conversion_nocss_robin-WMCH-2018-moblrg-thankyou/en WMCH1819_mob_conversion_nocss_robin-WMCH-2018-moblrg-tothepoint/en WMIT_5X1000_2018_desktop_A-cinquepermille3/en
My understanding is that changeprop is propagating the request_id when hitting MW and thus seeing the same request_id in multiple jobs could indicate either:
- the jobs were submitted from the same PHP request
- there's a collision of request_id
- a request_id is being hard-coded in the code-base
- a job is creating another job
I'm leaning toward the last option, such behaviors do seem normal but here something seems to recursively trigger the same set of jobs without any TTL mechanism to stop the loop.
First job found in kafka is:
{"$schema":"/mediawiki/job/1.0.0","meta":{"uri":"https://placeholder.invalid/wiki/Special:Badtitle","request_id":"5c452897402f7057c3b099a0","id":"a00c199e-d223-4e89-b0f9-318cd9deb88d","dt":"2023-02-09T13:21:13Z","domain":"meta.wikimedia.org","stream":"mediawiki.job.refreshLinksPrioritized"},"database":"metawiki","type":"refreshLinksPrioritized","sha1":"10125a36bba3625a8afa186ba0ef41a9ffe24ebd","params":{"isOpportunistic":true,"rootJobTimestamp":"20230209132113","namespace":8,"title":"Centralnotice-FR2015_translations-now/sk","requestId":"5c452897402f7057c3b099a0","causeAction":"RefreshLinksJob","causeAgent":"unknown"},"mediawiki_signature":"2ce3d32e26a58119172834c60e69b8030cab90f1"}
Last one is:
{"$schema":"/mediawiki/job/1.0.0","meta":{"uri":"https://placeholder.invalid/wiki/Special:Badtitle","request_id":"5c452897402f7057c3b099a0","id":"8e8ece45-55c8-48bf-9f42-8ee9a31dcb78","dt":"2023-02-16T14:21:06Z","domain":"meta.wikimedia.org","stream":"mediawiki.job.refreshLinksPrioritized"},"database":"metawiki","type":"refreshLinksPrioritized","sha1":"26f521e2cca0ba13b7deee415ae3a284feba0248","params":{"isOpportunistic":true,"rootJobTimestamp":"20230216142106","namespace":866,"title":"WMCH1819_mob_conversion_nocss_robin-WMCH-2018-moblrg-donatenow/en","requestId":"5c452897402f7057c3b099a0","causeAction":"RefreshLinksJob","causeAgent":"unknown"},"mediawiki_signature":"bec5f0612a931926a94cdcd216095c02f02b4235"}
The 5c452897402f7057c3b099a0 request_id can be found in logstash since 2022-11-18.
The few pages I checked do all seem to be protected with pr_cascade = 1 and tempted to blame something fishy happening with cascade-protected backlinks propagation.
Currently the rate of refreshLinksPrioritized jobs for metawiki can be up to 400 evt/sec:
dcausse@stat1004:~$ kafkacat -b kafka-main1005.eqiad.wmnet:9092 -t eqiad.mediawiki.job.refreshLinksPrioritized -o end | grep '"domain":"meta.wikimedia.org"' | pv -l >/dev/null % Auto-selecting Consumer mode (use -P or -C to override) % Reached end of topic eqiad.mediawiki.job.refreshLinksPrioritized [0] at offset 6587943883 2.68k 0:00:08 [ 407 /s] [ <=> ]
and fluctuating between 5 and 20 for everything else.