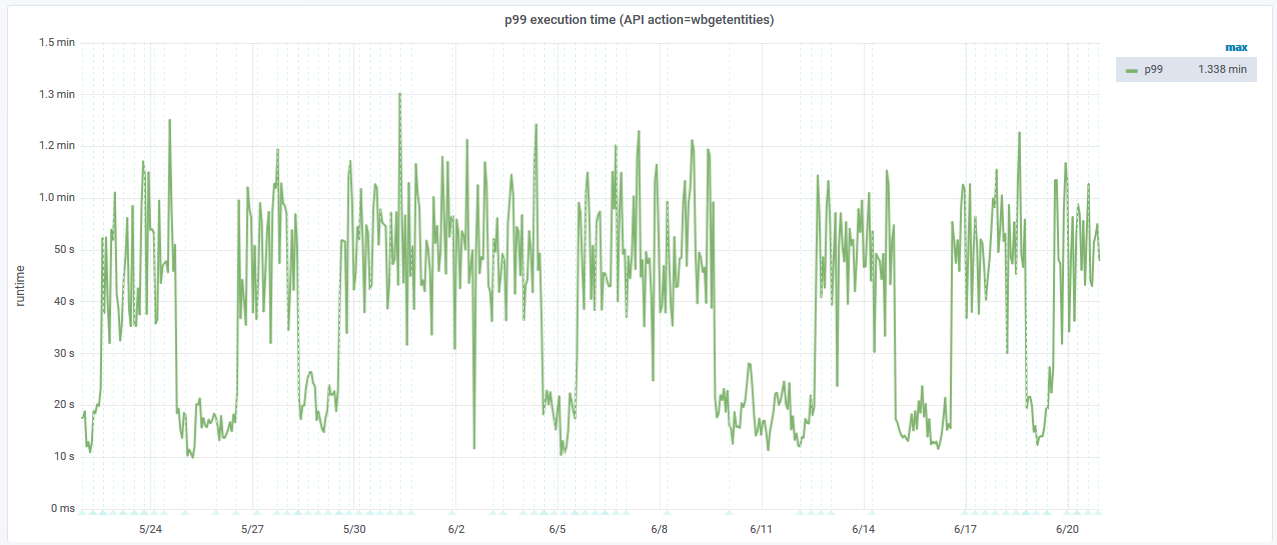
Many of my tools use the wbgetentities action to get data from Wikidata. This usually works well, but since yesterday I found that some of these queries take a lot of time, with some frameworks timing out. I am talking 1-2sec vs. 3.5min here. There is no fundamental difference between these queries, just different entity IDs. Results do not appear to be different either, same size, valid JSON etc.
I would imagine this is one single server begin slow. Can't see which server produced them though.
I will attach a screenshot, once I figure out how to do that in Phabricator.
Can currently be reproduced by visiting https://tools.wmflabs.org/reasonator/?q=Q350 but I don't know how reproducible this behaviour is.