Content translation provides users with suggestions of articles to translate. Based on user feedback, it would be useful to provide some general control about the knowledge area these suggestions are about (T113257).
Currently, the suggestion system provides either general suggestions or suggestions based on a given "seed article" used as an example to get similar suggestions.
As an initial step, this ticket tries to explore possible answers the following questions:
- How to represent the wide knowledge areas(e.g., science, philosophy...)? (e.g., vital article structure, categories, ORES topic model, Wikidata, etc.)
- How to use the current recommendation system or expand it to get suggestions on a selected area? (e.g., pick a random article from category and use as seed)
This ticket is focused on the technical exploration.
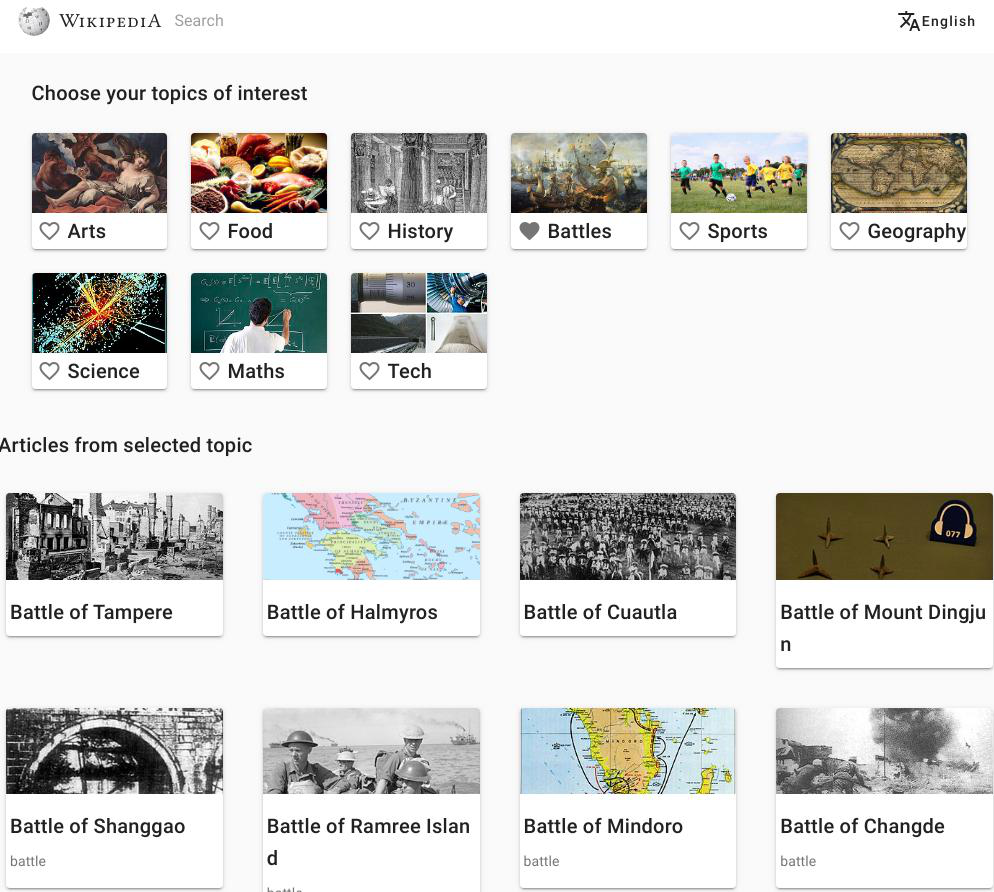
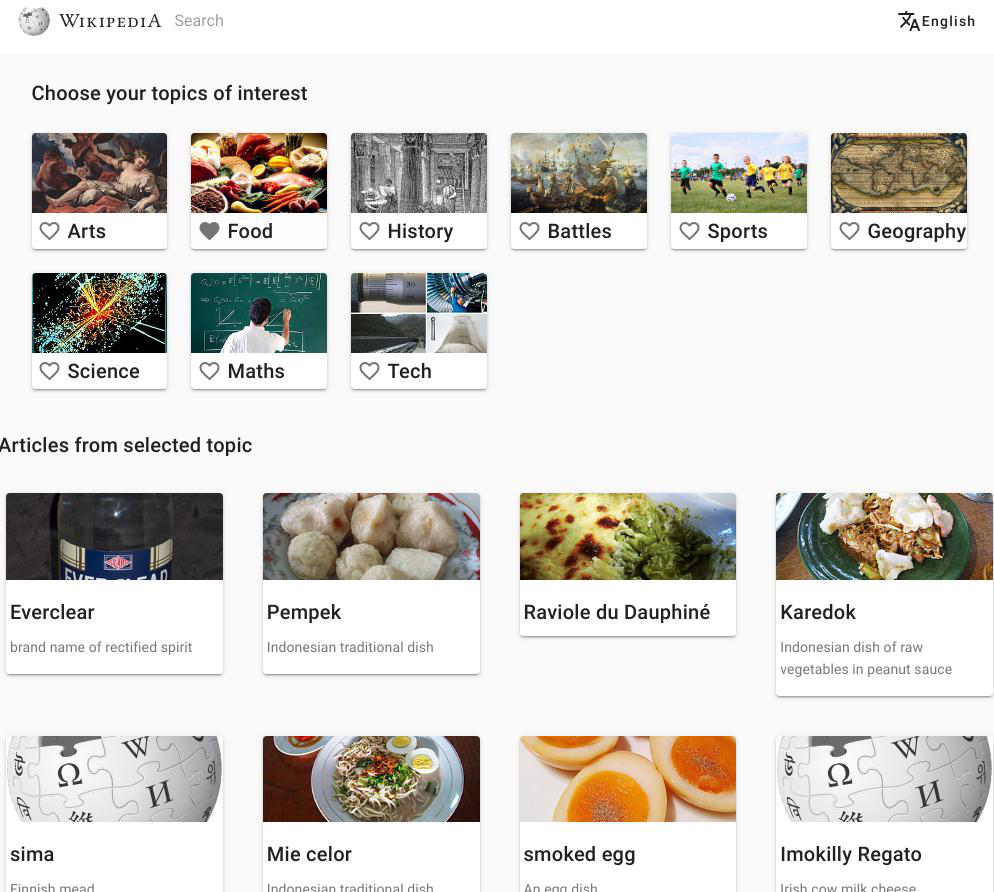
The mockups below are just illustrations of how this could be supported in Content translation:
| Structured set of categories for user to pick | Search for specific categories (with a predefined initial set) |
|---|---|
 |  |
Result
The recommended approach is to use a Wikidata query based on the instance of property (P31):
- Topic areas will be compiled manually. A set of Wikidata elements will be manually selected to represent the topic areas (example). The selection may be based on main topic classifications or the list of (vital articles level 2). From there, items representing the topic areas such as Arts or Food will be extracted.
- Query Wikidata for related articles. A Wikidata query (example) will find articles related to the selected topic area through the P31 property that can be translated (i.e., exist in source language but are missing in the target one).
- Wikidata parameters for detemining relevance. For each item in the results, additional Wikidata parameters such as the number of languages in which the topic is available, and the number of properties are used as indicators of the relevance of the topic, showing them higher in the list of results.
A proof-of-concept was developed to try the approach. By default it shows articles related to a topic area, but the URL can be adjusted to check articles missing in a given language (example for Spanish)
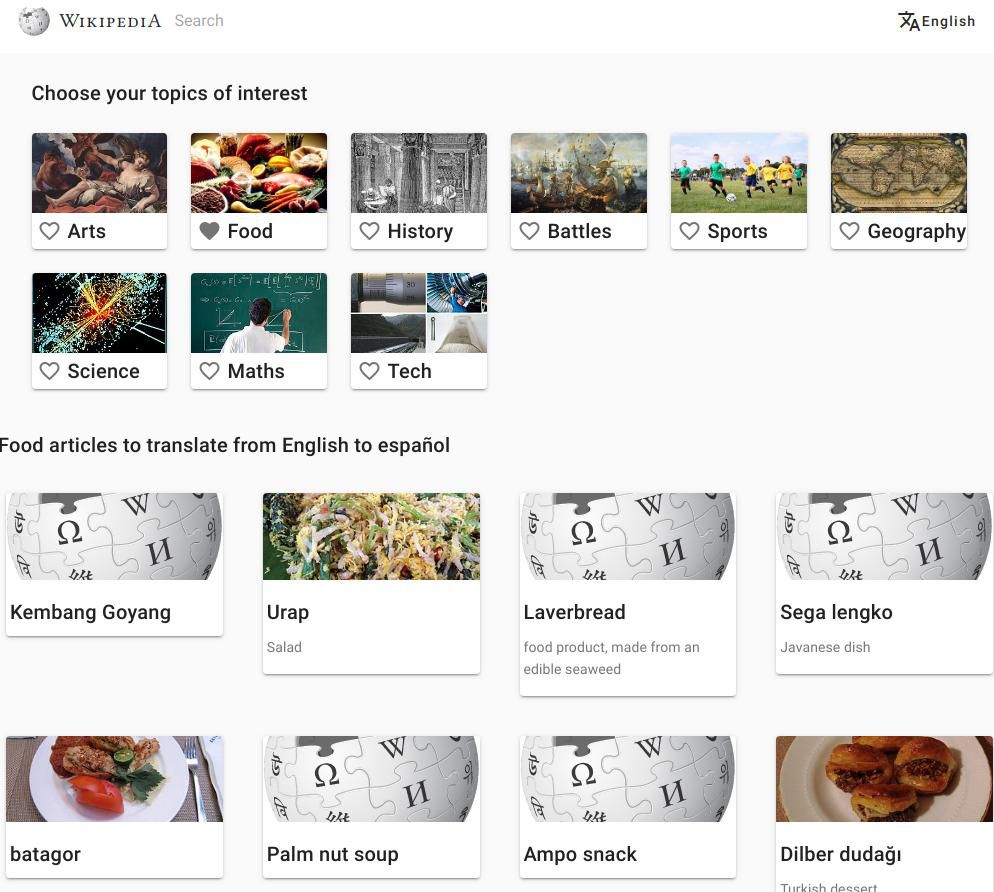
Design implications
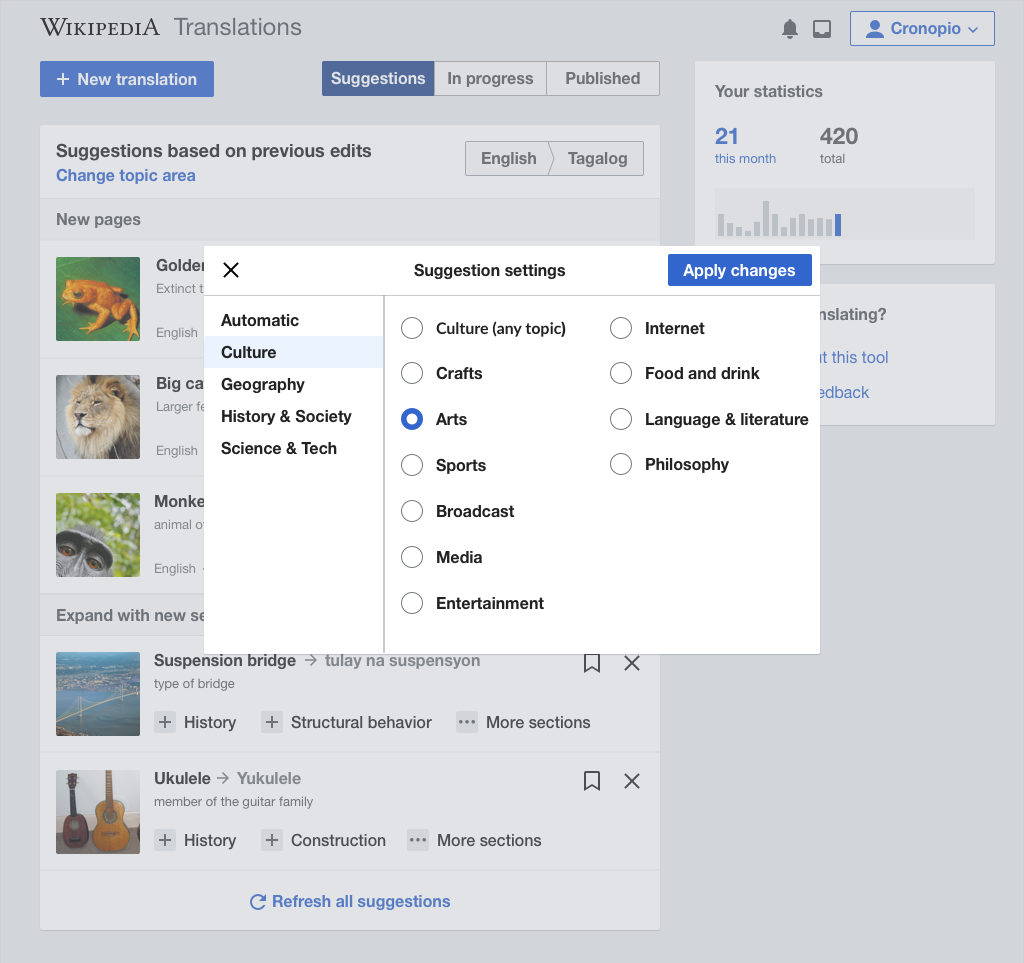
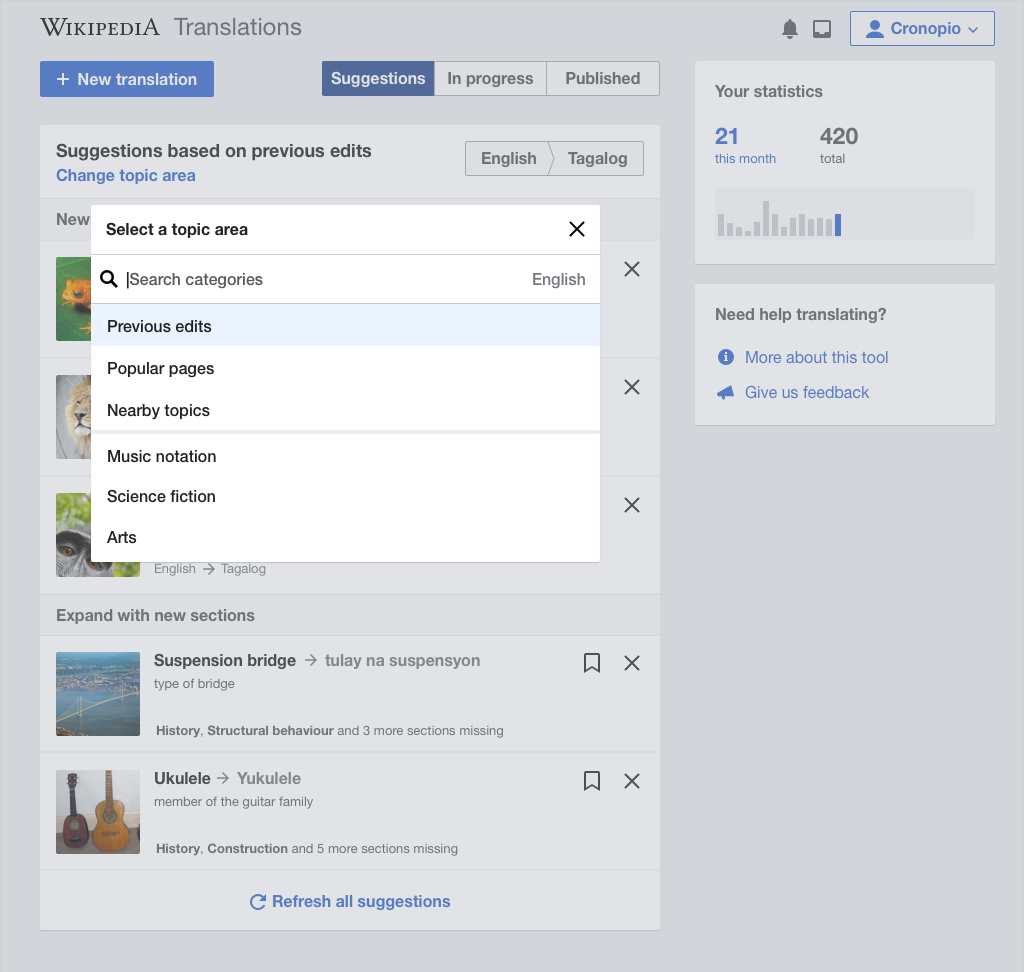
When exploring UI options for adjusting the suggestions (T113257), the following considerations need to be taken into account:
- Between 40 and 100 topic areas to support. Main topic classification provide 39 topic areas, while the vital articles provide 99 topic areas organized in 9 groups. The layout needs to account for this volume, making the groups more or less explicit (e.g., separate views for each group, groups in the same view, ordering in a flat list, etc.)
- Only one topic area at a time. Wikidata query performance is heavily affected when there is more than one topic area selected. Thus, the selection will be presented as exclusive: only one topic area at a time.
- Design for the wait. After selecting a topic area users may have to wait a few seconds. Thus, we may need to think on how to provide a waiting indicator, and potentially an option to cancel or avoid blocking the UI.
- Design for empty results. The query may lead to empty results for some languages. We need to explore how to better communicate that there were no results, try to prevent it or provide alternatives.
Related and very relevant exploration and experiments from the Growth team: T231506#5487829