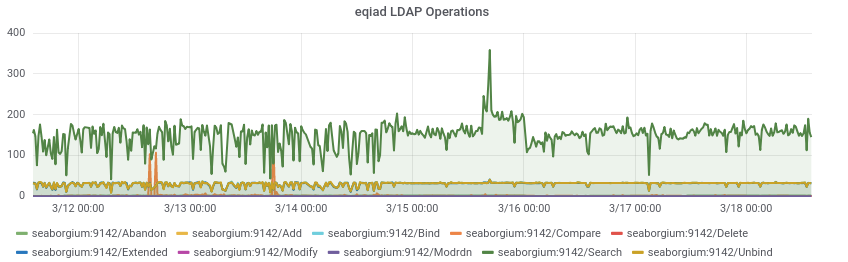
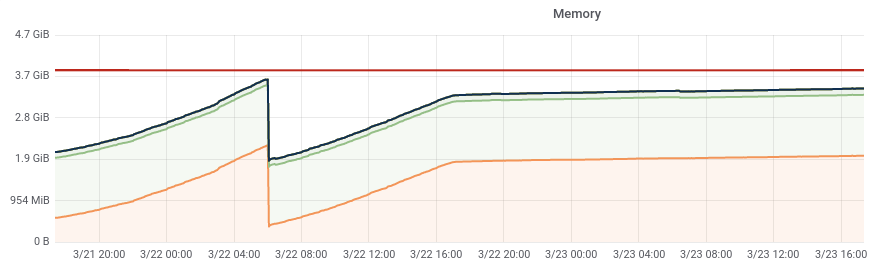
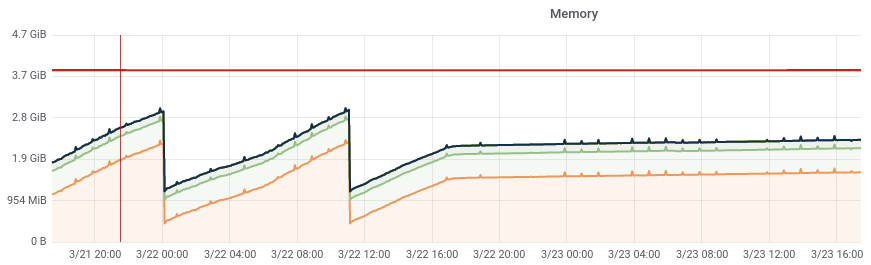
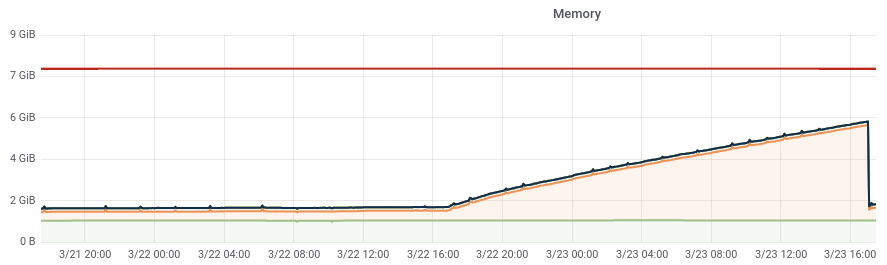
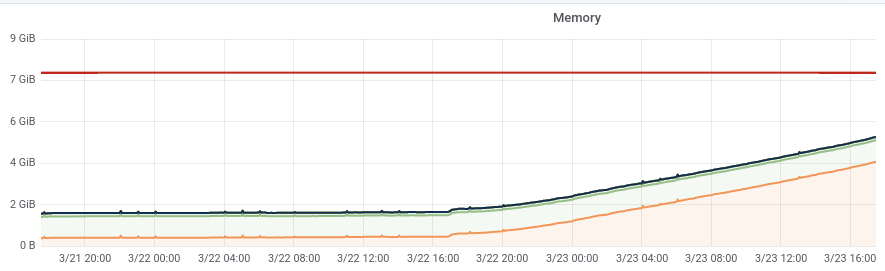
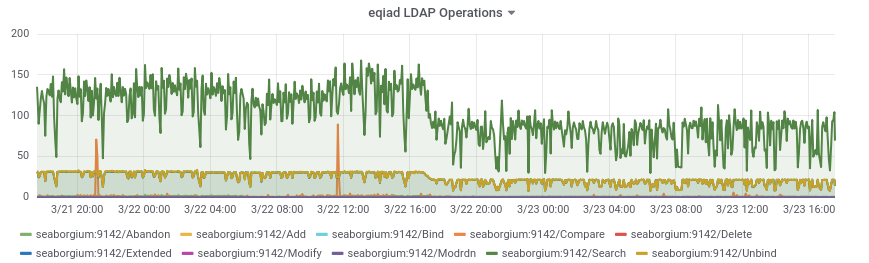
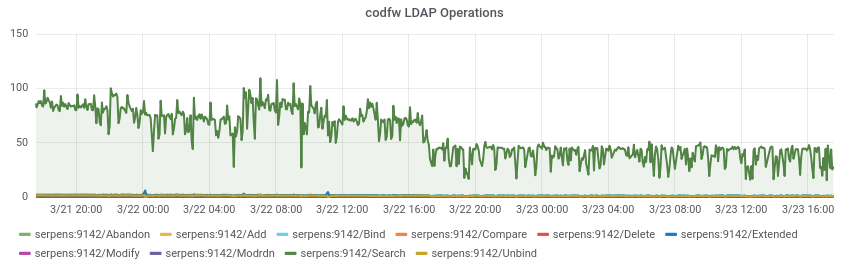
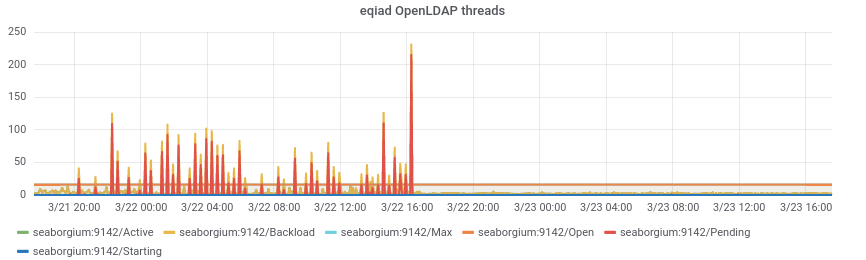
The rate of memory leaking from T130593: investigate slapd memory leak seems to have increased to a point where the band-aid solution of cron'd restarts that was implemented 2 years ago is now causing noticeable client disruption.
original bug report
I maintain dexbot tool in toolforge and it contains lots of tools the community depends on, I received reports that they stopped working and all of my services give 503. (like: https://tools.wmflabs.org/dexbot/d.php). when I try to become dexbot to do the classic "turning webservice off and on again", I get this:
ladsgroup@tools-sgebastion-07:~$ become dexbot groups: cannot find name for group ID 50062
I became the tool though.