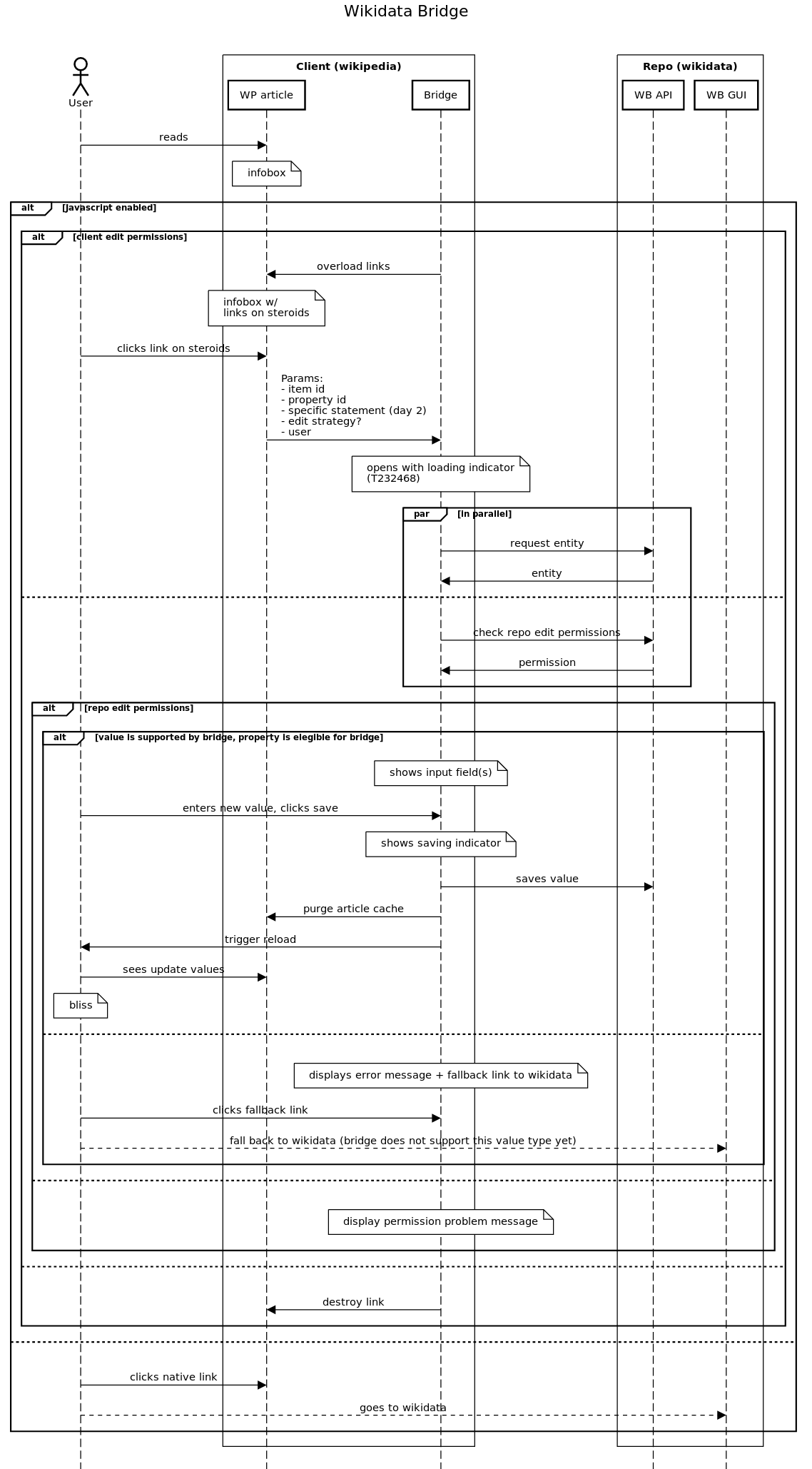
When an editor makes an edit through the Wikidata Bridge we want to reflect their change in the article as soon as possible and as seamlessly as possible. How can we do this?
Issues to consider:
- there is a time delay between the edit being made on the repository and that edit being dispatched to the client wiki
- try to get a sustainable solution
- how does this influence the possiblity of reloading vs in-place replacement (of the infobox)
Timebox this to max 4 hours.