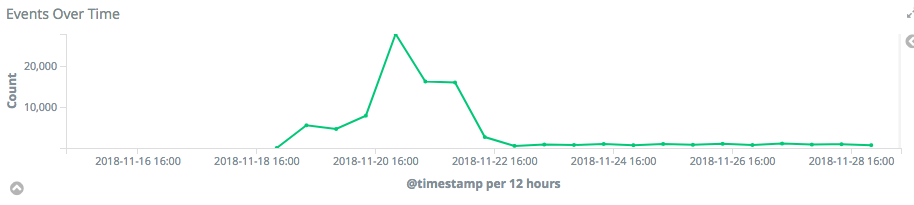
The problem: The beta cluster is continuously switching to read only mode after upgrade work has finished.
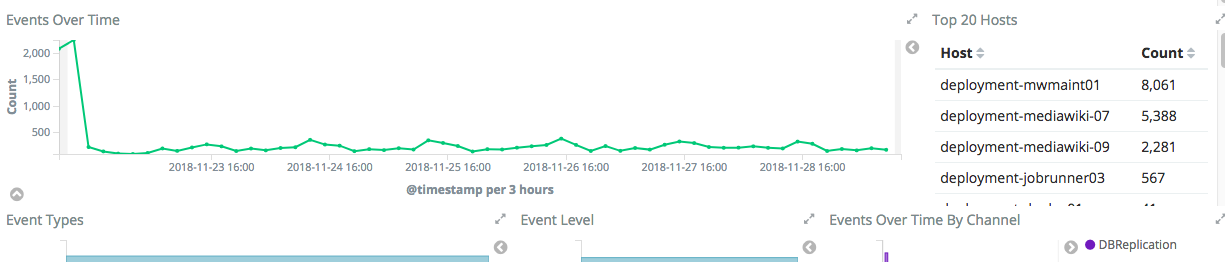
Note the downwards spike while the work was being carried on but how it continues long after at a rate of 300 events every 3 hours (all BC wikis): https://logstash-beta.wmflabs.org/goto/3939eafc6573af921c4231766d81982f
Implications: The entire mobile site (and various other extensions) are without reliable browser test coverage.
More background
Over the last few weeks the beta cluster was in read only mode. I am told this is no longer the case, but we are consistently seeing failures in our browser tests stating "The wiki is currently in read-only mode. (readonly) (MediawikiApi::ApiError)".
The wiki is currently in read-only mode. (readonly) (MediawikiApi::ApiError) /mnt/home/jenkins-deploy/.gem/2.1.0/gems/mediawiki_api-0.7.0/lib/mediawiki_api/client.rb:211:in `send_request' /mnt/home/jenkins-deploy/.gem/2.1.0/gems/mediawiki_api-0.7.0/lib/mediawiki_api/client.rb:232:in `raw_action' /mnt/home/jenkins-deploy/.gem/2.1.0/gems/mediawiki_api-0.7.0/lib/mediawiki_api/client.rb:36:in `action' /mnt/home/jenkins-deploy/.gem/2.1.0/gems/mediawiki_api-0.7.0/lib/mediawiki_api/client.rb:111:in `edit' /mnt/home/jenkins-deploy/.gem/2.1.0/gems/mediawiki_api-0.7.0/lib/mediawiki_api/client.rb:103:in `create_page'
This is high priority from web side as every day this remains broken we are without test coverage for a key part of the site and we are out of our depth here.