Subtask of the TEC3:O3:O3.1:Q4 Goal to introduce kask to use the deployment pipeline
Description
Description
Details
Details
| Status | Subtype | Assigned | Task | ||
|---|---|---|---|---|---|
| Resolved | akosiaris | T198901 Migrate production services to kubernetes using the pipeline | |||
| Resolved | akosiaris | T220401 Introduce kask session storage service to kubernetes | |||
| Resolved | akosiaris | T220821 Add security sensitive nodes to our kubernetes cluster | |||
| Resolved | ayounsi | T220822 Site: 4 VM request for kubernetes | |||
| Open | None | T224041 Kask functional testing with Cassandra via the Deployment Pipeline | |||
| Declined | None | T255595 Support for deleting images in PipelineLib | |||
| Resolved | jeena | T255596 PipelineLib helm test log output | |||
| Resolved | jeena | T256281 Create WMF Cassandra image |
Event Timeline
There are a very large number of changes, so older changes are hidden. Show Older Changes
Comment Actions
I did some benchmarking and here's some first (rather impressive numbers) for kask
This is with 750 simultaneous simulated users via locust.io python framework. P8425 holds the code.
It's an artificial benchmark of using ascii strings of 32 chars for both key and value with a rate of 94% GET, 5% POST and 1% DELETE requests. The ratios are by my own RNG, I am guessing they are rather close to reality but we can of course alter them. There's a very small number of monitoring requests as well (ratio 1/50 for monitoring/normal).
The service is a single instance of kask and a single, untuned, straight out of the box, cassandra instance where the only actions taken were to create the schema (keyspace+table)
The service with those 750 simultaneous simulated users hasn't yet returned a failure for any kind of request. I 'll be pushing it to see when it does, but by the looks of it if won't be due to service but rather due to cassandra. Remains to be seen.
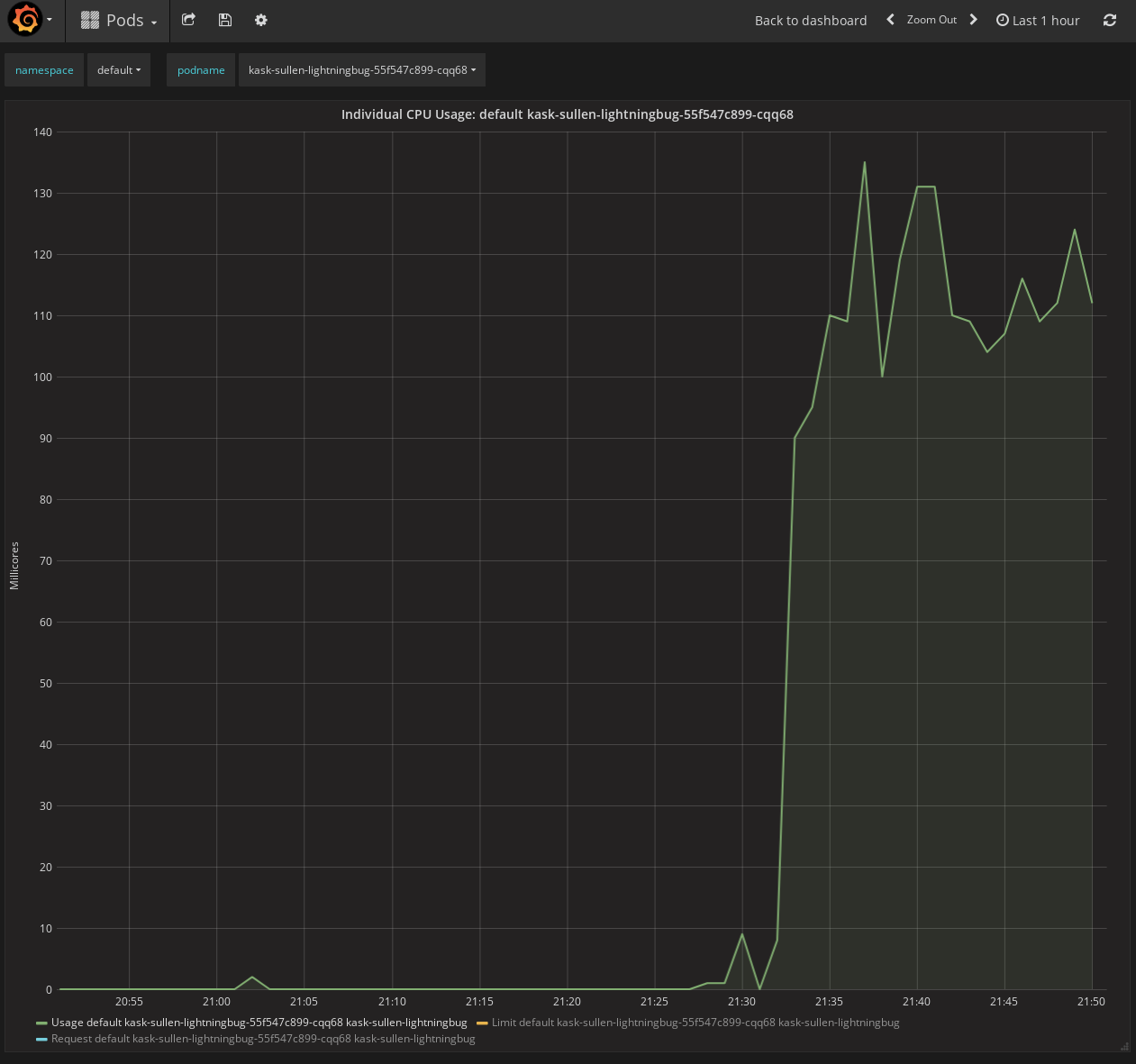
CPU wise we have the following graph
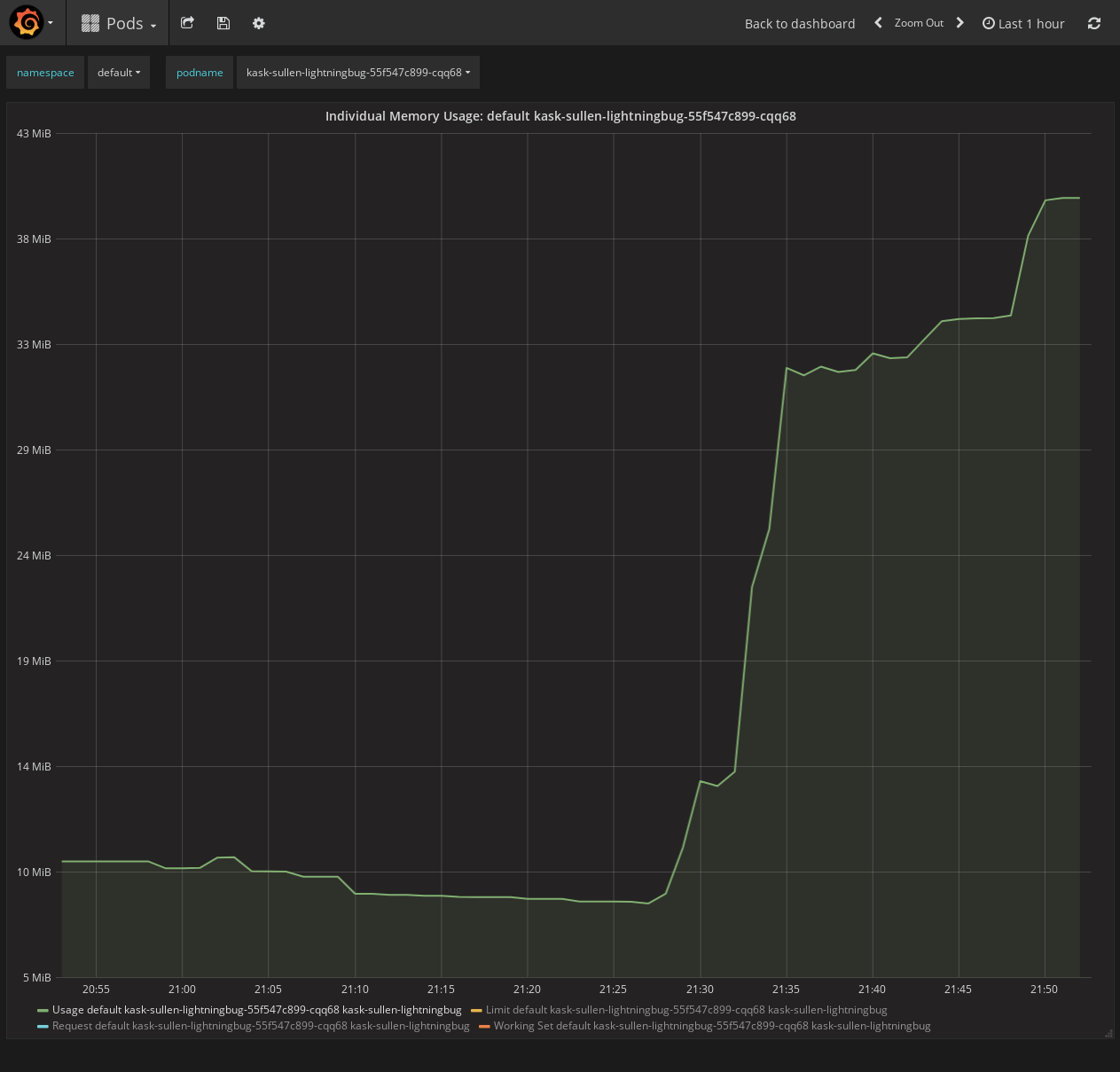
Mem wise the following
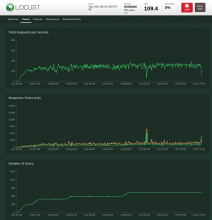
And locust provides us with the following
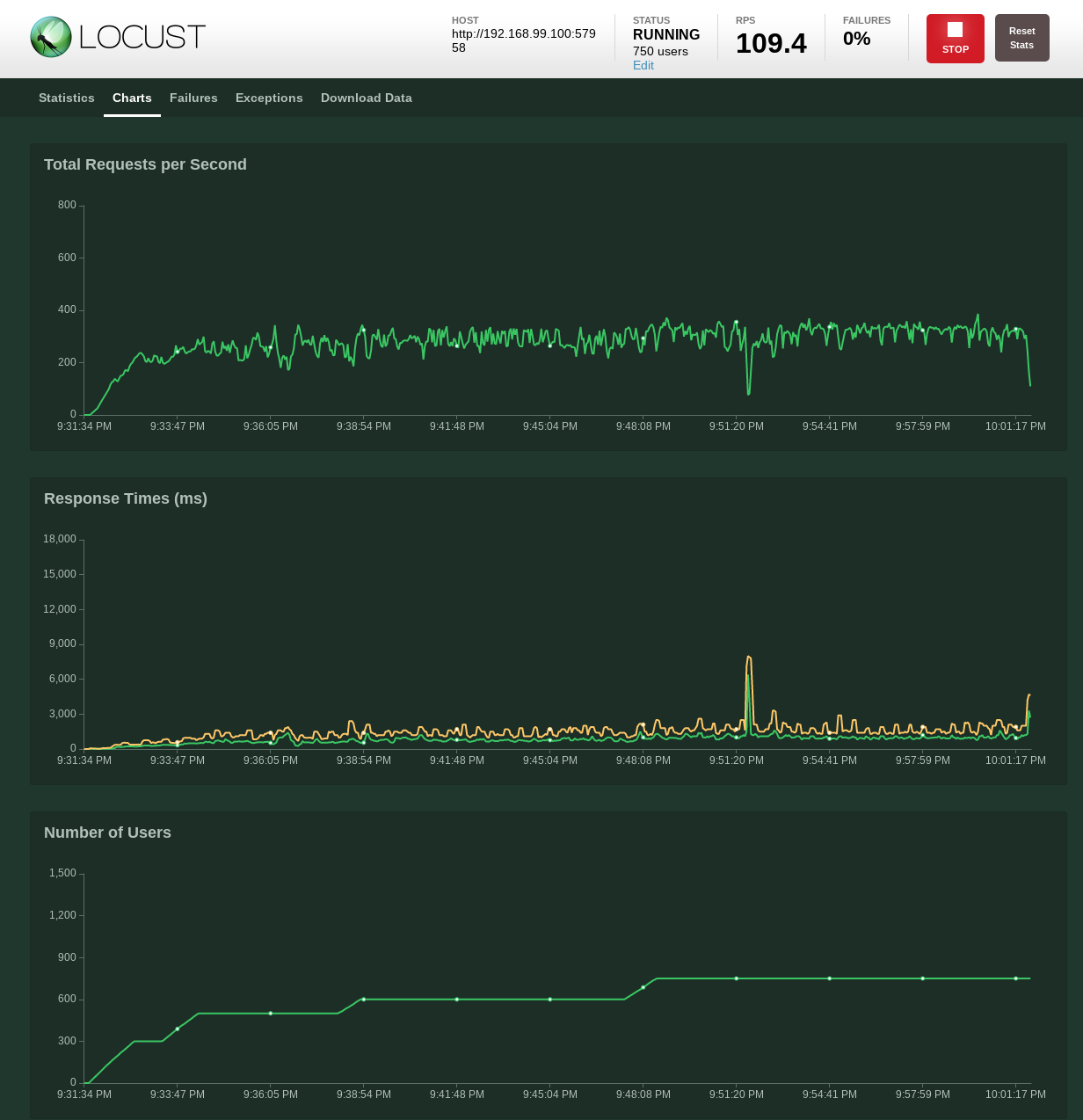
Overall, way before we reached the artificial 750 users number (actually at around 450), the service reached a stable mean of successfully ~300 req/s. There are spikes of up to 350req/s but these are followed by lows of 250req/s creating a saw like pattern. The latency follows a similar pattern which is consistent with the above behavior.
Memory usage barely reached 45MB, CPU usage barely reached 130m core.
I think we have the numbers we need for the helm chart.
After that, response latency starts increasing gradually with the amount of users added, without
Comment Actions
Just for posterity's sake, at ~1500 artificially simulated users the service started to crumble and started returning
HTTPError('500 Server Error: Internal Server Error for url: http://192.168.99.100:57958/sessions/v1/xwdmubncprzxtndfcyffnttsqzpsiulb',)with the service logging
{"msg":"Error reading from storage (gocql: no response received from cassandra within timeout period)","appname":"sessions","time":"2019-04-22T19:19:29Z","level":"ERROR","request_id":"00000000-0000-0000-0000-000000000000"}This is fine, that's why we ran this benchmark. The numbers are pretty impressive already. Memory and CPU usage (which is why this entire benchmark was done) did not really change (barely 60MB of memory usage, CPU remained largely the same). The number of req/s successfully served peaked at ~400.
For production, we should be keeping in mind that each pod should not be serving > 250 req/s if we want to be in optimal state, with low latency and some room to spare.
Comment Actions
Change 505263 merged by Alexandros Kosiaris:
[operations/deployment-charts@master] First version of the kask chart
Comment Actions
Change 506104 had a related patch set uploaded (by Alexandros Kosiaris; owner: Alexandros Kosiaris):
[operations/deployment-charts@master] Publish the kask chart in the repo
Comment Actions
Change 506104 merged by Alexandros Kosiaris:
[operations/deployment-charts@master] Publish the kask chart in the repo
Comment Actions
Change 506110 had a related patch set uploaded (by Alexandros Kosiaris; owner: Alexandros Kosiaris):
[mediawiki/services/kask@master] Add helm.yaml file for use by the pipeline
Comment Actions
@Eevans @Clarakosi chart has been merged and is published. The only thing missing before we can move on to the deployment is the swagger/openapi spec so that service-checker[1] can run and monitor this service.
[1] https://github.com/wikimedia/operations-software-service-checker
Comment Actions
Change 507531 had a related patch set uploaded (by Mobrovac; owner: Mobrovac):
[operations/software/service-checker@master] Handle application/octet-stream requests properly; release v0.1.5
Comment Actions
Change 509102 had a related patch set uploaded (by Alexandros Kosiaris; owner: Alexandros Kosiaris):
[operations/deployment-charts@master] kask: Add incubator/cassandra subchart
Comment Actions
Change 509102 merged by Alexandros Kosiaris:
[operations/deployment-charts@master] kask: Add incubator/cassandra subchart
Comment Actions
@Clarakosi @Eevans. I 've updated the chart to also conditionally install a minimal cassandra for use in minikube. In my tests I was able to use and even run some benchmarks on it. On our side we are ready to proceed with deployment to staging and then production as soon as https://gerrit.wikimedia.org/r/#/c/mediawiki/services/kask/+/507397/ is merged.
I do have one question: We have a sessionstore cassandra ready for production, but what about staging? I don't as far as I know. So what do we do?
Couple of ideas:
- Reuse the current session store cassandra instances, albeit use a different keyspace.
- Setup new cassandra instances (in the -b, -c manner we have for other stuff) on the sessionstore hosts.
- Some variation of the above with some other cassandra hosts and not the sessionstore ones.
Staging currently is not exposed to the public (nor are there any immediate plans to do so) and sees 0 traffic. It exists just to perform an upgrade of the software on it right before performing it in production therefore hopefully increasing the confidence that an upgrade is not going to melt the world. So, load wise I am not particularly worried.
It also mimics production very closely (unlike say beta/deployment-prep) so it has the same security guarantees and assumptions, so neither of these factors should be a consideration either.
Opinions?
Comment Actions
Change 507531 merged by Giuseppe Lavagetto:
[operations/software/service-checker@master] Handle application/octet-stream requests properly; release v0.1.5
Comment Actions
... aaaand when service-checker v0.1.5 is packaged and in our APT :)
I do have one question: We have a sessionstore cassandra ready for production, but what about staging? I don't as far as I know. So what do we do?
@Joe suggested using the restbase-dev Cassandra cluster, which I'd +1.
Comment Actions
Change 510743 had a related patch set uploaded (by Alexandros Kosiaris; owner: Alexandros Kosiaris):
[operations/docker-images/production-images@master] Bump service-checker docker container image
Comment Actions
Mentioned in SAL (#wikimedia-operations) [2019-05-16T15:59:13Z] <akosiaris> build service-checker OCI container 0.0.2 with 0.1.5 service-checker version T220401
Comment Actions
Change 510743 merged by Alexandros Kosiaris:
[operations/docker-images/production-images@master] Bump service-checker docker container image
Comment Actions
Change 512673 had a related patch set uploaded (by Alexandros Kosiaris; owner: Alexandros Kosiaris):
[operations/deployment-charts@master] Add log_level, tls, openapi config options
Comment Actions
Change 512673 merged by Alexandros Kosiaris:
[operations/deployment-charts@master] Add log_level, tls, openapi config options
Comment Actions
Mentioned in SAL (#wikimedia-operations) [2019-05-27T15:36:45Z] <akosiaris> initialize sessionstore namespace on eqiad/codfw/staging kubernetes clusters T220401
Comment Actions
Change 512720 had a related patch set uploaded (by Alexandros Kosiaris; owner: Alexandros Kosiaris):
[operations/puppet@production] sessionstore: Populate kubernetes stanzas
Comment Actions
Change 512720 merged by Alexandros Kosiaris:
[operations/puppet@production] sessionstore: Populate kubernetes stanzas
Comment Actions
Change 513125 had a related patch set uploaded (by Alexandros Kosiaris; owner: Alexandros Kosiaris):
[operations/puppet@production] cassandra: Support client IPs in ferm
Comment Actions
Change 513125 merged by Alexandros Kosiaris:
[operations/puppet@production] cassandra: Support client IPs in ferm
Comment Actions
Change 513297 had a related patch set uploaded (by Alexandros Kosiaris; owner: Alexandros Kosiaris):
[operations/deployment-charts@master] Fix TLS support for kask and cassandra connections
Comment Actions
Change 513298 had a related patch set uploaded (by Alexandros Kosiaris; owner: Alexandros Kosiaris):
[operations/deployment-charts@master] Package and publish kask 0.0.4
Comment Actions
Change 513323 had a related patch set uploaded (by Alexandros Kosiaris; owner: Alexandros Kosiaris):
[operations/puppet@production] Add sessionstore.discovery.wmnet TLS cert
Comment Actions
Change 513297 merged by Alexandros Kosiaris:
[operations/deployment-charts@master] Fix TLS support for kask and cassandra connections
Comment Actions
Change 513298 merged by Alexandros Kosiaris:
[operations/deployment-charts@master] Package and publish kask 0.0.4
Comment Actions
Change 513328 had a related patch set uploaded (by Alexandros Kosiaris; owner: Alexandros Kosiaris):
[operations/dns@master] Add sessionstore LVS DNS RRs
Comment Actions
One thing that I just met is that kask stops accepting HTTP connections if kask cert/key pair is configured. That's fine normally, but there is a very interesting repercussion. Kubernetes readiness probes to the /healthz endpoint now fail. kask logs
2019/05/31 09:36:00 http: TLS handshake error from 10.64.0.247:55194: tls: first record does not look like a TLS handshake
Kubernetes can't do TLS enabled HTTP probes.
Options:
- We don't enable TLS for the session store. Unless I am mistaken that is what our current situation is, so we at least don't introduce a regression. That being said, it's clearly very suboptimal and against our goals. On the plus side, we could rely on envoy as a sidecar container for TLS demarcation/termination sometime in the future
- We migrate to a TCP probe. However we already use this for the liveness probe and experience has shown that using the same liveness/readiness probe is completely wrong. Pods get killed before they are depooled and have a chance to recover causing outages.
- We don't have a readiness probe. No, not a good idea. This protects us from domino effects and overloads of the service. The entire idea of the /healthz endpoint is exactly to avoid that.
- We use an Exec probe that executes something like curl https://<POD_IP>:8081/healthz. This is generally suboptimal as the execution of an external command is more expensive than an HTTP GET probe from the kubelet. I am also not clear on how the pod IP would be communicated to the command, need to research that more.
- We amend kask to not require TLS for the /healthz endpoint. This is ugly and would complicate the code considerably I think.
@Eevans Opinions?
Comment Actions
That is unfortunate. Out of curiosity, is that a design decision? Something that just hasn't been a priority to implement yet?
Options:
- We don't enable TLS for the session store. Unless I am mistaken that is what our current situation is, so we at least don't introduce a regression. That being said, it's clearly very suboptimal and against our goals. On the plus side, we could rely on envoy as a sidecar container for TLS demarcation/termination sometime in the future
- We migrate to a TCP probe. However we already use this for the liveness probe and experience has shown that using the same liveness/readiness probe is completely wrong. Pods get killed before they are depooled and have a chance to recover causing outages.
- We don't have a readiness probe. No, not a good idea. This protects us from domino effects and overloads of the service. The entire idea of the /healthz endpoint is exactly to avoid that.
- We use an Exec probe that executes something like curl https://<POD_IP>:8081/healthz. This is generally suboptimal as the execution of an external command is more expensive than an HTTP GET probe from the kubelet. I am also not clear on how the pod IP would be communicated to the command, need to research that more.
- We amend kask to not require TLS for the /healthz endpoint. This is ugly and would complicate the code considerably I think.
We can do this. It'd technically be a different server (different Server object, different port), even if bound to the same Go process, will it still satisfy its mandate? I wonder, does it make sense to do the same with the Prometheus agent? We could add the idea of a management interface or similar, make the listen address and port configurable, and hang /health and /metrics there.
@Eevans Opinions?
Comment Actions
+1 on having /metrics together with /healthz exposed on the same protocol, all the same as prometheus is concerned FWIW (though if /metrics is on https then the job configuration needs changing)
Comment Actions
Sigh, ignore this. I am wrong. It does support HTTPS after all, I just missed it when reading the docs (it's under a not so visible hidden scheme parameter that defaults to HTTP`. Just tried it and it works.
That being said...
We can do this. It'd technically be a different server (different Server object, different port), even if bound to the same Go process, will it still satisfy its mandate? I wonder, does it make sense to do the same with the Prometheus agent? We could add the idea of a management interface or similar, make the listen address and port configurable, and hang /health and /metrics there.
And this uncovered now that prometheus can't talk to it (cause it expects HTTP I guess?). /me looking into it (more deeply this time around).
Comment Actions
Change 513633 had a related patch set uploaded (by Alexandros Kosiaris; owner: Alexandros Kosiaris):
[operations/puppet@production] prometheus: Support TLS enabled pods
Comment Actions
Change 513636 had a related patch set uploaded (by Alexandros Kosiaris; owner: Alexandros Kosiaris):
[operations/deployment-charts@master] kask: prometheus scraping over HTTPS if TLS enabled
Comment Actions
Change 513633 merged by Alexandros Kosiaris:
[operations/puppet@production] prometheus: Support TLS enabled pods
Comment Actions
And this uncovered now that prometheus can't talk to it (cause it expects HTTP I guess?). /me looking into it (more deeply this time around).
And the patches above fix that as well. We are on track for having this fully functional early next week.
Comment Actions
Change 513636 merged by Alexandros Kosiaris:
[operations/deployment-charts@master] kask: prometheus scraping over HTTPS if TLS enabled
Comment Actions
One minor question. Given per T220401#5128786 1 kask instance is able to handle ~300req/s, how many instances will we require? I am unsure of the current rate of sessions requests to/from redis.
Comment Actions
What was the test environment used there? When I tested using the sessionstore Cassandra cluster nodes, I got at least two orders of magnitude higher throughput.
Comment Actions
An admittedly underpowered minikube environment with a probably untuned cassandra. Some values for cassandra itself are in https://gerrit.wikimedia.org/r/plugins/gitiles/operations/deployment-charts/+/refs/heads/master/charts/kask/values.yaml#114. It makes absolute sense that a well tuned and more powered cassandra cluster would be able to serve more req/s.
Now, to answer my question, and by looking at T221292, I 'll assume a single instance for production should be able to serve some 30k req/s (I am rounding down from the lowest score in that table just to be on the safe side). So 1 instance would probably not cover it, we would need at least 2 instances. Adding 2x rack row redundancy means 4 instances. Looks like that's our number for now. We can always increase it ofc.
Thanks.
Comment Actions
Change 513323 merged by Alexandros Kosiaris:
[operations/puppet@production] Add sessionstore.discovery.wmnet TLS cert
Comment Actions
Change 513988 had a related patch set uploaded (by Alexandros Kosiaris; owner: Alexandros Kosiaris):
[operations/deployment-charts@master] kask: Add affinity/tolerations headings
Comment Actions
FWIW, we've been bouncing around a target throughput of 30k/sec in production based on Redis metrics, but as was later noted in T212129, that number includes everything in Mainstash, only a fraction of which is sessions (we're moving sessions over separately of the rest). IOW, sessions should be something considerably less 30k/s, even if we don't know exactly what.
Comment Actions
Yup, that's true. In fact, some numbers I 've heard (I have no actual proof) place sessions at <10% of the total Mainstash (which says however nothing about the rate of requests for sessions). That being said, without an actual number it's hard to do math. Now, given that kask really isn't expensive to run, my take is: Play it safe, assume everything in Mainstash is sessions and work with that. When we get actual numbers we can always revisit the decisions here. It's not like we are going to etch them in stone.
Comment Actions
Change 513988 merged by Alexandros Kosiaris:
[operations/deployment-charts@master] kask: Add affinity/tolerations headings
Comment Actions
Mentioned in SAL (#wikimedia-operations) [2019-06-03T14:45:43Z] <akosiaris> deploy kask in sessionstore kubernetes namespace in eqiad, codfw T220401
Comment Actions
Change 513328 merged by Alexandros Kosiaris:
[operations/dns@master] Add sessionstore LVS DNS RRs
Comment Actions
Change 514025 had a related patch set uploaded (by Alexandros Kosiaris; owner: Alexandros Kosiaris):
[operations/puppet@production] Introduce sessionstore LVS configuration
Comment Actions
Change 514028 had a related patch set uploaded (by Alexandros Kosiaris; owner: Alexandros Kosiaris):
[operations/puppet@production] sessionstore: Enable LVS paging
Comment Actions
That number is correct, but it's misleading. Most of the Mainstash data is made up of Echo notification timestamps which don't have expiration times associated with them.
Comment Actions
Change 514025 merged by Alexandros Kosiaris:
[operations/puppet@production] Introduce sessionstore LVS configuration
Comment Actions
Mentioned in SAL (#wikimedia-operations) [2019-06-04T11:40:31Z] <akosiaris> restart pybal on lvs1015 for sessionstore LVS configuration. T220401
Comment Actions
Mentioned in SAL (#wikimedia-operations) [2019-06-04T12:04:40Z] <akosiaris> restart pybal on lvs2006 for sessionstore LVS configuration. T220401
Comment Actions
Mentioned in SAL (#wikimedia-operations) [2019-06-04T12:13:15Z] <akosiaris> restart pybal on lvs2003, lvs1015 for sessionstore LVS configuration. T220401
Comment Actions
And LVS done today.
akosiaris@deploy1001:~$ curl -i https://sessionstore.svc.eqiad.wmnet:8081/healthz HTTP/2 200 content-type: application/json content-length: 0 date: Tue, 04 Jun 2019 15:33:30 GMT akosiaris@deploy1001:~$ curl -i https://sessionstore.svc.codfw.wmnet:8081/healthz HTTP/2 200 content-type: application/json content-length: 0 date: Tue, 04 Jun 2019 15:33:36 GMT
Resolving this, the service is ready to be used.
Comment Actions
Change 515065 had a related patch set uploaded (by Alexandros Kosiaris; owner: Alexandros Kosiaris):
[operations/dns@master] sessionstore: Add discovery records
Comment Actions
Change 515065 merged by Alexandros Kosiaris:
[operations/dns@master] sessionstore: Add discovery records
Comment Actions
sessionstore.discovery.wmnet is now around and should be the canonical DNS used to address the service.
Comment Actions
Change 514028 merged by Alexandros Kosiaris:
[operations/puppet@production] sessionstore: Enable LVS paging
Comment Actions
Change 506110 abandoned by Thiemo Kreuz (WMDE):
[mediawiki/services/kask@master] Add helm.yaml file for use by the pipeline
Reason:
I assume this is outdated after 2 years.