[Description edited to replace previous misunderstandings]:
Right now AssembleUploadChunks jobs fail after about 3 minutes, then get retried 1 minute later despite retries on this job type being disabled. Similarly for PublishStashedFile jobs.
These jobs need a fair amount of time, because in the worst case, they may be calculating an SHA1 hash on a 5GB file, and potentially moving the file to/from Swift. 3 minutes is way too short. 10-20 minutes would be a more reasonable timeout.
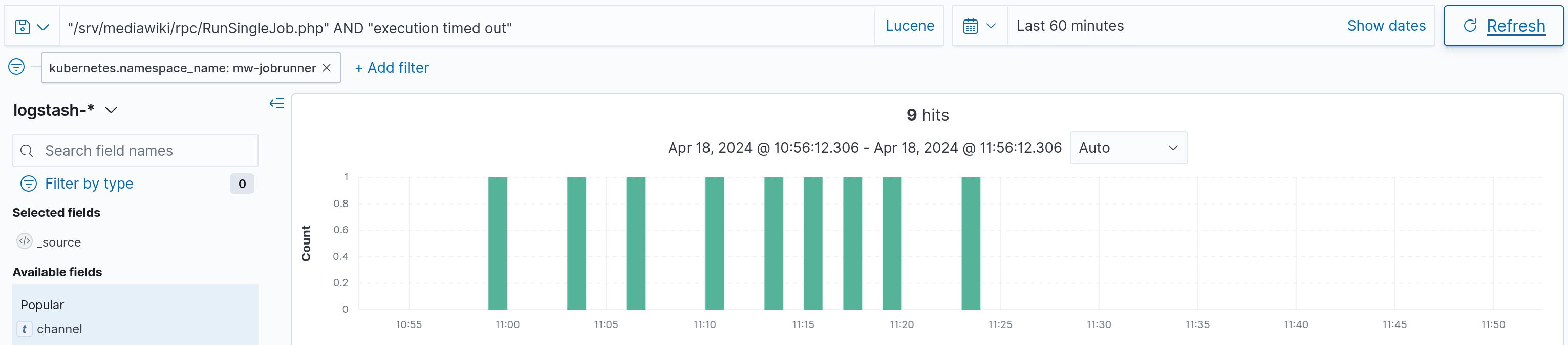
I think the retry happens because the "no retry" code lives in EventBus\JobExecutor, which is run from rpc/RunSingleJob.php. It works by marking failed jobs that cannot be retried as success. If the HTTP connection dies due to a timeout, this error is never communicated to the change-propogation service, so it sees this as a failure and retries the job.
I believe this points to the HTTP request being killed after 3 minutes. job queue MW is configured to have a $wgRequestTimeLimit of 1200, so we should really have the HTTP timeout be higher than that, so MW can properly communicate errors.
It seems like k8s has the service mesh configured to have a default timeout for MediaWiki of 180 seconds. change-propogation has a default timeout of 7 minutes.
An example of such a case is request id of 9b4b9d1e-6a32-4591-8f72-89af061843b6