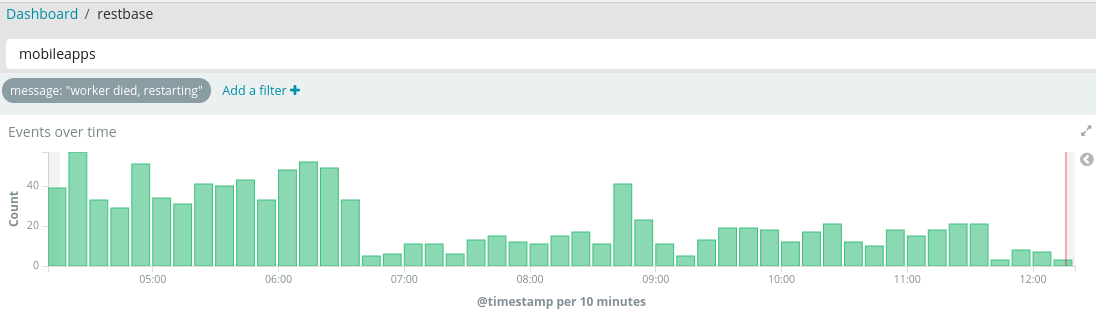
It appears that sometime after 2019-07-24 ~20:00 UTC, mobileapps started generating a lot of errors of worker died, restarting and worker stopped sending heartbeats, killing.
SAL around that time:
20:45 ppchelko@deploy1001: Started deploy [restbase/deploy@7911f65]: Store PCS endpoints T222384 20:39 bsitzmann@deploy1001: Finished deploy [mobileapps/deploy@2e2ce6c]: Update mobileapps to 1751a2e (duration: 04m 20s) 20:38 ppchelko@deploy1001: Finished deploy [changeprop/deploy@bf28187]: Rerender PCS endpoints T222384 (duration: 01m 34s) 20:36 ppchelko@deploy1001: Started deploy [changeprop/deploy@bf28187]: Rerender PCS endpoints T222384 20:35 bsitzmann@deploy1001: Started deploy [mobileapps/deploy@2e2ce6c]: Update mobileapps to 1751a2e
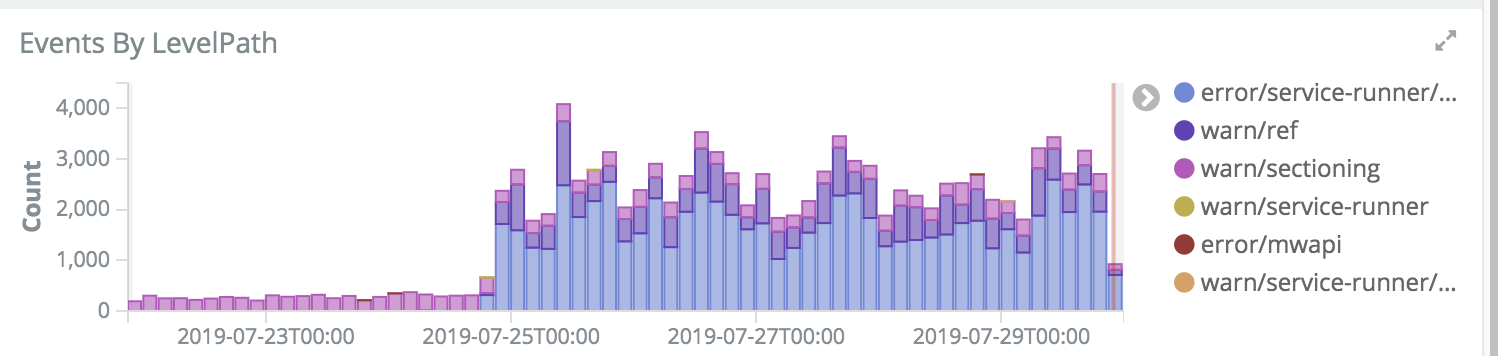
When this is resolved, we need to revert 541891