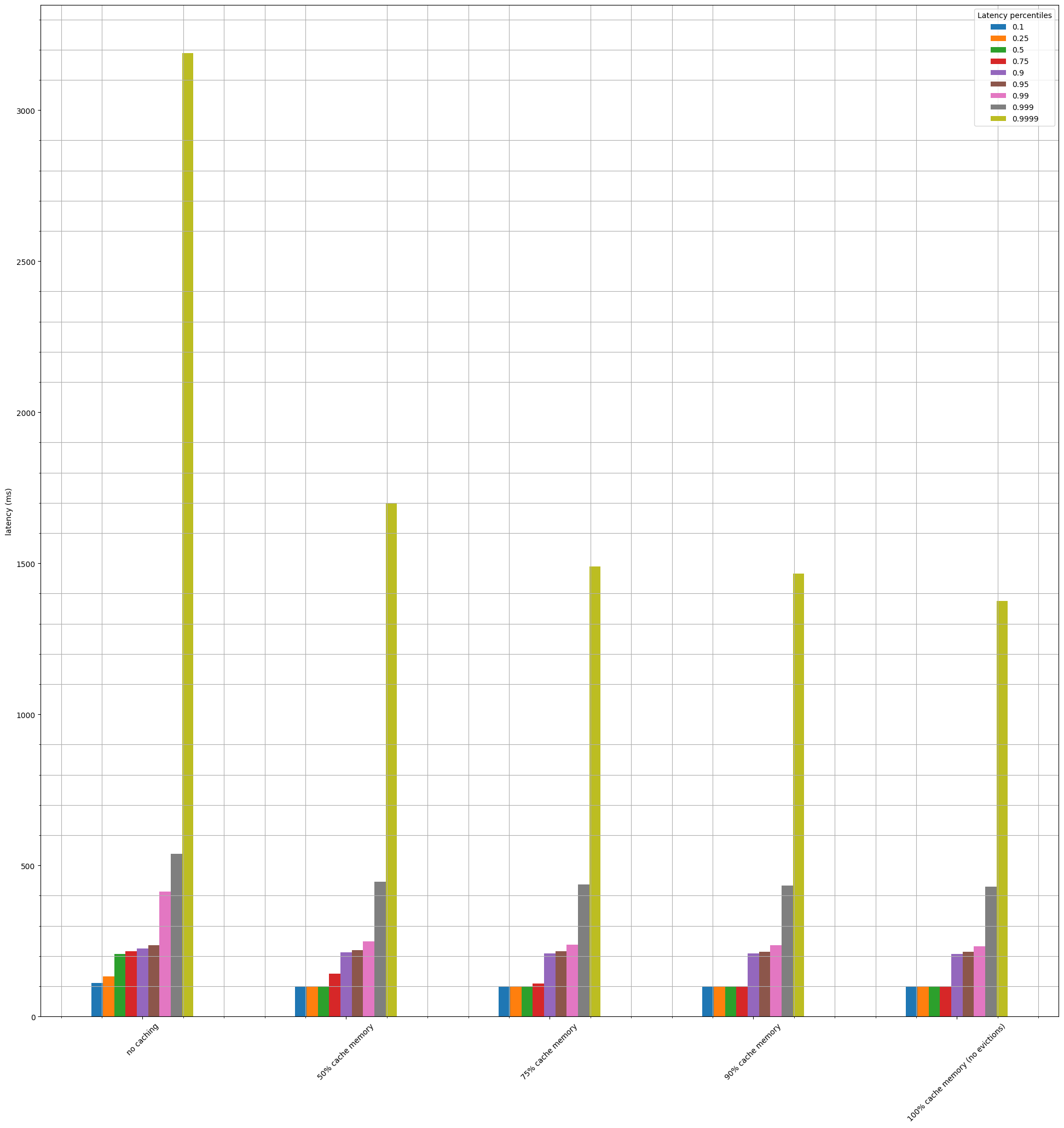
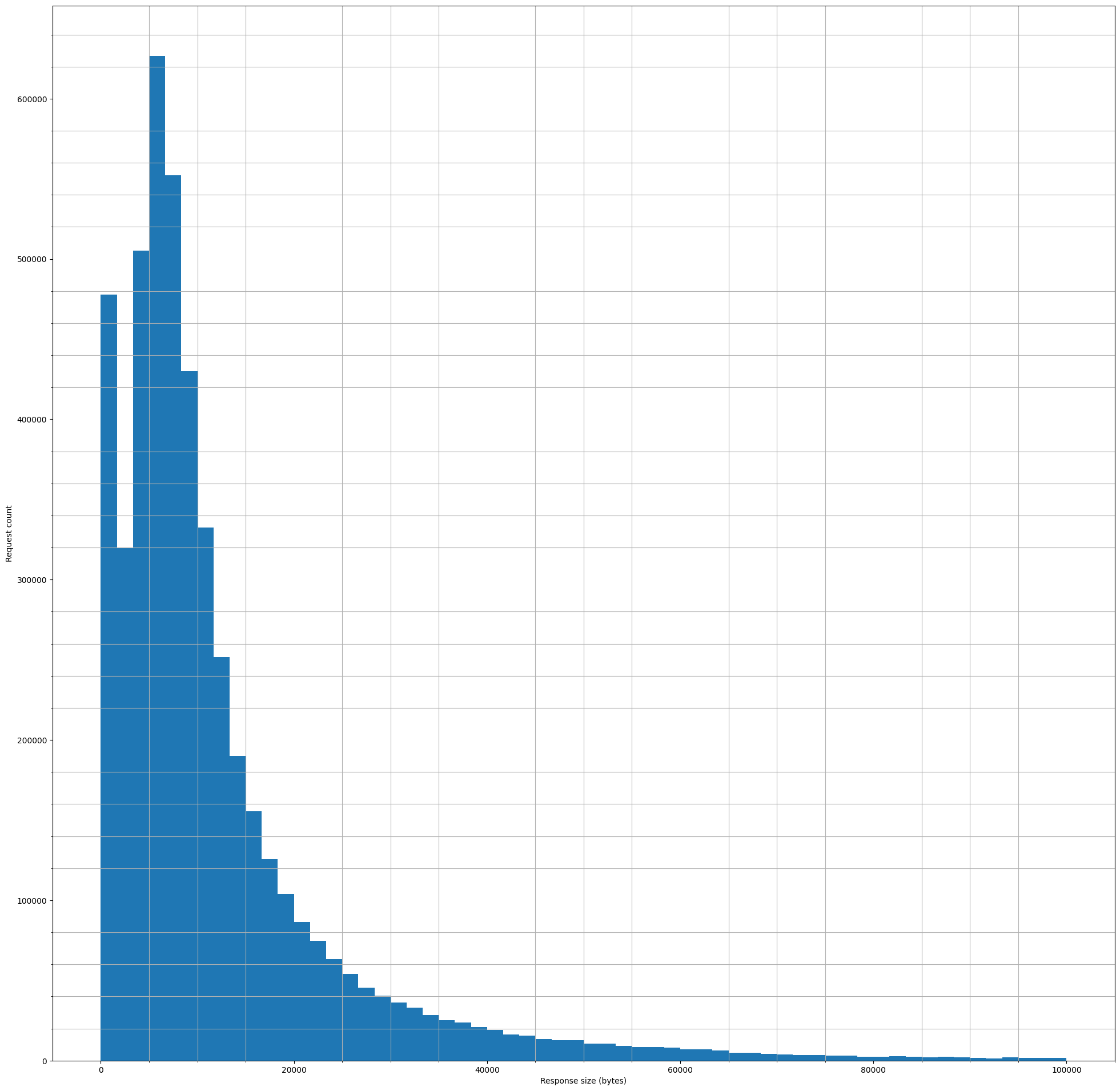
One useful analysis to undersand if and how much moving from the pregeneration model to caching is to figure out:
- What are the patterns of requests we see in our logs
- How does the cache size affects latency
Webrequest analytics is a good starting point for this investigation