Also proposed in Community-Wishlist-Survey-2016. Received 53 support votes, ranked #20 out of 265 proposals. View full proposal with discussion and votes here
Han-characters are widely used in East Asia (China, Taiwan, Singapore, Malaysia, Hong Kong, Japan, Korea, Taiwan and Vietnam). An enduring problem unsolved for digital archiving is "lacking of characters". Not only for characters in ancient books, even modern publications lacks for characters ( i.e. Some authors may created 300-400 unique new characters in certain books). It's difficult to deal when we archive them into WikiSource. Unicode gradually add new characters into the chart, but new Uni-han extension always takes time to go live. In the past WikiSource, even Wikipedia, used to deal this problem with image files to present those characters. But images cannot be indexed, unsearchable, even not exchangeable between computer systems.
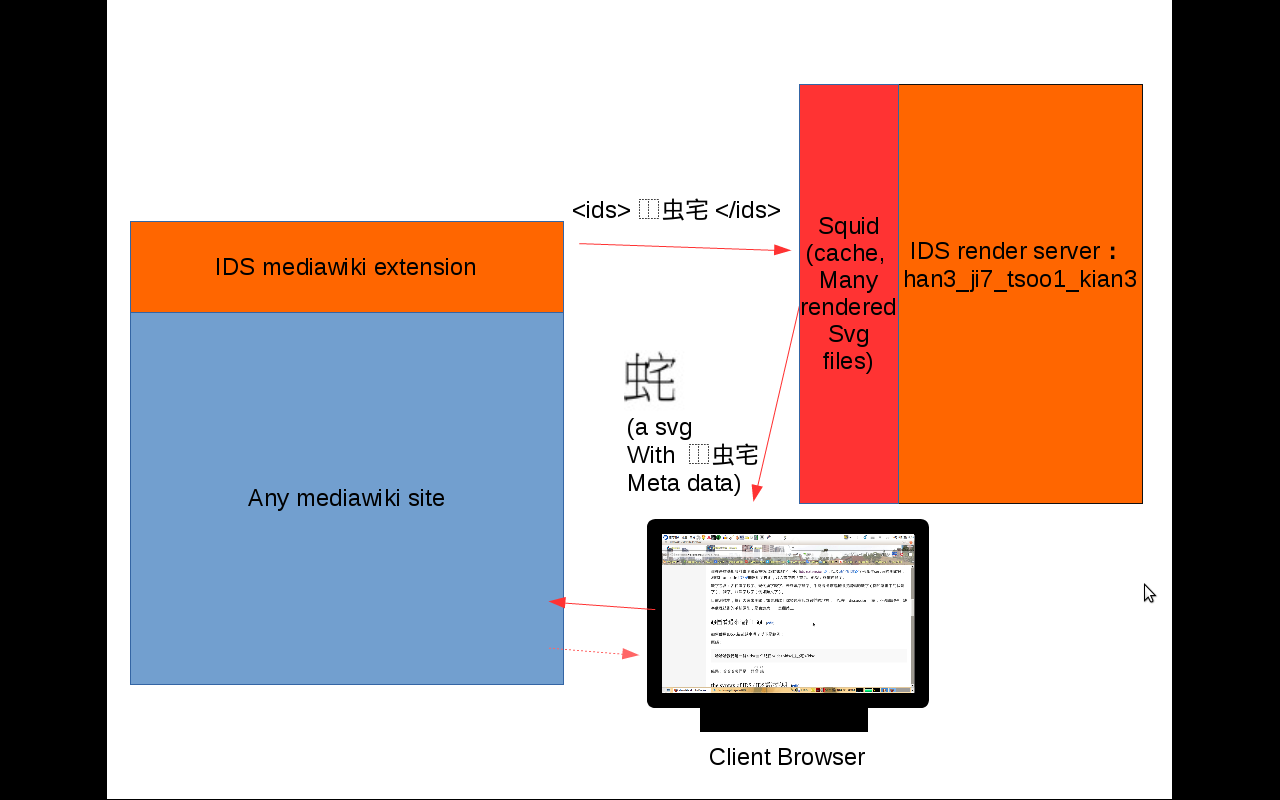
Unicode IDS - Ideographic Description Sequence - defined how to composite Han character with components. We implement the function to dynamically render Han character with Ideographic Description Sequences (IDS) and extension in WikiSource like: <ids>⿺辶⿴宀⿱珤⿰隹⿰貝招</ids> It will generate a Han character image file (now rendered on the temporary server on wmflabs ) with IDS in metadata. This is a solution to resolve lacking of Han characters problem on all C/J/K/V books. The basis is that Han characters are not as the same level as European alphabets, but words. Han characters are an open set. They are composited on 2 dimension by more basic components which owns basic element, like "affix" in English (English words are composite on 1 dimension). In academies, components based Han character composite technology are developed and adapted to handle ancient Han books. The most famous are Academia Sinica's development and cbeta Sutras plan. Recent years, opensource IDS renders are developed stable, so we can use the same technology to benefit Wikisource for handling Han ancient books as the same as those academies.