Steps to replicate the issue (include links if applicable):
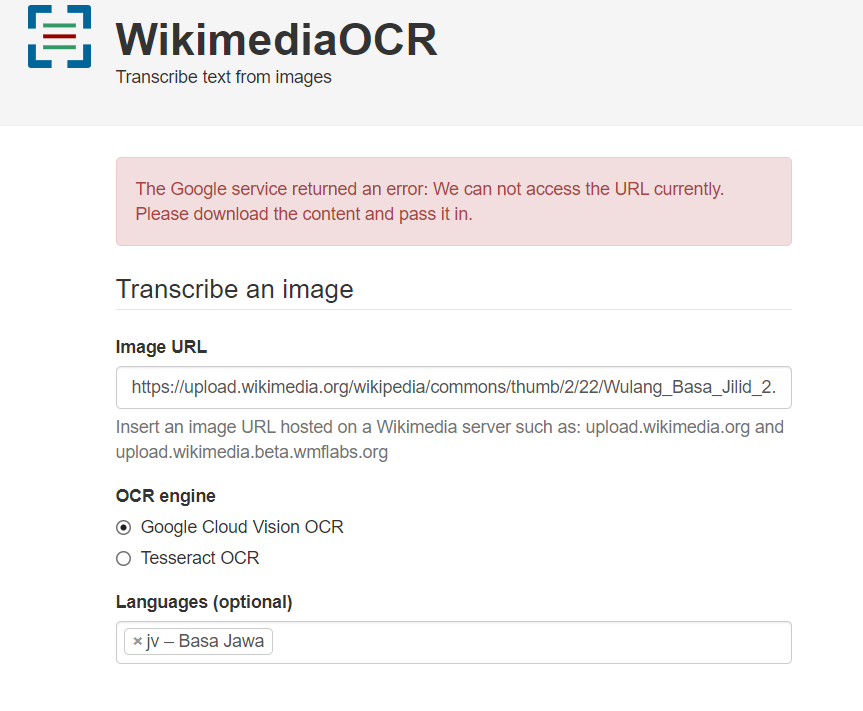
- Go to https://ocr.wmcloud.org/?image=https%3A%2F%2Fupload.wikimedia.org%2Fwikipedia%2Fcommons%2Fthumb%2F2%2F22%2FWulang_Basa_Jilid_2.pdf%2Fpage68-1239px-Wulang_Basa_Jilid_2.pdf.jpg&engine=google&langs%5B%5D=jv&psm=3
- Input https://upload.wikimedia.org/wikipedia/commons/thumb/2/22/Wulang_Basa_Jilid_2.pdf/page68-1239px-Wulang_Basa_Jilid_2.pdf.jpg
- Select Google OCR, click transcribe
The Google service returned an error: We can not access the URL currently. Please download the content and pass it in.
What happens?:
What should have happened instead?:
It should be able to find/access the URL.
Software version (skip for WMF-hosted wikis like Wikipedia):
Other information (browser name/version, screenshots, etc.):
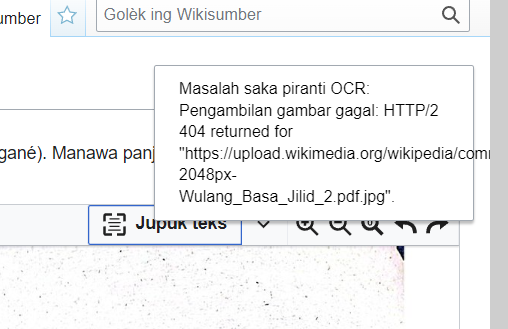
The bug was found when a user try to transcribe via Javanese Wikisource
https://jv.wikisource.org/w/index.php?title=Kaca:Wulang_Basa_Jilid_2.pdf/68&action=edit&redlink=1
This is the result via Wikisource: