Downtimed, silence ID e5915daa-08f1-45f6-b805-fee5078d64da
Feed Advanced Search
Today
Today
Clement_Goubert added a comment to T363086: ManagementSSHDown parse1002.eqiad.wmnet.
Yesterday
Yesterday
Clement_Goubert added a comment to T348284: Handle sidecar containers in one-off Kubernetes jobs.
I've uploaded a patch to bump the memory limit to 1G, since I've seen it spike up to 980M.
Wed, Apr 24
Wed, Apr 24
Clement_Goubert added a comment to T348284: Handle sidecar containers in one-off Kubernetes jobs.
Clement_Goubert updated the task description for T362323: Move 100% of external traffic to Kubernetes (excluding Votewiki and Commons).
Tue, Apr 23
Tue, Apr 23
Clement_Goubert updated the task description for T362323: Move 100% of external traffic to Kubernetes (excluding Votewiki and Commons).
Fri, Apr 19
Fri, Apr 19
Clement_Goubert closed T358308: AssembleUploadChunksJob & PublishStashedFile jobs seem to be timing out at about 3 minutes, but should be ~20 minutes as Resolved.
Marking this resolved as you just confirmed a big file upload going through correctly. Thanks for your help in debugging this!
Clement_Goubert closed T358308: AssembleUploadChunksJob & PublishStashedFile jobs seem to be timing out at about 3 minutes, but should be ~20 minutes, a subtask of T200820: FAILED: stashfailed: Could not read file "mwstore://local-swift-eqiad/local-temp/a/ac/15xi9btm14os.u9p1dr.1208681.webm.0"., as Resolved.
Clement_Goubert closed T281261: Update grafana link for mediawiki-error-rate-$cluster in icinga check as Invalid.
Yes, alert was moved to https://gerrit.wikimedia.org/r/plugins/gitiles/operations/alerts/+/refs/heads/master/team-sre/mediawiki.yaml#159 with the correct dashboard.
Clement_Goubert added a comment to T362938: Degraded RAID on mw2382.
I suppose that can be hotswapped? Let us know if it can't, we'll drain and cordon the host for the disk swap.
Thu, Apr 18
Thu, Apr 18
Clement_Goubert added a comment to T351074: Move servers from the appserver/api cluster to kubernetes.
I abandoned the CR to move more eqiad api_appservers because it would leave only 15, 5 of them canaries. We still have a bit more margin on the appserver side in eqiad.
Clement_Goubert added a comment to T358308: AssembleUploadChunksJob & PublishStashedFile jobs seem to be timing out at about 3 minutes, but should be ~20 minutes.
Clement_Goubert added a comment to T358308: AssembleUploadChunksJob & PublishStashedFile jobs seem to be timing out at about 3 minutes, but should be ~20 minutes.
request_terminate_timeout for mw-jobrunners should now be set to 86400, as it was on bare metal.
Clement_Goubert added a comment to T358308: AssembleUploadChunksJob & PublishStashedFile jobs seem to be timing out at about 3 minutes, but should be ~20 minutes.
I think I found it
Clement_Goubert added a comment to T358308: AssembleUploadChunksJob & PublishStashedFile jobs seem to be timing out at about 3 minutes, but should be ~20 minutes.
Wed, Apr 17
Wed, Apr 17
Clement_Goubert added a comment to T362766: 2024-04-17 mw-on-k8s eqiad outage.
As an aside, and contributing to the time to recovery, we observed the apache container getting oomkilled, we strongly suppose because of the backpressure from the php-fpm workers being busy waiting for the DNS response.
Clement_Goubert added a comment to T362766: 2024-04-17 mw-on-k8s eqiad outage.
The change was rolled back in eqiad, and eqiad was repooled around 10:45. A terminating dot was added to the DNS name in codfw to avoid a recursive request.
Tue, Apr 16
Tue, Apr 16
Clement_Goubert added a comment to T358308: AssembleUploadChunksJob & PublishStashedFile jobs seem to be timing out at about 3 minutes, but should be ~20 minutes.
We can exclude a bad setting of the async trait for mw-jobrunner.
From a pod in production via shell.php
> use Wikimedia\MWConfig\ClusterConfig; > ClusterConfig::getInstance()->isK8s() = true
Clement_Goubert added a comment to T362518: Deprecate buster-backports.
The following images fail docker-reporter checks because they haven't been rebuilt on top of the new buster base image:
base images docker-registry.wikimedia.org/docker-gc:1.0.0-20230402 [FAIL] docker-registry.wikimedia.org/golang:1.14-1-20240407 [FAIL] docker-registry.wikimedia.org/httpd-fcgi:2.4.38-10-u5-20240407 [FAIL] docker-registry.wikimedia.org/kubeflow-kfserving-agent:0.6.0-1-20211017[FAIL] docker-registry.wikimedia.org/kubeflow-kfserving-controller:0.6.0-1-20211017[FAIL] docker-registry.wikimedia.org/kubeflow-kfserving-storage-initializer:0.6.0-5-20211010[FAIL] docker-registry.wikimedia.org/loki:1.5.0-2-20230604 [FAIL] docker-registry.wikimedia.org/mediawiki-httpd:0.1.8-s2-20240407 [FAIL] docker-registry.wikimedia.org/php7.2-cli:0.2.0-s3-20221204 [FAIL] docker-registry.wikimedia.org/php7.2-fpm:0.4.0-20221204 [FAIL] docker-registry.wikimedia.org/php7.2-fpm-multiversion-base:1.0.7-20221204[FAIL] docker-registry.wikimedia.org/php7.4-cli-icu67:7.4.33-1-s2-20231106-20231106[FAIL] docker-registry.wikimedia.org/php7.4-fpm-icu67:7.4.33-3-20231106-20231106[FAIL] docker-registry.wikimedia.org/wikimedia-buster:20210523 [FAIL]
Jdforrester-WMF awarded T362662: Rename X-Wikimedia-Debug k8s-experimental option a Like token.
Mon, Apr 15
Mon, Apr 15
Clement_Goubert updated the task description for T362518: Deprecate buster-backports.
Clement_Goubert updated the task description for T362518: Deprecate buster-backports.
Clement_Goubert updated the task description for T362518: Deprecate buster-backports.
Fri, Apr 12
Fri, Apr 12
Clement_Goubert added a comment to T329857: MediaWiki deploy servers should not be mediawiki installation targets.
Thu, Apr 11
Thu, Apr 11
Clement_Goubert updated the task description for T362323: Move 100% of external traffic to Kubernetes (excluding Votewiki and Commons).
Clement_Goubert updated the task description for T362323: Move 100% of external traffic to Kubernetes (excluding Votewiki and Commons).
taavi awarded T362323: Move 100% of external traffic to Kubernetes (excluding Votewiki and Commons) a Barnstar token.
Clement_Goubert updated the task description for T290536: Serve production traffic via Kubernetes.
jijiki awarded T362323: Move 100% of external traffic to Kubernetes (excluding Votewiki and Commons) a Burninate token.
hnowlan awarded T362323: Move 100% of external traffic to Kubernetes (excluding Votewiki and Commons) a Stroopwafel token.
Clement_Goubert triaged T362323: Move 100% of external traffic to Kubernetes (excluding Votewiki and Commons) as High priority.
Clement_Goubert closed T360763: Move 70% of mediawiki external requests to mw on k8s, a subtask of T290536: Serve production traffic via Kubernetes, as Resolved.
Clement_Goubert added a comment to T362316: Migrate ml-services to mw-api-int.
Aaaand I just realized they all use http and not https, so now I can change them all.
Clement_Goubert updated the task description for T362316: Migrate ml-services to mw-api-int.
Wed, Apr 10
Wed, Apr 10
Clement_Goubert added a comment to T213689: Create a readiness probe for zotero.
Clement_Goubert added a comment to T213689: Create a readiness probe for zotero.
Summing up the discussion on the patch set, this is not what is wanted, turning monitoring on in the service would turn on prometheus metrics scraping, and zotero doesn't expose any metrics. What may be wanted instead is to add a probe of type swagger to the service definition in service.yaml, but I am unsure if x-amples are needed for this to work correctly.
Clement_Goubert added a comment to T213689: Create a readiness probe for zotero.
I think it's because monitoring is disabled in the service's values.yaml
Clement_Goubert added a comment to T360636: Phase out cergen for ServiceOps services.
chartmuseum and docker-registry done
Clement_Goubert updated the task description for T360636: Phase out cergen for ServiceOps services.
Tue, Apr 9
Tue, Apr 9
Clement_Goubert updated the task description for T360636: Phase out cergen for ServiceOps services.
Mon, Apr 8
Mon, Apr 8
Clement_Goubert added a comment to T361724: scap should check if it is running within a tmux/screen.
For this use case the only keybinding you would need to know is how to exit once your run is done, which you would do the same way you exit a shell, with exit or ^+d.
Thu, Mar 28
Thu, Mar 28
Clement_Goubert updated the task description for T360763: Move 70% of mediawiki external requests to mw on k8s.
Clement_Goubert updated the task description for T333120: Migrate internal traffic to k8s.
Clement_Goubert updated the task description for T333120: Migrate internal traffic to k8s.
Clement_Goubert closed T358213: Migrate restbase from mwapi-async to mw-api-int, a subtask of T333120: Migrate internal traffic to k8s, as Resolved.
Mar 27 2024
Mar 27 2024
Clement_Goubert closed T360867: httpbb appserver test breaks deployment of the week due to a timeout parsing page as Resolved.
--retry_on_timeout merged and deployed, hopefully this makes deployments easier and closer to the tests we actually want to run.
Clement_Goubert added a comment to T358213: Migrate restbase from mwapi-async to mw-api-int.
50%
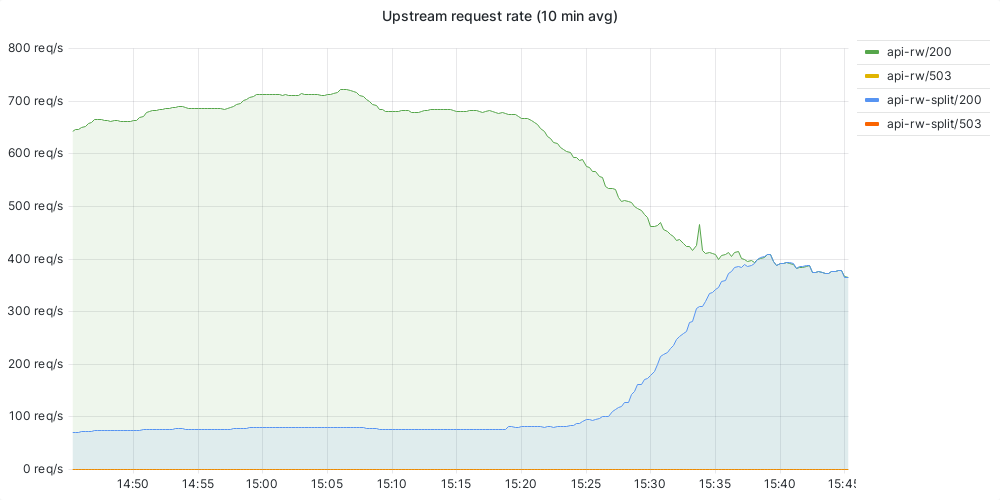
Clement_Goubert updated the task description for T358213: Migrate restbase from mwapi-async to mw-api-int.
Clement_Goubert added a comment to T358213: Migrate restbase from mwapi-async to mw-api-int.
Things to keep an eye on:
- Upstream error rate is higher on mw-api-int than bare-metal
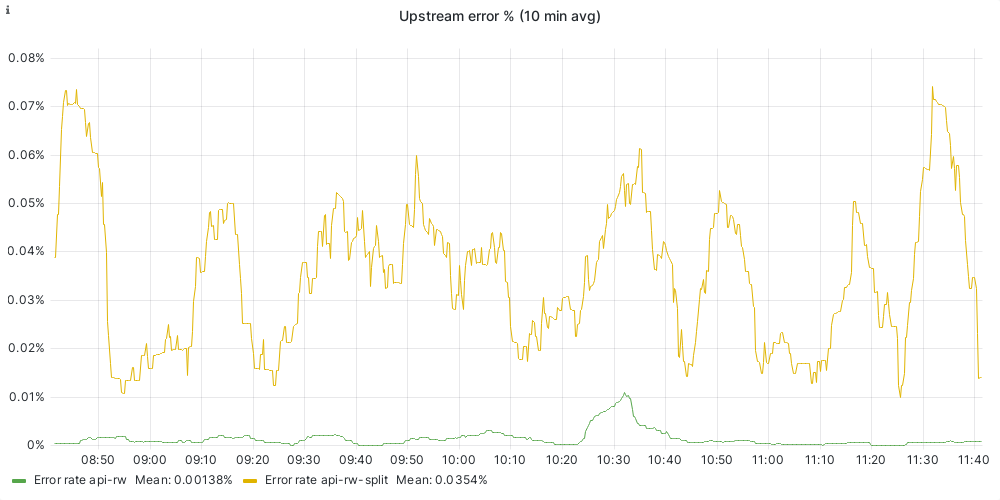
- Connection establishment time is way higher on mw-api-int
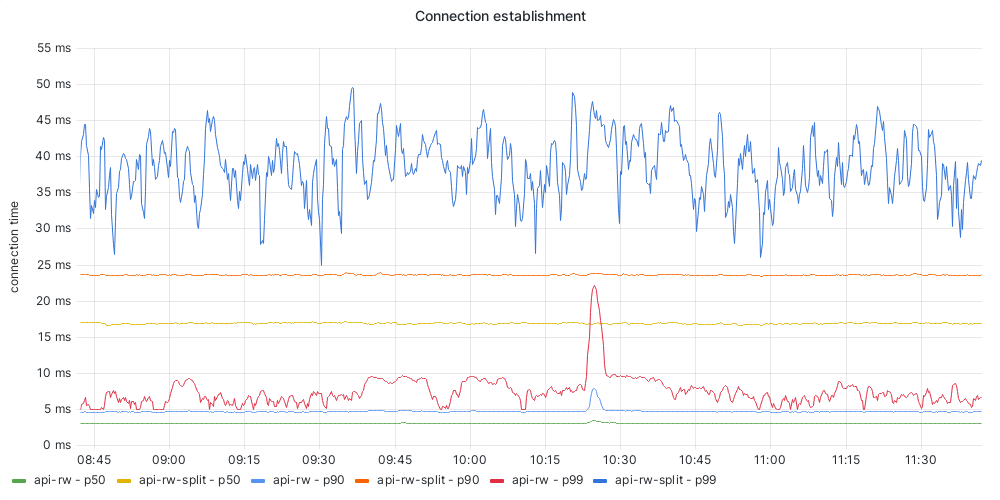
- Upstream latencies are consistently higher on mw-api-int
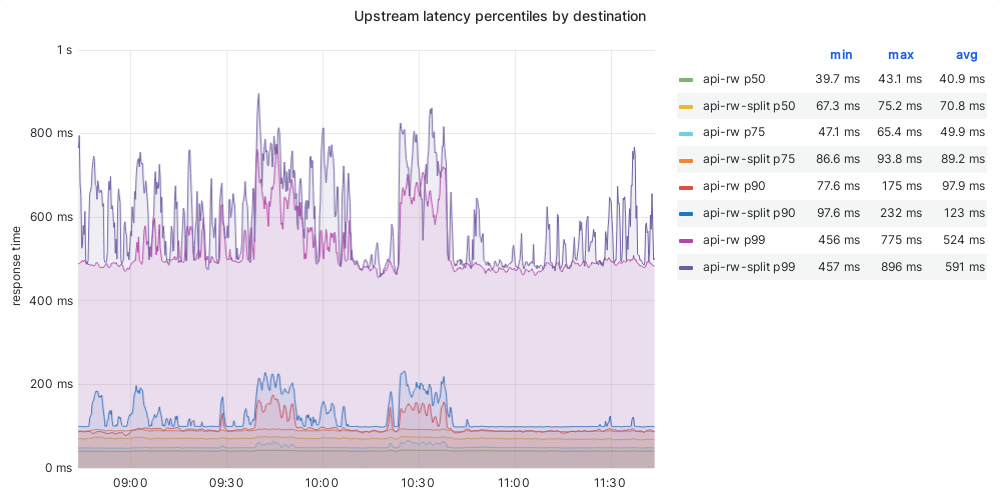
Clement_Goubert added a comment to T361024: NEW BUG REPORT SSL certificate verification error when using internal API endpoints from conda-analytics and Jupyter on stat host.
It wouldn't fix it for anything but conda-analytics but you could add that environment variable to /opt/conda-analytics/etc/profile.d/conda.sh?
Clement_Goubert updated subscribers of T360867: httpbb appserver test breaks deployment of the week due to a timeout parsing page.
Some context given by @RLazarus from the CR:
At the time we added this test, the Barack Obama page did consistently load within the default timeout, and we wanted a test to make sure that remained true. Being "notoriously slow" is exactly the reason we picked it.
Have we decided it's okay for that page to take longer now? If so, we might as well just delete this test rather than bumping the timeout; there's no other reason to keep it around. If not, we should keep the test and fix it so that it passes.
Mar 26 2024
Mar 26 2024
Clement_Goubert added a comment to T358213: Migrate restbase from mwapi-async to mw-api-int.
10% of RESTbase's backend mwapi requests are now made to mw-api-int
Clement_Goubert updated the task description for T358213: Migrate restbase from mwapi-async to mw-api-int.
Mar 25 2024
Mar 25 2024
Clement_Goubert updated the task description for T333120: Migrate internal traffic to k8s.
Clement_Goubert updated the task description for T358213: Migrate restbase from mwapi-async to mw-api-int.
Clement_Goubert closed T360767: Migrate changeprop to mw-api-int, a subtask of T333120: Migrate internal traffic to k8s, as Resolved.
Clement_Goubert added a comment to T360767: Migrate changeprop to mw-api-int.
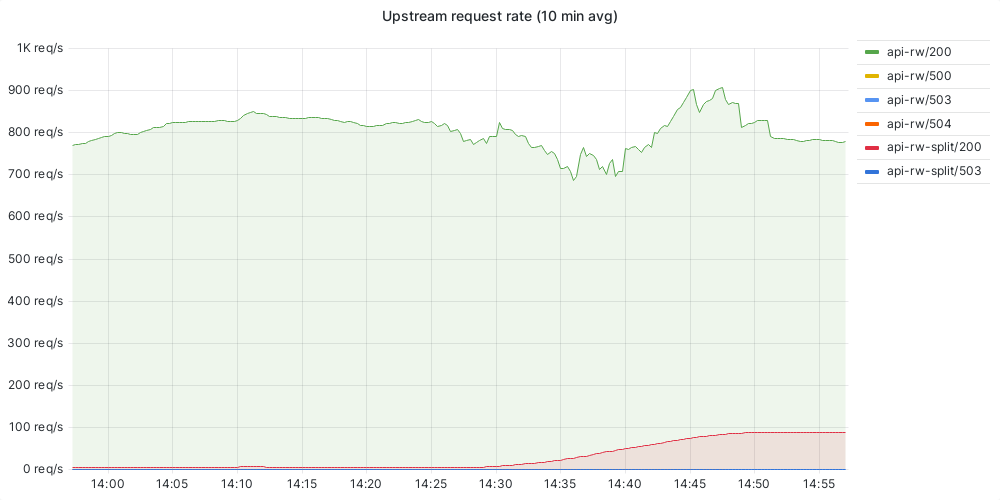
mw-api-int is now receiving all calls to mwapi_uri from changeprop
Clement_Goubert changed the status of T360767: Migrate changeprop to mw-api-int, a subtask of T333120: Migrate internal traffic to k8s, from Open to In Progress.
Clement_Goubert changed the status of T360767: Migrate changeprop to mw-api-int from Open to In Progress.
Mar 22 2024
Mar 22 2024
Clement_Goubert added a comment to T360763: Move 70% of mediawiki external requests to mw on k8s.
Given we have increased mw-web and mw-api-ext by respectively 53 and 10 replicas to cope with handling all the appserver traffic during the codfw depool part of the switchover, the first 5% increase will in my opinion not need an associated replicas increase.
Clement_Goubert updated the task description for T333120: Migrate internal traffic to k8s.
Clement_Goubert updated the task description for T333120: Migrate internal traffic to k8s.
Abandoned because the internals of changeprop make it unadvisable to add another layer. I'll create another task for its migration to mw-api-int.
Clement_Goubert closed T360625: Alter changeprop chart to use the service mesh, a subtask of T333120: Migrate internal traffic to k8s, as Declined.
Clement_Goubert updated the task description for T290536: Serve production traffic via Kubernetes.
Clement_Goubert added a comment to T360763: Move 70% of mediawiki external requests to mw on k8s.
Waiting on codfw repool as part of T357547: ☂️ Northward Datacentre Switchover (March 2024) before moving forward with this increase.
Ladsgroup awarded T360763: Move 70% of mediawiki external requests to mw on k8s a Love token.
Clement_Goubert changed the status of T360763: Move 70% of mediawiki external requests to mw on k8s from Open to In Progress.
Clement_Goubert changed the status of T360763: Move 70% of mediawiki external requests to mw on k8s, a subtask of T290536: Serve production traffic via Kubernetes, from Open to In Progress.
Clement_Goubert added a comment to T360652: imagecatalog_record.service fails due to read-only sqlite database.
Checking on deploy2002 (which we moved away from with this switchover), the catalog.sqlite files stays in place after a switchover, and is now owned by the helm user there as you mentioned in T287130#7651203
Clement_Goubert added a comment to T360625: Alter changeprop chart to use the service mesh.
That makes sense. I don't necessarily have a problem with it not using the service mesh (except for the lack of telemetry), except the fact that it means migrating it in one go to use mw-api-int as a backend.
Mar 21 2024
Mar 21 2024
Clement_Goubert lowered the priority of T360652: imagecatalog_record.service fails due to read-only sqlite database from High to Low.
As the action taken in production fixed the immediate problem, lowering priority.
Clement_Goubert added a comment to T360652: imagecatalog_record.service fails due to read-only sqlite database.
cgoubert@deploy1002:~$ sudo chown imagecatalog:imagecatalog /srv/deployment/imagecatalog/catalog.sqlite cgoubert@deploy1002:~$ sudo systemctl restart imagecatalog_record.service
Clement_Goubert triaged T360652: imagecatalog_record.service fails due to read-only sqlite database as High priority.
Clement_Goubert updated the task description for T360625: Alter changeprop chart to use the service mesh.
Clement_Goubert updated the task description for T360625: Alter changeprop chart to use the service mesh.
Clement_Goubert updated the task description for T333120: Migrate internal traffic to k8s.
Mar 19 2024
Mar 19 2024
Clement_Goubert added a comment to T357547: ☂️ Northward Datacentre Switchover (March 2024) .
Some tweaking of replicas size was needed on mw-on-k8s, which was expected as this is the first switchover where more of the external traffic goes to it than to bare-metal clusters.
Mar 7 2024
Mar 7 2024
Clement_Goubert added a comment to T358117: Adapt scap's testing strategy to mw-on-k8s.
@dancy Thanks a bunch! \o/