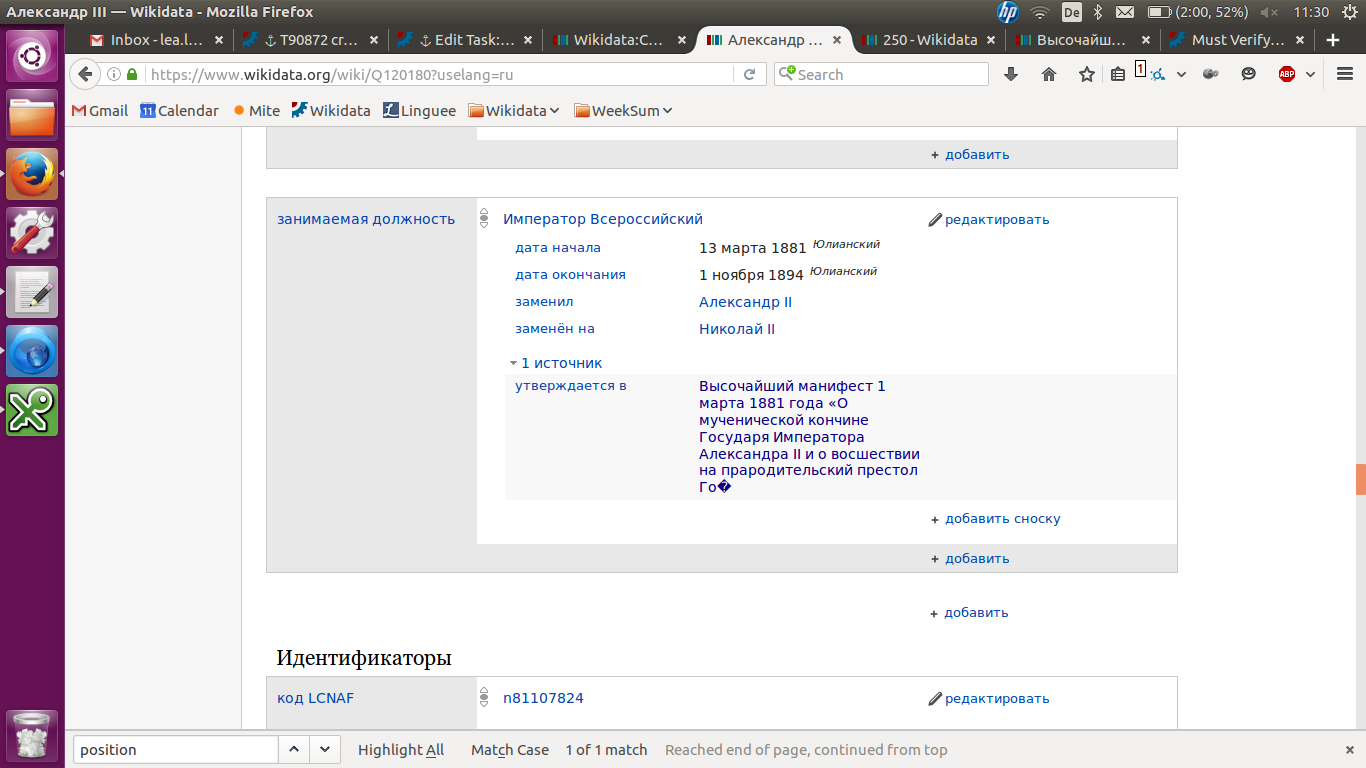
On the russian UI of Q120180, in position held property (P39) (занимаемая должность), the reference label for Q19180760 is trimmed.
| Lea_Lacroix_WMDE | |
| Aug 11 2016, 9:27 AM |
| F4353116: Screenshot from 2016-08-11 11:37:15.png | |
| Aug 11 2016, 10:14 AM |
| F4353106: Screenshot from 2016-08-11 11-30-49.png | |
| Aug 11 2016, 9:31 AM |
On the russian UI of Q120180, in position held property (P39) (занимаемая должность), the reference label for Q19180760 is trimmed.
| Subject | Repo | Branch | Lines +/- | |
|---|---|---|---|---|
| Fix truncated terms on the fly | mediawiki/extensions/Wikibase | master | +19 -4 |
| Status | Subtype | Assigned | Task | ||
|---|---|---|---|---|---|
| Invalid | None | T142691 [Bug] wb_terms table truncates labels exceeding 255 bytes, possibly leaving invalid UTF-8 | |||
| Resolved | thiemowmde | T142820 [Task] Decide on quick fix for "Max length of reference label in russian" |
There are multiple things to consider here here:
Yes, we had a similar problem with ips_site_page which we solved that way: T99459: ips_site_page is too short to store some (full) page titles.
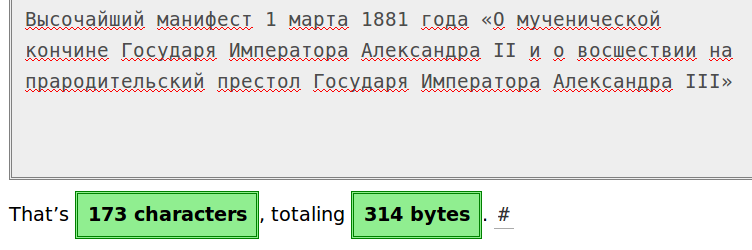
We have 2133 affected terms:
MariaDB [wikidatawiki_p]> SELECT COUNT(*) FROM wb_terms WHERE LENGTH( term_text) > 254; +----------+ | COUNT(*) | +----------+ | 2133 | +----------+ 1 row in set (8 min 15.88 sec)
Some quick notes:
In repo/sql/Wikibase.sql, this is declared as term_text VARCHAR(255) BINARY NOT NULL, which is NOT the same as VARBINARY. VARCHAR(255) BINARY should use binary collation for UTF8 data, any would allow 255 unicode characters to be stored. The field was apparently changed to VARBINARY during deployment, possibly for backwards compat with MySQL4.
How ever we work around the issue that this field is VARBINARY(255) on the live system, we should strip any broken UTF8 from the end of the string, using StringNormalizer::removeBadCharLast.
Change 306253 had a related patch set uploaded (by Daniel Kinzler):
Fix truncated terms on the fly
It's VARBINARY in both my local database and on the live system (we can see it truncates at 255 bytes). I don't know how this happened. I assume the meaning of VARCHAR BINARY changed. It appears this was an alias for VARBINARY in the MySQL versions we use.
Here is an example search: https://www.wikidata.org/w/api.php?action=wbsearchentities&search=%D0%92%D1%8B%D1%81%D0%BE%D1%87%D0%B0%D0%B9%D1%88%D0%B8%D0%B9+%D0%BC%D0%B0%D0%BD%D0%B8%D1%84%D0%B5%D1%81%D1%82+1+%D0%BC%D0%B0%D1%80%D1%82%D0%B0+1881+%D0%B3%D0%BE%D0%B4&format=json&language=ru&uselang=ru&type=item. Note that the search result ends with \ufffd. This should be stripped, as @daniel suggests.
During story time we found that:
We said that we will, for now, solve this bug by implementing the "fallback" workaround described in T142691#2543325.
Given that it is only a problem in a small number of cases let's not spend time on the workaround and instead work on the proper fix long-term. That's what we also said in story time.
Could be relevant: I was able to create a item with 810 characters (https://www.wikidata.org/wiki/Q26903397), but I can't add more labels with that length. https://www.wikidata.org/wiki/Q2732136#P734 shows the broken display as described in this ticket.
The proper long term fix for this one is killing the wb_terms table.
Tagging T198866 as related.