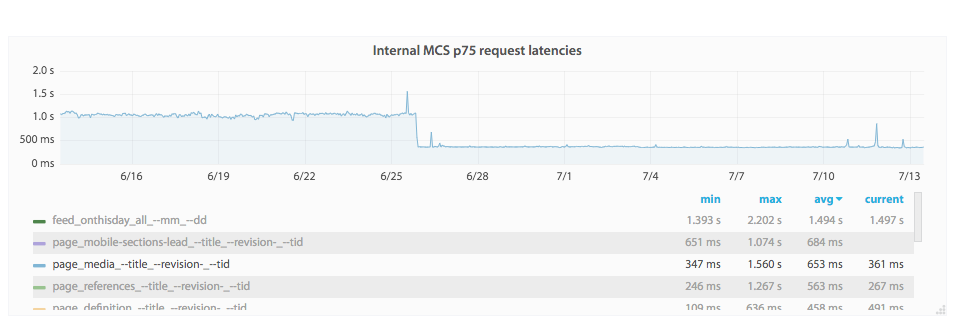
The media endpoint (T177430) is deployed, but it is quite slow. This task is to improve its performance.
ab -c 10 -n 100 http://mobileapps.svc.codfw.wmnet:8888/en.wikipedia.org/v1/page/media/Barack_Obama Concurrency Level: 10 Time taken for tests: 19.425 seconds Complete requests: 100 Failed requests: 0 Total transferred: 10906700 bytes HTML transferred: 10818200 bytes Requests per second: 5.15 [#/sec] (mean) Time per request: 1942.543 [ms] (mean) Time per request: 194.254 [ms] (mean, across all concurrent requests) Transfer rate: 548.31 [Kbytes/sec] received
ab -c 10 -n 100 http://mobileapps.svc.codfw.wmnet:8888/en.wikipedia.org/v1/page/media/Russia Concurrency Level: 10 Time taken for tests: 18.794 seconds Complete requests: 100 Failed requests: 0 Total transferred: 18715500 bytes HTML transferred: 18627000 bytes Requests per second: 5.32 [#/sec] (mean) Time per request: 1879.434 [ms] (mean) Time per request: 187.943 [ms] (mean, across all concurrent requests) Transfer rate: 972.47 [Kbytes/sec] received