I might be late to the party, but I'm told nobody from the Italian community has flagged it yet: as late as yesterday, I was still being redirected from some it.wiki pages (on the mobile site at least) to https://it.wikipedia.org/wiki/Wikipedia:Comunicato_3_luglio_2018 . On the wikis which set up redirects of some kind, it may be worth purging the whole cache, possibly by increasing $wgCacheEpoch.
Description
Description
Details
Details
Related Objects
Related Objects
- Mentioned In
- T223408: Page gets redirected randomly to former blackout page
T206496: Create sitemaps for Indonesian, Portuguese, Punjabi, Dutch, and Korean Wikipedias
T198890: Develop an easy way for wikis to create a blackout protest
T203228: Review and deploy Blackout extension
T198965: Create XML sitemaps so search engine crawlers can crawl more effectively
T202910: add performance team members to webserver_misc_static servers to maintain sitemaps
T202643: Determine if creation of Italian Wikipedia sitemaps increased traffic from search engines
T201350: Access to dumps servers - Mentioned Here
- T202643: Determine if creation of Italian Wikipedia sitemaps increased traffic from search engines
T93550: Fix canonical URL issues (tracking)
T99587: Make the Mobile site more discoverable by search engines
T15693: Dump the article titles lists (all-titles-in-ns0.gz) every day
T23919: Write and implement Google News SiteMaps (GNSM) extension for Wikinews
T46069: Configure and setup GoogleNewsSitemap on all wikinews projects
T65098: Sitemap doesn't count language variant entries against the url_limit, causing it to be rejected
T79412: Enable sitemaps on commons.wikimedia.org
T158506: Add a sitemap with all indexable placeholders on cywiki (Welsh Wikipedia)
T193052: Provide web crawler data logs to Go Fish Digital
T198965: Create XML sitemaps so search engine crawlers can crawl more effectively
T87140: Regularly run GenerateSitemap.php on Farsi Wikinews to improve Google crawling
T101486: Delete / decom sitemap.wikimedia.org
T195544: [Regression pre-wmf.6] UI for dialogs with multiple tabs in VE is broken, but the problem is rare and intermittent
Event Timeline
There are a very large number of changes, so older changes are hidden. Show Older Changes
Comment Actions
For the record, IP and registered users are still reporting this issue from mobile. I don't know how many links are involved, but the landing page is getting about 200.000 views per day...
Comment Actions
@Deskana @dr0ptp4kt I've been pointed to the two of you as people who have access to Google Search Console (Webmaster Tools) for wikipedia.org domains. If that's true, would you be able to help out here? (And if not, do you know who would have that access?)
Comment Actions
@Imarlier I don't have access to Google Webmaster Tools any more, nor was I particularly competent with it even when I did! Sorry!
Comment Actions
@dr0ptp4kt within Search Console/webmaster tools, there should be a way to tell Google that it needs to remove cached links and reindex a domain. In this case, we need that done for it.m.wikipedia.org.
If you're not able to, no worries - I'll figure out what I need to do to get access
Comment Actions
Here's what I know at this point:
- Google did, in fact, last index it.m.wikipedia.org on July 5th, which was the day that the redirect was active.
- In order to force a re-index on the entirety of the it.m.wikipedia.org domain, I need to submit a sitemap for that domain to Google.
- The sitemap needs to be hosted on the it.m.wikipedia.org domain
- We don't currently provide sitemaps on a per-domain basis, at least as far as I can tell. T101486 eliminated sitemap.wikimedia.org, which was just a CNAME for dumps.wikimedia.org. And T87140 requests that sitemaps should be available for wikis, but hasn't been resolved.
Generating a sitemap file is pretty trivial, based on the *-latest-all-titles.gz on dumps (eg, https://dumps.wikimedia.org/itwiki/latest/itwiki-latest-all-titles.gz) so one option might be generating daily-ish and hosting them there, with appropriate varnish rules to route traffic that's incoming to the appropriate path. @BBlack
and @ArielGlenn would have more idea than I what the implications are, or how difficult it would actually be.
Comment Actions
@dr0ptp4kt @Dzahn or others: Any chance of also giving me access to it.wikipedia.org (as opposed to just the mobile site)? As I've been looking at this, I've been realizing that the problem is likely there, since most *.m.wikipedia.org entries are excluded from Google's index (on the basis of the <link rel='canonical'> tag that points back to the non-mobile wiki.)
Comment Actions
Update to the ticket: webmaster console access has been provided to Ian for https://it.m.wikipedia.org/ and https://it.wikipedia.org/ for investigation/remediation.
Comment Actions
Google gets updates from us more than once a day; I don't know how their update pipeline works, but they certainly have or could have access to the data more or less live. We should talk to them and find out where the problem is.
Comment Actions
There's conflicting information about how Google updates their index. On the one hand, they appear to use ChangeProp and ask Parsoid for content directly (see T198965#4438037), but on the other hand there appears to be extensive crawling happening (crawlers account for ~9 GB of compressed page view data for roughly four days of traffic, see T193052). I've not been able to get to the bottom of how they're actually doing things.
Comment Actions
This isn't about search engine optimisation in the strictest sense, but the tag still seems somewhat relevant.
Comment Actions
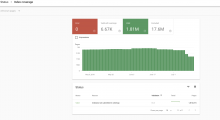

@ArielGlenn @Deskana AFAICT, they're using ChangeProp to update the info box (and possible other indexes, like Google Assistant). But they're using their crawler to update the search index.
There isn't a good way to enumerate all of the URLs on a given domain via the Search Console, not surprising considering that it.wikipedia.org has around 20m URLs total. But I can see that lots of what's there was last crawled on 7/5-7/7, which includes the period during which the protest redirect was live.
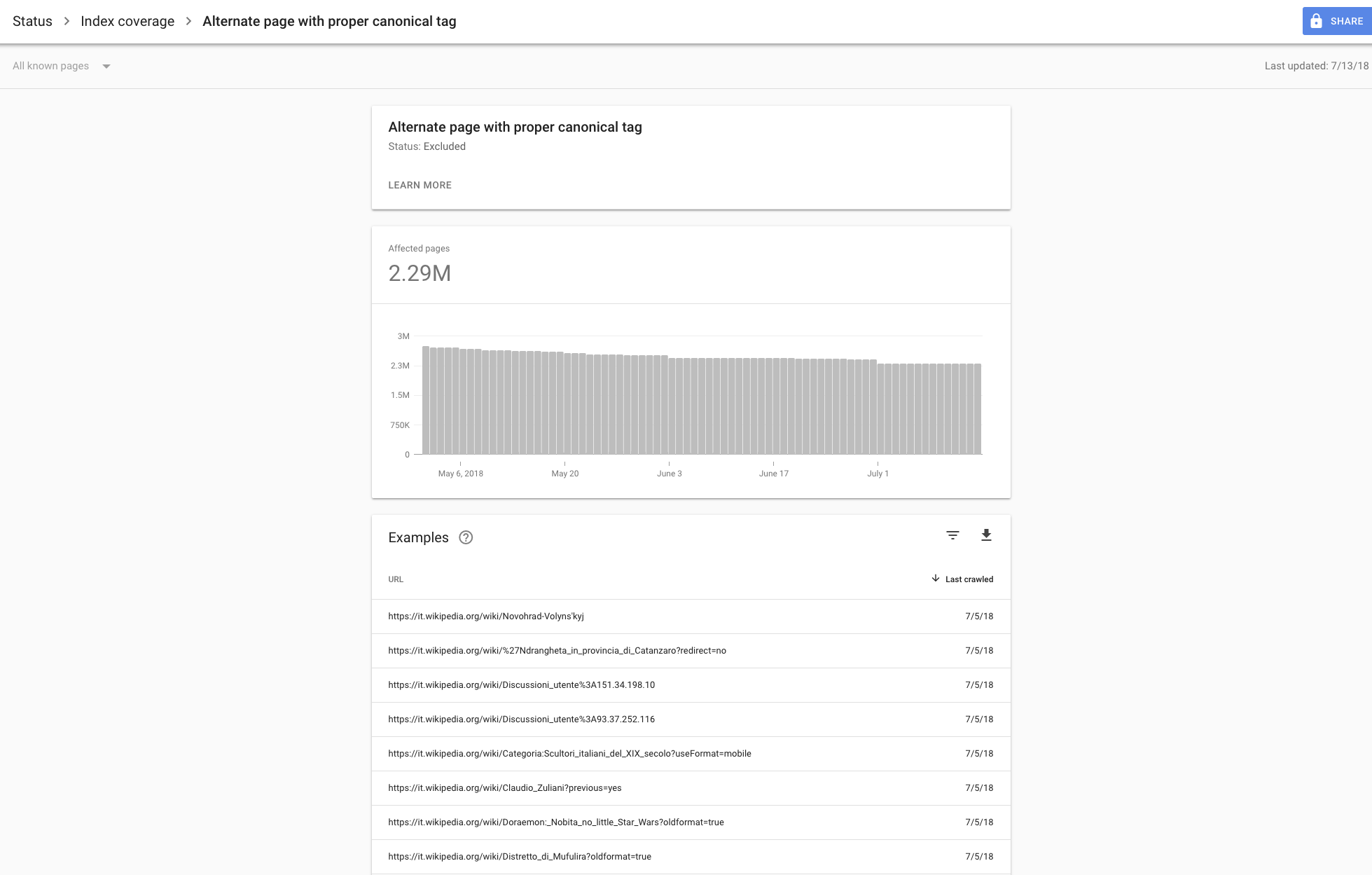

I can also see that there was a very significant drop in the number of valid URLs indexed by Google on both it.wikipedia.org and it.m.wikipedia.org, right around the same time:

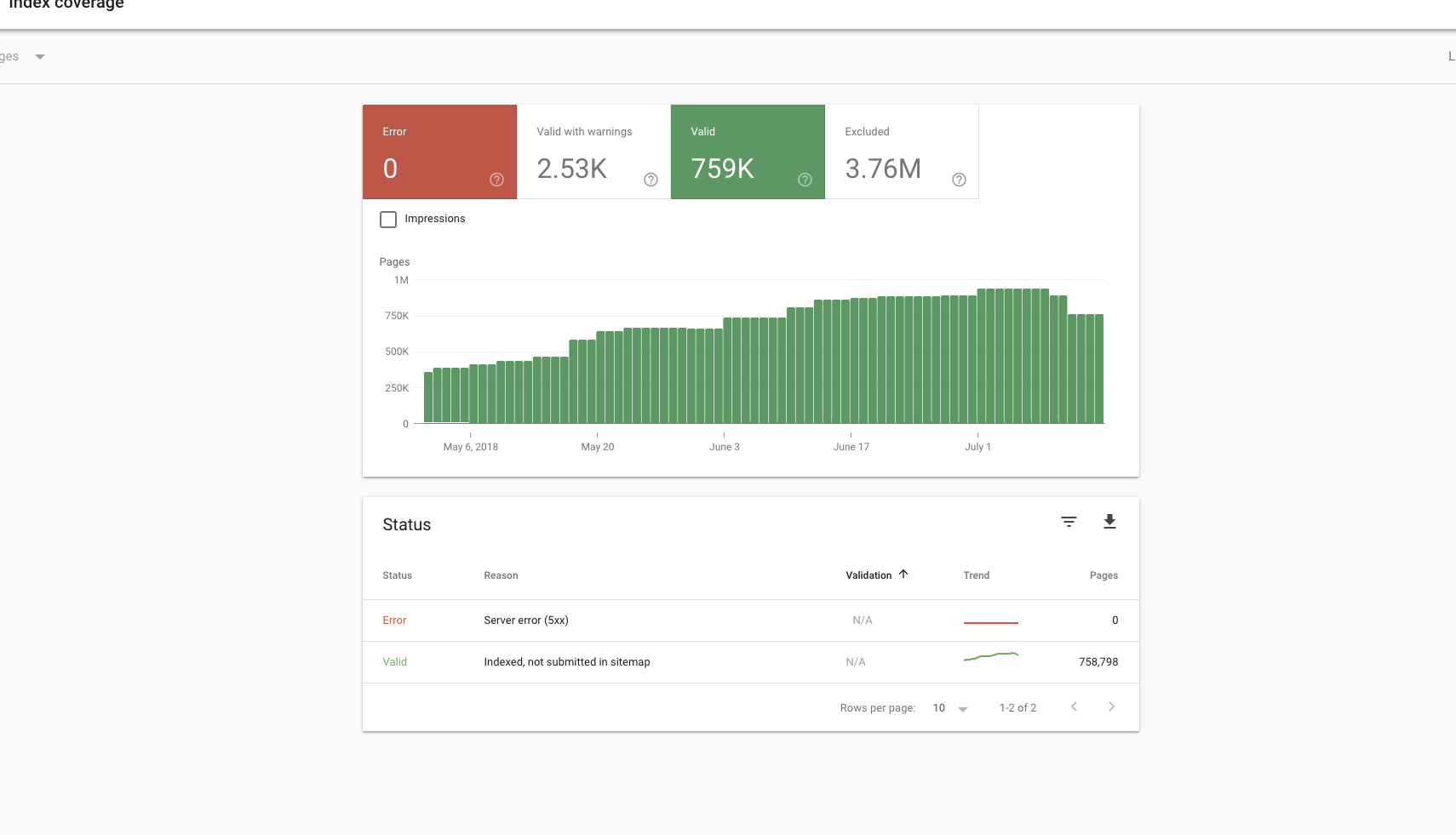
At the moment, I don't have a better plan than to see about generating sitemaps and submitting those. The big issue is that they need to be hosted on the same domain that's being indexed.
Comment Actions
So apparently Google detects JS based redirects these days. I also suspect that the destination having <link rel="canonical" href="https://it.wikipedia.org/wiki/Wikipedia:Comunicato_3_luglio_2018"> probably made this significant worse (basically unifying all those urls into one big bucket)
I think a lesson learned here, is that somehow we should be using a 302 tmp redirect for protests like this ? Or maybe we should ask Google to interpret location.href redirects as 302-style redirects instead of 301s ?
Comment Actions
@fgiunchedi @Joe @Dzahn @herron - Casting a wide net here, as I'm not sure who the right individual person for this question would be, I'm hoping that one of you can either answer, or can point me in the right direction...
My current plan is to solve this by
- Generating sitemaps on mwmaint1001. This is straightforward to do by hand, as is the puppet work to automate that.
- Shipping those sitemaps somewhere that is publicly available
- Creating appropriate VCL to route https://<domain>/sitemap.*.xml to that service. Since sitemaps need to be served from the same domain as the mapped URLs, varnish will have to proxy the connection.
An example of this in action would be a request for https://it.wikipedia.org/sitemap.xml -> http://sitemap1001.eqiad.wmnet/it.wikipedia.org/sitemap.xml
The two questions that I'm currently trying to answer:
- Is there an existing server that would be an appropriate storage location for the generated sitemaps? It doesn't need to be at all fancy, it just needs to have enough disk to hold the generated files, and it needs to be accessible to varnish via HTTP(s).
- Is there existing infrastructure for shipping files from mwmaint to other servers?
Any thoughts appreciated.
Comment Actions
@BBlack Somewhat random, but does varnish have the ability to translate domains to wiki IDs? eg, could Varnish translate "it.wikipedia.org" to "itwiki"? Or does it just know the domain?
Comment Actions
Agreed, the maintenance script seems to be there, just needs to be added to puppet properly along the other maintenance crons.
- Shipping those sitemaps somewhere that is publicly available
I think https://dumps.wikimedia.org/ may be the right place. They are public, they are made to store generated files, and i think in the distant past they already did host sitemaps but then that was stopped for some reason.
Note we once had sitemap.wikimedia.org but it was decom'ed because at that point it was merely a redirect to dumps but didn't have the actual files anymore. --> T101486
T15693#172744 shows that ten years ago this was hosted on https://dumps.wikimedia.org/sitemap/
cc: @ArielGlenn
The two questions that I'm currently trying to answer:
- Is there an existing server that would be an appropriate storage location for the generated sitemaps? It doesn't need to be at all fancy, it just needs to have enough disk to hold the generated files, and it needs to be accessible to varnish via HTTP(s).
As above, maybe dumps servers can be used and fulfull the criteria and have been used before. Alternatively there are also the dedicated VMs for releases.
- Is there existing infrastructure for shipping files from mwmaint to other servers?
I would suggest puppetizing that with the use of the rsync::quickdatacopy class.
About sitemaps also see: T79412 T65098 T79412 T198965 T158506 T87140 T46069 T15693 T23919 they are all related in one way or another i think.
Comment Actions
Varnish does not have this mapping, and overall we're actually moving toward slowly avoiding use of dbnames in public interfaces.
Years ago when we served load.php from a custom domain, we used the same URL pattern as you propose above, which sounds good to use here as well. E.g. "bits.wikimedia.org/en.wikipedia.org/load.php".
That naturally brings up the opposite, which is that we need the canonical hostname from a maintenance script, possibly for other wikis in the same group as well – that is possible through the SiteConfiguration/wgConf object.
Comment Actions
Thank you all for the investigation. The amount of indexed URLs seems worth acting on. Working on the sitemap might not be the ultimate solution but seems a good idea to me, because it's something we can use more generally (e.g. ArticlePlaceholder, T158506).
Comment Actions
@Krinkle Good answer, both in terms of the information that I now have, and the fact that it appears that we're moving in a direction that I'd personally prefer.
The fact that the canonical domain is available from SiteConfiguration/wgConf is great, but I'm not entirely sure how to make use of that. I can think of a couple of options though, and I'm curious if anyone on this ticket has opinions between them.
For each wiki (presumably gathered from all.dblist, for lack of a better idea):
- Generate the sitemap using a command like this: /usr/local/bin/mwscript maintenance/generateSitemap.php --wiki=fiwikivoyage --fspath=/tmp
- Figure out the domain
- If there's some kind of a generic script that would let me feed in the dbname and get back the domain, use that
- Alternately, the domain of every URL in the generated sitemap should (by definition) be the same. So I could also just look at one of the sitemaps, look for the first URL, and use the domain provided there
- Move the generated files to the dumps host (as suggested by @Dzahn ), or another location if there's one that's preferred.
If no one has a good solution to 2A, I'll probably just proceed with 2B -- it's trivial to parse out the domain, and the data format and restrictions on it are so strict that it can be counted on.
Thoughts?
Comment Actions
For crons of this kind, we tend to use foreachwiki, or mwscriptwikiset. I've added documentation to https://wikitech.wikimedia.org/wiki/Wikimedia_binaries. There are examples in Puppet.
For the other two things, here's something to start with:
krinkle at mwmaint1001.eqiad.wmnet in ~ $ echo 'echo $wgServerName;' | mwscript eval.php --wiki=test2wiki test2.wikipedia.org ## or $ mwscript getConfiguration.php --wiki=test2wiki --settings=wgServerName --format=json {"wgServerName":"test2.wikipedia.org"}
However, a subprocess to get that makes it harder to put cleanly in a single command. We may want to consider adding an option to maintenance/generateSitemap.php to support a mode where it would use a sub-directory named after wgServerName (instead of a shared directory with a file named after wgDBname).
Comment Actions
I'm going to start with the simple case, I'll make it more complicated later. Your one-liner makes it easy:
for wiki in $(foreachwiki):
domain=$(echo 'echo $wgServerName;' | mwscript eval.php --wiki=${wiki})
do normal things....Comment Actions
I am really excited to see this ticket in play. I also want to double-check that we plan to tread cautiously here. Google easily represents the majority of our visits and anything that could change how they rank us needs to be thoroughly tested.
As @Deskana mentioned, we're not exactly sure how they index us now. It could be that a sitemap would override a crawling service they use that is superior in important ways to whatever sitemap we provide: that by including some pages that they have chosen to ignore we lower our overall site score. I don't know.
I think my point is that I think we should test it on a few wiki's first and preferably via a/b test. If you created a sitemap for half a wiki's pages, for instance, we could conceivably see how those pages fare against non-sitemapped pages over the course of a month. I think evaluating the impact on our traffic is within the scope of the product analytics team, so it shouldn't take too much extra work from your side.
Comment Actions
Ummm, this task is about fixing the Italian Wikipedia's search engine problem. I don't think waiting a few months for an a/b test on whether sitemaps affect Google or not (especially right after we just talked to someone at Google about their indexing process at Wikimania!) is an appropriate solution.
Can we keep this focused about fixing the current, seemingly high priority issues, and move the longer-term sitemap plan to some other task?
Comment Actions
@Legoktm I don't mean to get in the way of fixing the specific issue with Italian Wikipedia. I was responding to indications, including the wording below, that the sitemaps would be generated for all wikis:
Generating a sitemap only for Italian Wikipedia is not something we need to test (particularly given the situation we're attempting to correct) and I am actually very curious to see how it impacts our search ranking and traffic. Apologies if I misinterpreted the proposal.
Comment Actions
When i chatted with @Imarlier via Hangout, we talked about running these as one-offs as needed to fix specific issues. I don't know if that is still the plan, perhaps he can weigh in.
Comment Actions
@JKatzWMF Definitely makes sense to test this before pushing it everywhere. Solving the individual case of itwiki should make it possible to also solve the general case without needing to do much more work was all that I meant. There are about 4-5 other open Phab tickets either requesting sitemaps for specific wikis or suggesting sitemaps for all wikis, so something worth looking at.
I am starting with just itwiki, though.
Comment Actions
Great! Thank you for confirming, @Imarlier and, again, I am really excited to see this happen (and will be looking to track impact after rollout).
Comment Actions
If you are going to store things on the dump web servers:
You want files to go under /srv/dumps/xmldatadumps/public/other/nicedirnamehere and I don't remember how that gets synced between the two labstores, maybe you need to do that manually. Most data that's not dumps gets grabbed via rsync which is handled in puppet, and so both labstores pick it up.
It would be nice to have a README in there too. I don't know if you want the dir and README to be puppetized.
Obviously being there, these files may get mirrored by public mirror sites, and random crawlers may pick them up too, you probably don't care about that either way.
Comment Actions
I guess /srv/dumps/xmldatadumps/public/other/sitemaps or similar should suffice. It's not a problem if the subdirectories use the domain name, right? The other/ tree is more flexible in terms of naming, I think.
Obviously being there, these files may get mirrored by public mirror sites, and random crawlers may pick them up too, you probably don't care about that either way.
Yes, it's not going to be a problem: we have had Yahoo abstracts public for a long time. If you first proceed with the Italian Wikipedia (or few wikis), I guess the sitemap (or sitemap index) can be submitted manually on Google Webmaster by someone with access. Later, if confirmed to be useful, we can decide whether to link the sitemaps more generally in robots.txt.
Sure. In theory, if I read https://support.google.com/webmasters/answer/183668 correctly, sending a sitemap means "please index these URLs" but also "variants of these URLs are probably not canonical" and "pages outside this list are less important". We'll see the results in practice.
Comment Actions
@BBlack Could use a hand from you/someone on your team.
I've generated the sitemaps for it.wikipedia.org and placed them on the dumps server at https://dumps.wikimedia.org/other/sitemaps/it.wikipedia.org/sitemap.xml and related. (For the moment, I've done this manually.)
The next trick is to get requests to actually pull down that file. Unfortunately, my understanding is that this cannot be done with a redirect, or by adding a sitemap hint in robots.txt for itwiki -- according to the FAQ on sitemaps.org:
All URLs listed in the Sitemap must reside on the same host as the Sitemap. For instance, if the Sitemap is located at http://www.example.com/sitemap.xml, it can't include URLs from http://subdomain.example.com. If the Sitemap is located at http://www.example.com/myfolder/sitemap.xml, it can't include URLs from http://www.example.com.
The rough routing that's needed ends up being
https://(hostname)/(sitemap[a-zA-Z0-9_-\.]*\.xml(\.gz)?) -> https://dumps.wikimedia.org/other/sitemaps/$1/$2
A couple of things that are probably worth knowing:
- Request volume should be quite low.
- 404's are totally fine for cases where the sitemap doesn't exist on the backend server.
- Though I've only generated the sitemap for it.wikipedia.org, there are ~5 or so other tickets requesting sitemaps for specific wikis. It's also something that we likely want to experiment with more broadly. So, a solution that works generally using regex/substitution is probably called for.
What's not clear to me is where something like this would be implemented. Varnish text frontend config? Or is there somewhere else that's more appropriate? It turns out that our VCL is fairly complex, so my digging around in puppet didn't help me out all that much. I'd appreciate any pointers.
Comment Actions
So a few things:
- We'll have to hack in the rewrite manually in VCL, but that's ok for now, there's a long list of other such hacks.
- Do we want to set this up for all wikis/langs (with an explicit whitelist for the pattern covering all language codes and the ~12 or so official wiki project domains). Or just a regex whitelist for the ones we've created so far (just itwiki, add as we go)? (either way seems fine, but we probably won't simply match every possible hostname, as some of the other non-wikis may in fact have their own valid sitemaps).
- Sorry, I should've been watching closer and caught this sooner, but "dumps.wikimedia.org" is one of the handful of domains on the audited shortlist which don't use our standard cache cluster termination. This means the cache clusters don't service its traffic, so they can't really rewrite into it easily. We can perhaps add a backend just for this purpose, though (not move dumps to standard termination, just also have the dumps backend available for rewriting these particular requests into). I'll have to double-check there's no snags with that idea...
Comment Actions
<snip>
- Sorry, I should've been watching closer and caught this sooner, but "dumps.wikimedia.org" is one of the handful of domains on the audited shortlist which don't use our standard cache cluster termination. This means the cache clusters don't service its traffic, so they can't really rewrite into it easily. We can perhaps add a backend just for this purpose, though (not move dumps to standard termination, just also have the dumps backend available for rewriting these particular requests into). I'll have to double-check there's no snags with that idea...
Does download.wikimedia.org work? I think that's served by text and it redirects to dumps.wikimedia.org. So now your rewrite would look like
https://(hostname)/(sitemap[a-zA-Z0-9_-\.]*\.xml(\.gz)?) -> https://download.wikimedia.org/other/sitemaps/$1/$2
Comment Actions
I guessed that would be the case :-)
- Do we want to set this up for all wikis/langs (with an explicit whitelist for the pattern covering all language codes and the ~12 or so official wiki project domains). Or just a regex whitelist for the ones we've created so far (just itwiki, add as we go)? (either way seems fine, but we probably won't simply match every possible hostname, as some of the other non-wikis may in fact have their own valid sitemaps).
I don't really have a preference, outside of the fact that we'd obviously not want to break anything that's working now. How I envision this working is something like this
- roll out it.wikipedia.org to fix this existing issue
- Add welsh, wikinews, maybe others, and evaluate how that impacts the effectiveness of search engine indexing
- if it turns out that it meaningfully improves indexing, then automate generation across all wikis/languages and roll out more broadly.
If it's easy to go from a domain whitelist to a pattern if/when we get to step 3, that seems fine to me.
- Sorry, I should've been watching closer and caught this sooner, but "dumps.wikimedia.org" is one of the handful of domains on the audited shortlist which don't use our standard cache cluster termination. This means the cache clusters don't service its traffic, so they can't really rewrite into it easily. We can perhaps add a backend just for this purpose, though (not move dumps to standard termination, just also have the dumps backend available for rewriting these particular requests into). I'll have to double-check there's no snags with that idea...
I'm honestly fine with these files ending up anywhere -- we went with dumps because it seemed like the easiest option, and sitemaps are functionally quite similar to the other content hosted there. If there's a better choice that works.
@ArielGlenn download won't work, because it actually just returns a 301 redirect to dumps. Good thought, though.
Comment Actions
Suggestion: maybe just have these generate long-term to the generic shared static path, and then the VCL can re-write to that instead of redirecting to a different backend.
Comment Actions
Status update:
- dumps.wikimedia.org really didn't work out well. The final nail in the coffin was it's an HTTPS-only site (which is a good thing, but ironically blocks our varnishes from rewriting requests into it).
- As a replacement, I've created a microsite for it at https://sitemaps.wikimedia.org/ , and copied the generated itwiki data there. This microsite is behind varnish, and we can rewrite requests into it for the wikis, so we're pretty close to the finish-line for making this initially work. We'll have to do some followup on exactly how we deploy daily updates to that site's servers in the short/medium/long term, but it's tractable.
- Before I get to turning on the rewriting part: what about the m-dot mobile domains? I assume for now we're either not making mobile-specific sitemaps (because rel=canonical goes to desktop anyways), or they'll be deployed separately, and either way we shouldn't treat the current itwiki map as a rewrite destination for it.m.wikipedia.org?
Comment Actions
Change 451863 had a related patch set uploaded (by BBlack; owner: BBlack):
[operations/puppet@production] Sitemap rewrite for itwiki, before VCL switching
Comment Actions
@BBlack to confirm on the third bullet, the current itwiki map should not be the rewrite destination for the dot-m domain. It wouldn't work, anyway, since the mapped URLs would not match the hostname.
Comment Actions
@Imarlier - Ok thanks! Before I push the rewrite buttons in https://gerrit.wikimedia.org/r/c/operations/puppet/+/451863 , do the basics at https://sitemaps.wikimedia.org/it.wikipedia.org/ look correct? (e.g. served Content-Types and whatnot)?
Comment Actions
Looks good to me:
imarlier@WMF2024 ~/dev/src/mediawiki-docker-dev (master●●)$ http HEAD https://sitemaps.wikimedia.org/it.wikipedia.org/sitemap-itwiki-NS_0-0.xml.gz HTTP/1.1 200 OK Accept-Ranges: bytes Age: 40 Backend-Timing: D=172 t=1533914322238173 Connection: keep-alive Content-Length: 1007683 Content-Type: application/x-gzip Date: Fri, 10 Aug 2018 15:19:22 GMT ETag: "f6043-5731463cd8922" Last-Modified: Fri, 10 Aug 2018 13:04:54 GMT Server: Apache Set-Cookie: WMF-Last-Access=10-Aug-2018;Path=/;HttpOnly;secure;Expires=Tue, 11 Sep 2018 12:00:00 GMT Strict-Transport-Security: max-age=106384710; includeSubDomains; preload Via: 1.1 varnish (Varnish/5.1), 1.1 varnish (Varnish/5.1) X-Analytics: https=1;nocookies=1 X-Cache: cp2001 miss, cp2023 hit/1 X-Cache-Status: hit-front X-Client-IP: 50.207.242.98 X-Varnish: 423332230, 758468384 774476260 imarlier@WMF2024 ~/dev/src/mediawiki-docker-dev (master●●)$ http HEAD https://sitemaps.wikimedia.org/it.wikipedia.org/sitemap-index-itwiki.xml HTTP/1.1 200 OK Accept-Ranges: bytes Age: 7691 Backend-Timing: D=207 t=1533906707723895 Connection: keep-alive Content-Encoding: gzip Content-Length: 564 Content-Type: application/xml Date: Fri, 10 Aug 2018 15:19:59 GMT ETag: W/"3872-5731463f6eadf" Last-Modified: Fri, 10 Aug 2018 13:04:57 GMT Server: Apache Set-Cookie: WMF-Last-Access=10-Aug-2018;Path=/;HttpOnly;secure;Expires=Tue, 11 Sep 2018 12:00:00 GMT Strict-Transport-Security: max-age=106384710; includeSubDomains; preload Vary: Accept-Encoding Via: 1.1 varnish (Varnish/5.1), 1.1 varnish (Varnish/5.1) X-Analytics: https=1;nocookies=1 X-Cache: cp2019 hit/1, cp2023 hit/1 X-Cache-Status: hit-front X-Client-IP: 50.207.242.98 X-Varnish: 400580306 342440106, 774316339 768790248 imarlier@WMF2024 ~/dev/src/mediawiki-docker-dev (master●●)$
Comment Actions
Change 451863 merged by BBlack:
[operations/puppet@production] Sitemap rewrite for itwiki, before VCL switching
Comment Actions
Change 451889 had a related patch set uploaded (by BBlack; owner: BBlack):
[operations/puppet@production] Sitemap rewrite for itwiki inside misc-frontend as well
Comment Actions
Change 451889 merged by BBlack:
[operations/puppet@production] Sitemap rewrite for itwiki inside misc-frontend as well
Comment Actions
Seems to be working now after the fixup above, will need to cleanup my VCL mess a little better early next week.
Comment Actions
Confirmed that https://it.wikipedia.org/sitemap.xml is returning. Submitting it to Google now, fingers crossed....
Comment Actions
@Nemo_bis Google has read in the sitemap for it.wikipedia.org, which should result in the index being refreshed. Can you please try to replicate this issue now that they have?
Comment Actions
https://tools.wmflabs.org/pageviews/?project=it.wikipedia.org&platform=all-access&agent=user&start=2018-07-01&end=2018-08-10&pages=Wikipedia:Comunicato_3_luglio_2018 also suggests that the frequency that the landing page is being hit has decreased significantly over the last couple of weeks. Will keep an eye on that over the next few days to see whether re-indexing helps with that.
Comment Actions
Yesterday we had just under 20,000 requests for the copyright protest page that were sourced from Google. All but 7 of them were requests that were made to the mobile site.
Unfortunately, there's no way to tell what the target pages were for these requests, as Google no longer provides keyword info.
I'll see what I can do about generating a sitemap for the mobile site, and we'll see if that addresses this.
Comment Actions
For reference, according to this thread, Polish Wikipedia was affected by a similar issue: https://pl.wikipedia.org/wiki/Wikipedia:Kawiarenka/Kwestie_techniczne#protest_w_sprawie_dyrektywy_UE_-_cache (last comment was on 20 July, I did not see the thread before)
The views for the protest page have been steadily dropping though: https://tools.wmflabs.org/pageviews/?project=pl.wikipedia.org&platform=all-access&agent=user&range=latest-90&pages=Wikipedia:Stanowisko_wikipedystów_w_kwestii_dyrektywy_o_prawach_autorskich_(lipiec_2018)
Comment Actions
Views are still dropping slowly but steadily. I believe generating a sitemap for the mobile site is worth a shot. Also, if a solution is not to be found, WMF should reconsider whether to keep encouraging such methods of protest or not. I fear they may become a double-edged sword, the effects of which could be tragic.
Comment Actions
It appears that a sitemap for the mobile site isn't going to be helpful. The mobile site includes a <link rel="canonical"....> tag in the page HTML, which references the desktop site. This means that Google's crawler is not going to directly index the mobile site in most cases.
In theory, the desktop site should have a similar tag that references the mobile site, as <link rel="alternate"...> and providing CSS selectors that Google can use to decide which URL to provide. That alternate URL can also be provided in the sitemap -- see https://developers.google.com/search/mobile-sites/mobile-seo/separate-urls for more information. However, we don't currently have either of these implemented. T99587 suggests doing this work, but has been idle for ~3 years at this point.
Comment Actions
Outside of the scope of this ticket, but I wanted to note it. This is what happened to the index for it.m.wikipedia.org after we submitted the sitemap for it.wikipedia.org:
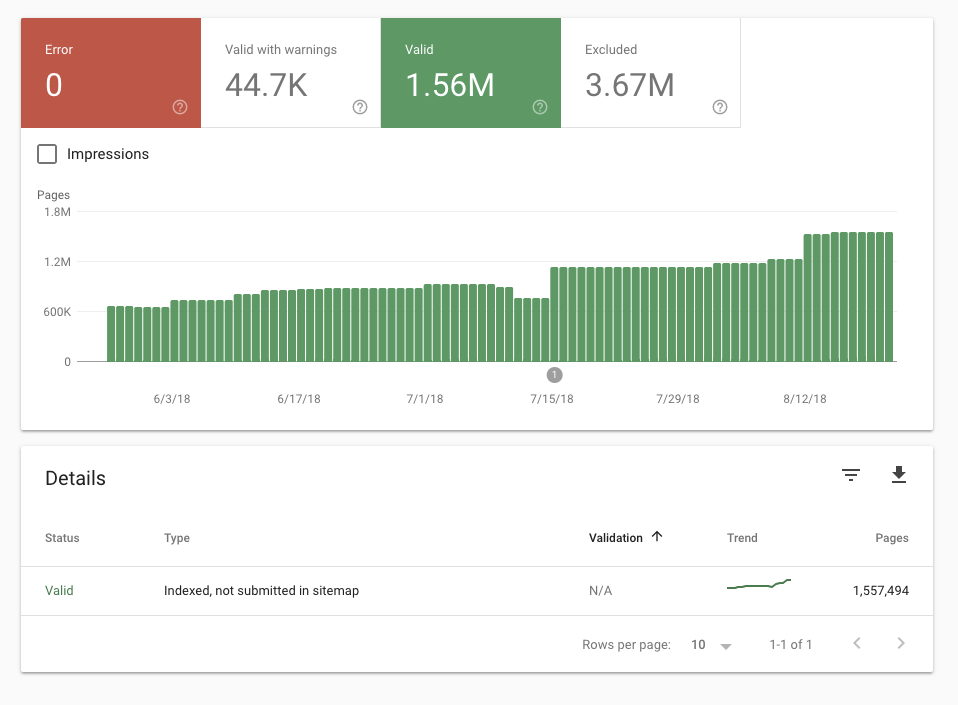
Given the above note about canonical links, this was surprising to me, so I pulled a sample of 1000 indexed URLs (the max that Google will provide), and it turns out that the vast majority of what's indexed is File/User/Talk URLs:
https://it.m.wikipedia.org/wiki/Discussioni_utente:Alextc222
https://it.m.wikipedia.org/wiki/Template:Basket_Uni_Girona
https://it.m.wikipedia.org/wiki/File:Amiens_ponts_des_Hortillonnages_1.jpg
https://it.m.wikipedia.org/wiki/File:Jeff_Mills_2.jpg
https://it.m.wikipedia.org/wiki/File:Karte_Gemeinde_Trasadingen.png
https://it.m.wikipedia.org/wiki/File:Beitar_Jerusalem_FC_vs._MTK_Budapest_FC_2016-06-18_(018).jpg
https://it.m.wikipedia.org/wiki/File:PS_Waverley_24806_934.jpg
https://it.m.wikipedia.org/wiki/File:Christian_Cantwell.jpg
https://it.m.wikipedia.org/wiki/File:Lokomotive_HŽ_1141.jpg
https://it.m.wikipedia.org/wiki/File:Epiphone_Les_Paul_100.jpg
https://it.m.wikipedia.org/wiki/File:Ethan_Ruan_Jing_Tian_4.JPG
https://it.m.wikipedia.org/wiki/Discussioni_utente:CHIARA_FAELLA
https://it.m.wikipedia.org/wiki/Discussioni_utente:Antodedonno
https://it.m.wikipedia.org/wiki/File:2010_EC_Ladies_Podium.jpg
https://it.m.wikipedia.org/wiki/File:Alopecosa_fabrilis_female_1.jpg
https://it.m.wikipedia.org/wiki/File:Me262_02.jpg
https://it.m.wikipedia.org/wiki/File:Making-Wikipedia-Better-Photos-Florin-Wikimania-2012-14.jpg
https://it.m.wikipedia.org/wiki/File:Kia_cee'd_Baltikblau_Heck.JPG
https://it.m.wikipedia.org/wiki/Discussioni_utente:Cheikh_diagne
These pages do all have canonical URLs, so no idea why they'd be showing up in this index.
Comment Actions
@Imarlier Hm.. might be unrelated, but I see that those are all m-dot urls, which are not themselves canonical. However, as you said, they do have the canonical url specified in their source.
Comment Actions
Right, that's what I was pointing out. Taking a random example from this list, https://it.m.wikipedia.org/wiki/Discussioni_utente:CHIARA_FAELLA, this is present in the source:
<link rel="canonical" href="https://it.wikipedia.org/wiki/Discussioni_utente:CHIARA_FAELLA"/>
According to Google's docs, that canonical tag should mean that the URL itself will not be indexed by Google....but it is. No idea what's different.
Comment Actions
@Imarlier - Have y'all tried the "Request Indexing" feature in Google Search Console for the specific URLs that are affected? i.e. in Google Search Console, go to "URL inspection", enter the URL of the page that has the bogus search results, hit return, and click on "Request Indexing" next to where it says "Page changed?". That should force Google to recrawl the page and reindex it with the current content. My apologies if y'all have already tried this. (I didn't read though the incredibly long discussion above.)
Comment Actions
@kaldari Indeed. Problem is that the number of affected pages was somewhere > 500,000, and as far as I can tell 1) there's no way to enumerate them; and 2) there's no way to request that reindexing other than one at a time. So, sadly, a no-go in this case.
Comment Actions
Google is known to not respect our canonical URLs, see T93550: Fix canonical URL issues (tracking). There might also be some special handling for the mobile site. It's not so much of a problem in itself to have extra URLs indexed as long as only the "right" ones actually show up in search results (e.g. mobile site to mobile user), but that's harder to track down.
Comment Actions
Problem is that the number of affected pages was somewhere > 500,000
Do we know how many pages are still affected? Where did the 500,000 figure come from?
Comment Actions
I don't know, but pageviews on that page are down to <10.000 per day now, therefore the number of affected pages is much lower than before but still significant (I would guess ~1.000).
Comment Actions
@Nemo_bis Regarding your comment above, about Google not respecting canonical URLs: it's not that they don't respect them, it's that we're not currently giving them the type of hints that they want specifically for mobile discovery[1].
What Google wants us to do is to provide a <link rel="alternate" /> tag, with a pointer to the mobile site, and a CSS selector that determines when that alternate URL should be used. We can provide the same alternate in the sitemap itself. Then, when a search is done that returns a result from https://it.wikipedia.org/, if the CSS selector of the client matches the CSS selector that is in the <link> tag, the actual URL that Google returns will be the alternate URL.
[1] - https://developers.google.com/search/mobile-sites/mobile-seo/separate-urls.
Comment Actions
@kaldari The >500,000 number is based on Google Search Console, which provides us with the number of valid pages that they know about within the domain. On July 5th, 2018, Google had indexed 2,603,000 valid pages on the domain it.wikipedia.org. On July 10th, 2018, they reported that they had indexed 1,813,000 valid pages.
Since we can't get a list of what's in their index (currently, or in the past) it's hard to be 100% sure about anything. But I think that it's a safe conclusion that the "missing" 800,000 pages were a result of Google's crawler hitting them and discovering that they redirected to the same location.
Comment Actions
What Google wants us to do is to provide a <link rel="alternate" /> tag, with a pointer to the mobile site,
See T99587, still open after three years. (You already pointed this out yourself above a month ago - repeating it here for folks reading along, just that so it doesn't get lost in this long discussion.)
and a CSS selector that determines when that alternate URL should be used. We can provide the same alternate in the sitemap itself. Then, when a search is done that returns a result from https://it.wikipedia.org/, if the CSS selector of the client matches the CSS selector that is in the <link> tag, the actual URL that Google returns will be the alternate URL.
[1] - https://developers.google.com/search/mobile-sites/mobile-seo/separate-urls.
Comment Actions
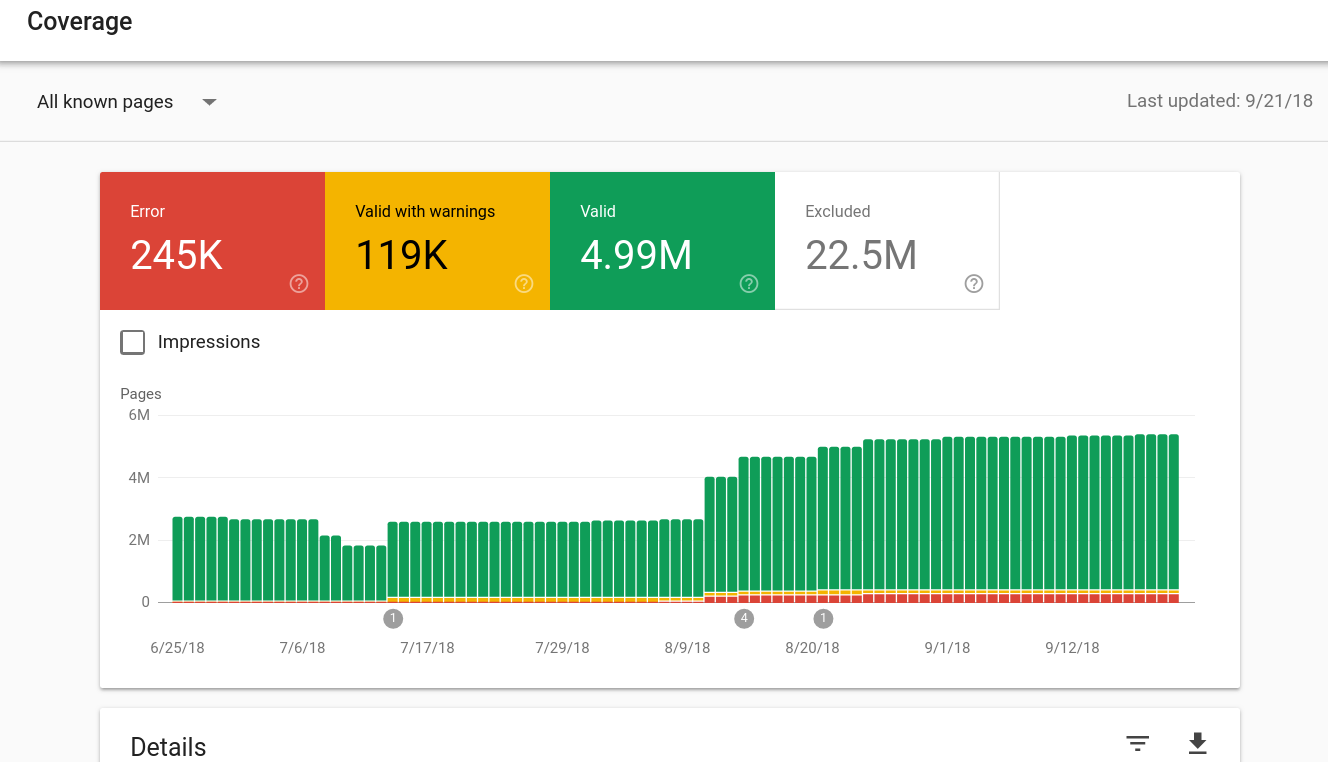
source
[...]
I was also curious how the impact of the sitemap rollout would look like for the desktop domain it.wikipedia.org itself:
source
Focusing just on the "Valid" pages for now (without "Valid with warnings"), this shows a 48% increase right on the day of the deployment, August 12. (Specifically, there were 2,527,562 "valid" on August 11, jumping to 3,732,095 on August 12, staying at that exact value for two more days, followed by a smaller increase to 4,321,830 on August 14, and an even smaller increase to 4,637,065 on August 21. BTW the July 14 bump marked with the "1" seems to be https://support.google.com/webmasters/answer/6211453#indexed due to a data change at Google, not related to the itwiki redirect issue.)
Comment Actions
There is a task to try to quantify if the addition of the sitemap actually increased traffic; see T202643 for more details.