Apparently unsampled API logs were disabled by Ori in December, and XFF logs were disabled by Reedy in January. I don't understand how we can respond to abuse and DoS attacks without these logs.
When we bought Fluorine, it was sized so as to have a sufficient disk I/O to store unsampled Apache access logs with a short retention time: https://rt.wikimedia.org/Ticket/Display.html?id=2400 . Unfortunately this was never implemented -- it would still be useful in my opinion. Instead, we stored XFF and API logs, and tuned the retention time of the API logs so that they fit on the disk.
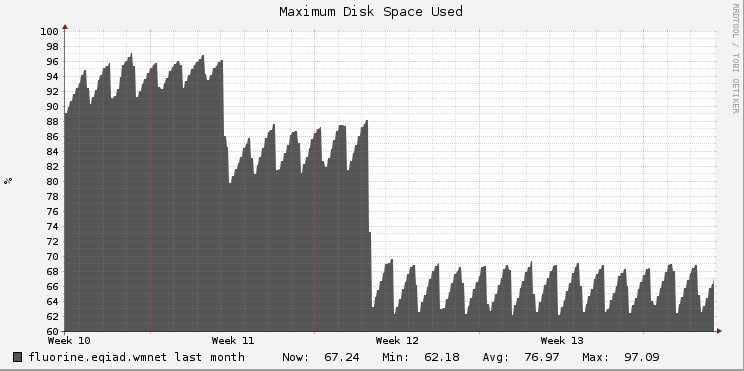
If the API logs stop fitting on the disk on fluorine, the first thing to try should be to reduce the retention time. This is currently 30 days, see files/misc/scripts/mw-log-cleanup in puppet.
If fluorine is now so undersized, 2.5 years on, that we can't even store 7 days of API access logs, then we should buy new hardware for it.