We need to profile the new wikifeeds service's memory usage in order to get appropriate values to specify in the relevant fields of the Helm chart.
See the example here: T220401#5128786
| • Mholloway | |
| Jul 29 2019, 10:14 PM |
| F29967433: image.png | |
| Aug 5 2019, 8:25 PM |
| F29967449: image.png | |
| Aug 5 2019, 8:25 PM |
| F29967439: image.png | |
| Aug 5 2019, 8:25 PM |
| F29935448: image.png | |
| Aug 2 2019, 12:13 AM |
We need to profile the new wikifeeds service's memory usage in order to get appropriate values to specify in the relevant fields of the Helm chart.
See the example here: T220401#5128786
| Status | Subtype | Assigned | Task | ||
|---|---|---|---|---|---|
| Resolved | None | T169242 Develop Page Content Service for Reading Clients | |||
| Resolved | • Mholloway | T229286 Resolve service instability due to excessive event loop blockage since starting PCS response pregeneration | |||
| Resolved | • Mholloway | T170455 Extract the feed endpoints from PCS into a new wikifeeds service | |||
| Resolved | MSantos | T229287 Profile wikifeeds memory usage for Helm chart |
Change 526679 had a related patch set uploaded (by MSantos; owner: MSantos):
[operations/deployment-charts@master] WIP: First version of the wikifeeds chart
@akosiaris I'm pasting here some of the questions I sent to you by email regarding the similar work you did with Kask:
For posterity's and transparency's sake, pasting the answer I already gave to @MSantos via email
I 've written the following as a guide on how to do that
https://wikitech.wikimedia.org/wiki/User:Alexandros_Kosiaris/Benchmarking_kubernetes_apps
It should be pretty straightforward to follow it, unless you have a
ton of endpoints to benchmark against. In that case, I suggest having
a look at http://locust.io as it can make benchmarking way easier than ab,
assuming some reading and some basic python knowledge (in fact the
graphs in T229287 are based on
that).
But to answer questions specifically as well
Did you profile Kask locally or in the prod server? I see that you used Grafana and that made me wonder.
Locally in minikube, which has grafana built-in (it's the heapster
addon you see there mentioned)
If you did locally, did you use helm-charts development environment?
nope, just minikube with a local checkout of the deployments charts
repo in order to speed up debugging (i.e. cd charts/wikifeeds ; helm
install --set key1=value .)
If you did in the server, could you explain me (or point to proper documentation) how to do it?
I sure hope the link above helps. It's meant to be moved into a more
proper place this quarter
Thanks for handling this @MSantos
I am now facing an odd issue that seems related to the k8s instance I'm running. When hitting some endpoints I got the following error:
{
status: 504,
type: "internal_http_error",
detail: "Error: unable to get local issuer certificate",
method: "post",
uri: "https://en.wikipedia.org/w/api.php"
}It looks like a service-runner requirement that is missing, @akosiaris do you have any ideas why this could be happening? cc/ @Pchelolo
It can't verify the issuer for our certificate cause there aren't any CA certificates at all in the image.
Add ca-certificates to apt packages for the production variant (at the very least) on the blubber file, like in 1e61ca7d665.
Change 527160 had a related patch set uploaded (by MSantos; owner: MSantos):
[mediawiki/services/wikifeeds@master] Add ca-certificates package to build
Change 527160 abandoned by MSantos:
Add ca-certificates package to build
Reason:
the production image shouldn't install ca-certificates
So, I finish the setup and started some preliminary tests with the endpoint /v1/feed/onthisday, you can see it in the following image.
\o/
I'm using Apache Bench and it's still running, once is finished I will post the results here. Meanwhile, I'll write a locust.io script to perform a full test with all endpoints.
Nice. Let me know if you need any help
After testing a lot of scenarios here is my profiling report:
First I looked into prod statistics to set the proper load for each endpoint in the locust script P8863:
I performed tests with 750, 1500, 3000 and 6000 users, the latter had the closest req/sec rate matching production with 60 req/sec in average:
+--------+----------------------------------------------+------------+------------+------------+ | Method | Name | # requests | # failures | Requests/s | +--------+----------------------------------------------+------------+------------+------------+ | GET | /en.wikipedia.org/v1/feed/announcements | 3614 | 691 | 1.48 | | GET | /en.wikipedia.org/v1/feed/onthisday/selected | 27494 | 6417 | 11.22 | | GET | /en.wikipedia.org/v1/media/image/featured | 10217 | 3653 | 4.17 | | GET | /en.wikipedia.org/v1/page/featured | 10544 | 2120 | 4.3 | | GET | /en.wikipedia.org/v1/page/most-read | 10512 | 3967 | 4.29 | | GET | /en.wikipedia.org/v1/page/news | 3488 | 763 | 1.42 | | GET | /en.wikipedia.org/v1/page/random/title | 81186 | 16281 | 33.14 | | None | Total | 147055 | 33892 | 60.04 | +--------+----------------------------------------------+------------+------------+------------+
The result got 19% of failed requests, all of them with timeout errors, which is probably a problem with my internet

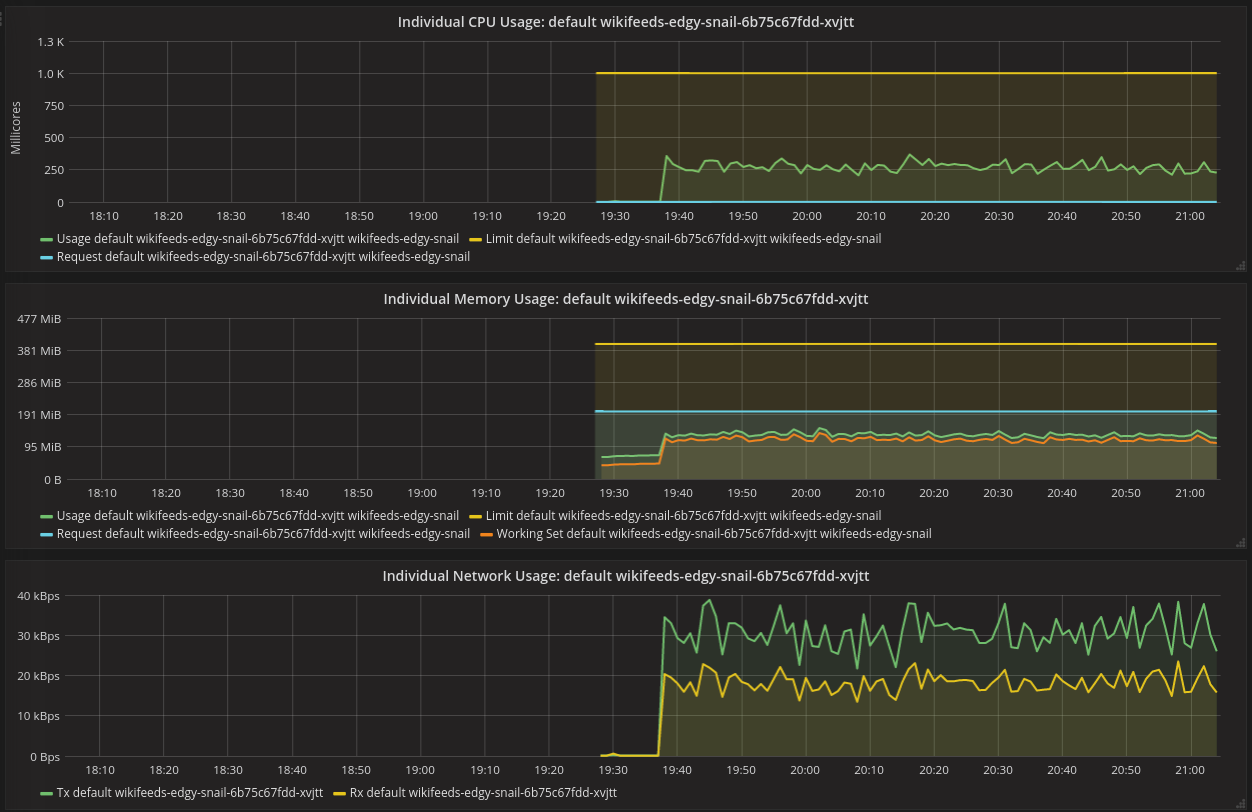
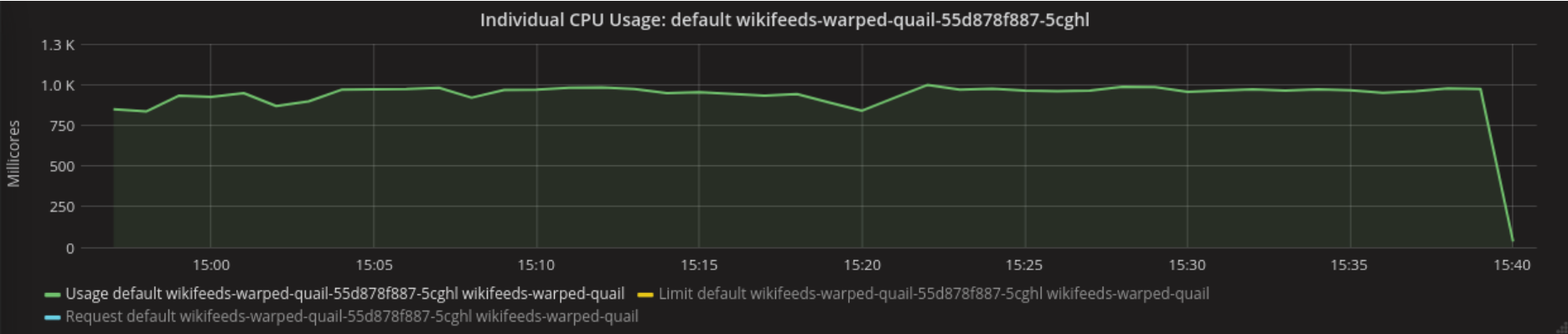
During the test, the maximum CPU used was 997m
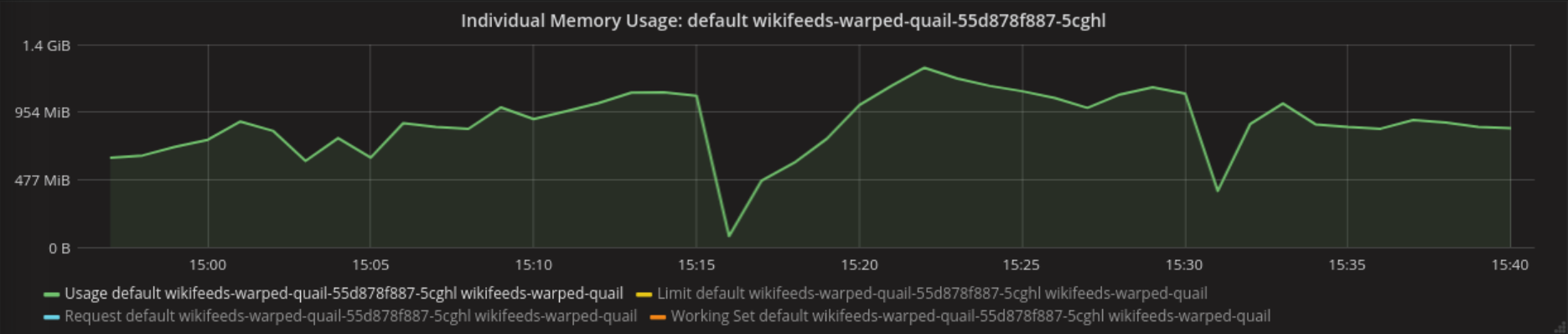
During the test, the maximum memory used was 1.237GiB
Thanks for running this.
My only point is that the max CPU looks suspiciously close to 1, which is the default value in https://gerrit.wikimedia.org/r/plugins/gitiles/operations/deployment-charts/+/refs/heads/master/_scaffold/values.yaml#25. This could be artificially limiting the app and could explain the errors. If you have already set it to higher values during your benchmarking disregard the next sentence. Otherwise, you might want want to bump it (considerably, say 10) and rerun the benchmark.
Great work, thanks a lot!
I ran into that problem in the beginning, than I set the CPU limit to 2 and memory to 6GB. Do you think CPU should be even higher?
If you already did, then it's fine. With ~1cpu usage while the limit is 2 we are good to go.
@Pchelolo and @mobrovac once https://gerrit.wikimedia.org/r/526679 is landed what are the next steps?
From Audiences platform sync:
@MSantos Had a look, found some issues. I 've also tested it with a helm install --set main_app.version=2019-08-01-194023-production . after applying my suggested changes. It seems to be working fine after that.
Change 526679 merged by Alexandros Kosiaris:
[operations/deployment-charts@master] First version of the wikifeeds chart
Moving to sign off since this task is about profiling. The deployment of wikifeeds should be tracked here T170455: Extract the feed endpoints from PCS into a new wikifeeds service
Change 527160 restored by Mholloway:
Add ca-certificates package to build
Reason:
per the comment from akosiaris
Change 527160 merged by jenkins-bot:
[mediawiki/services/wikifeeds@master] Add ca-certificates package to build