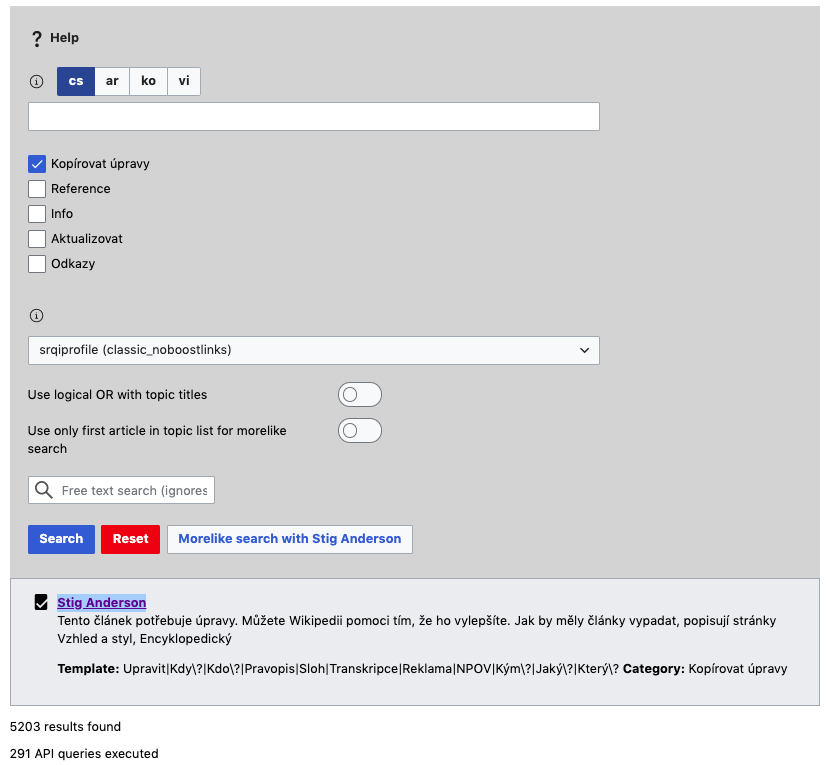
At the core of the newcomer tasks feature is the list of recommended tasks. We want the tasks to be relevant to the newcomer's skills and interests. Via investigations in T230246, we have decided that the first version of this feature will use maintenance templates to find articles that need to be improved in specific ways. Via investigations in T230248, we have discussed several different approaches to matching those articles to a newcomer's interests.
We recognize that we won't know what approach makes the most sense until we try some out. So in this task, the idea is to produce some lists of recommendations in our target language to evaluate whether they look like good recommendations for a newcomer with a given set of topic interests.
Task types
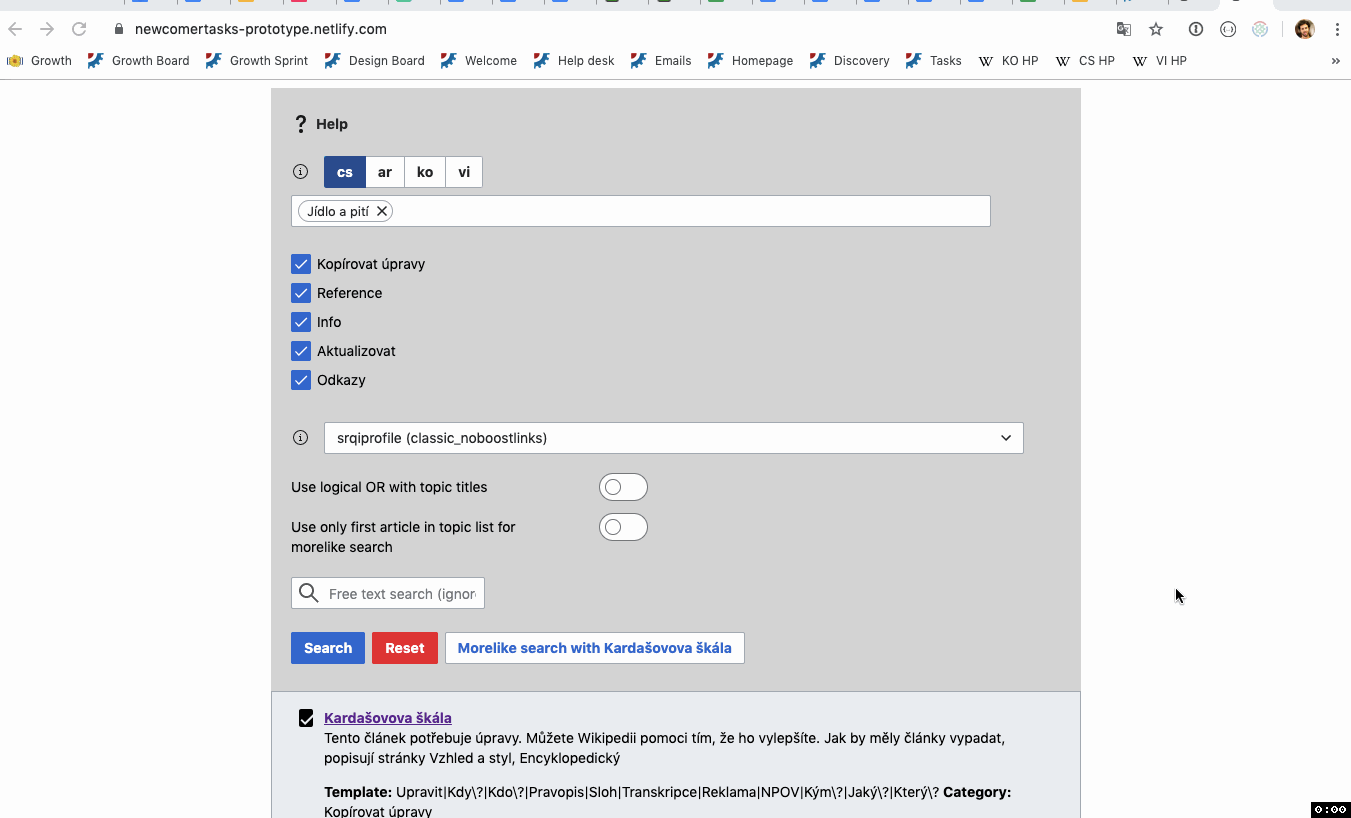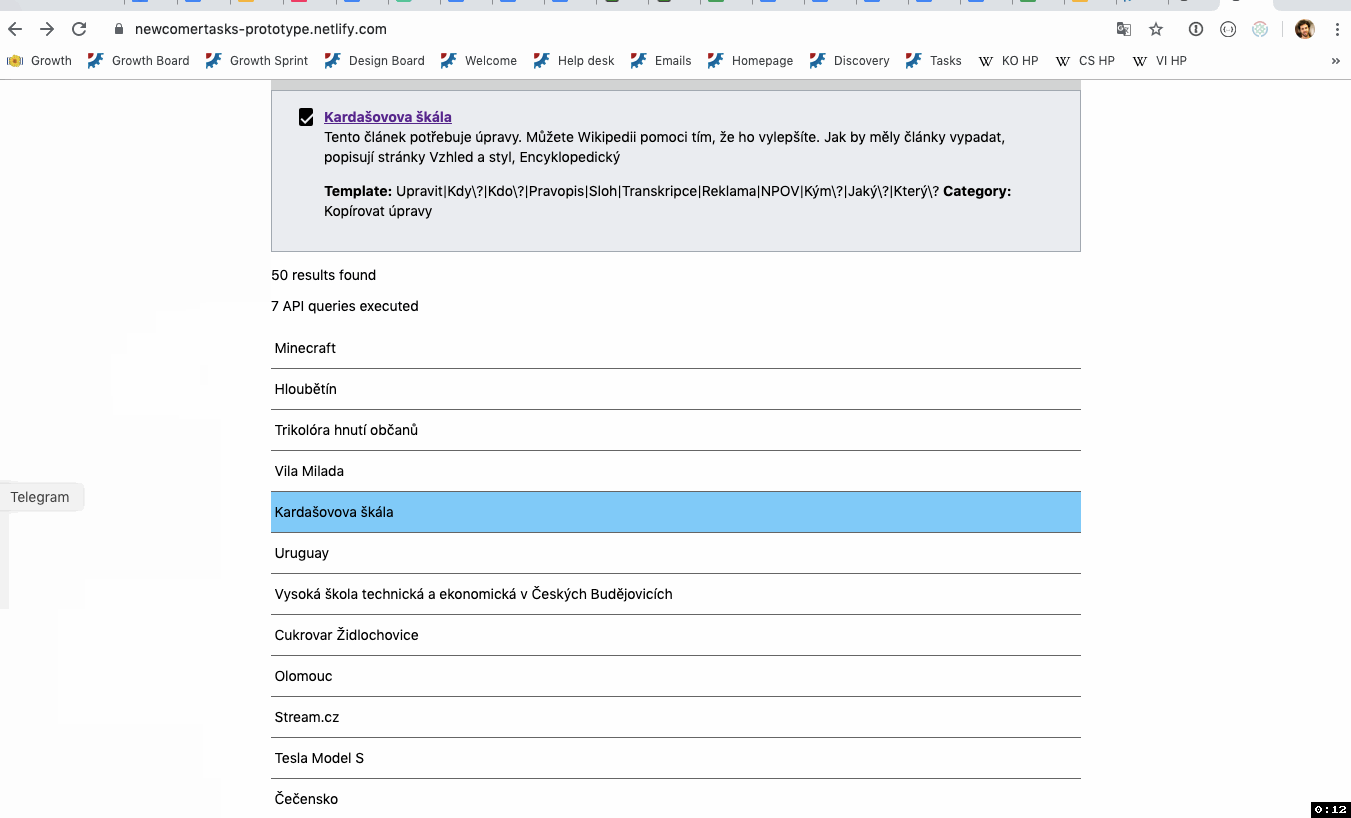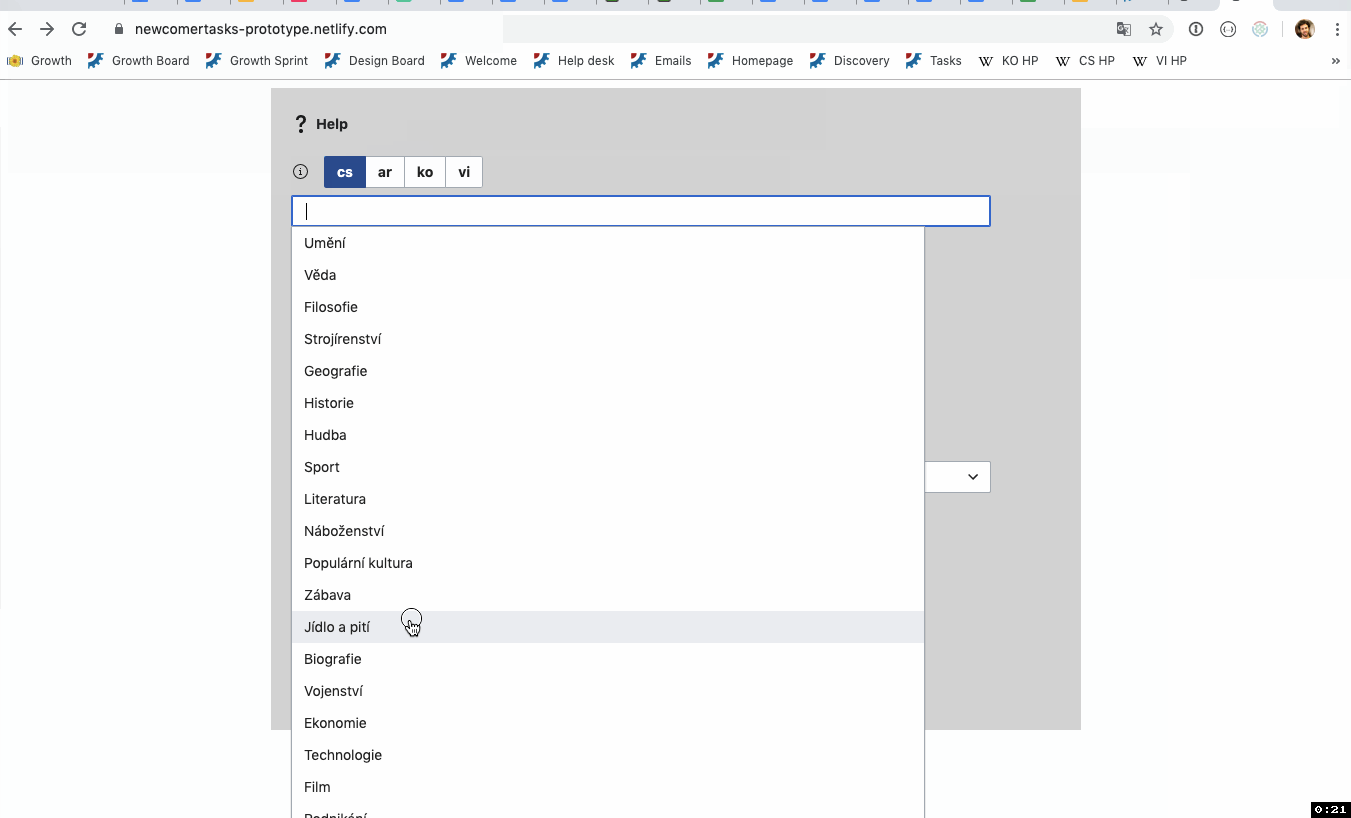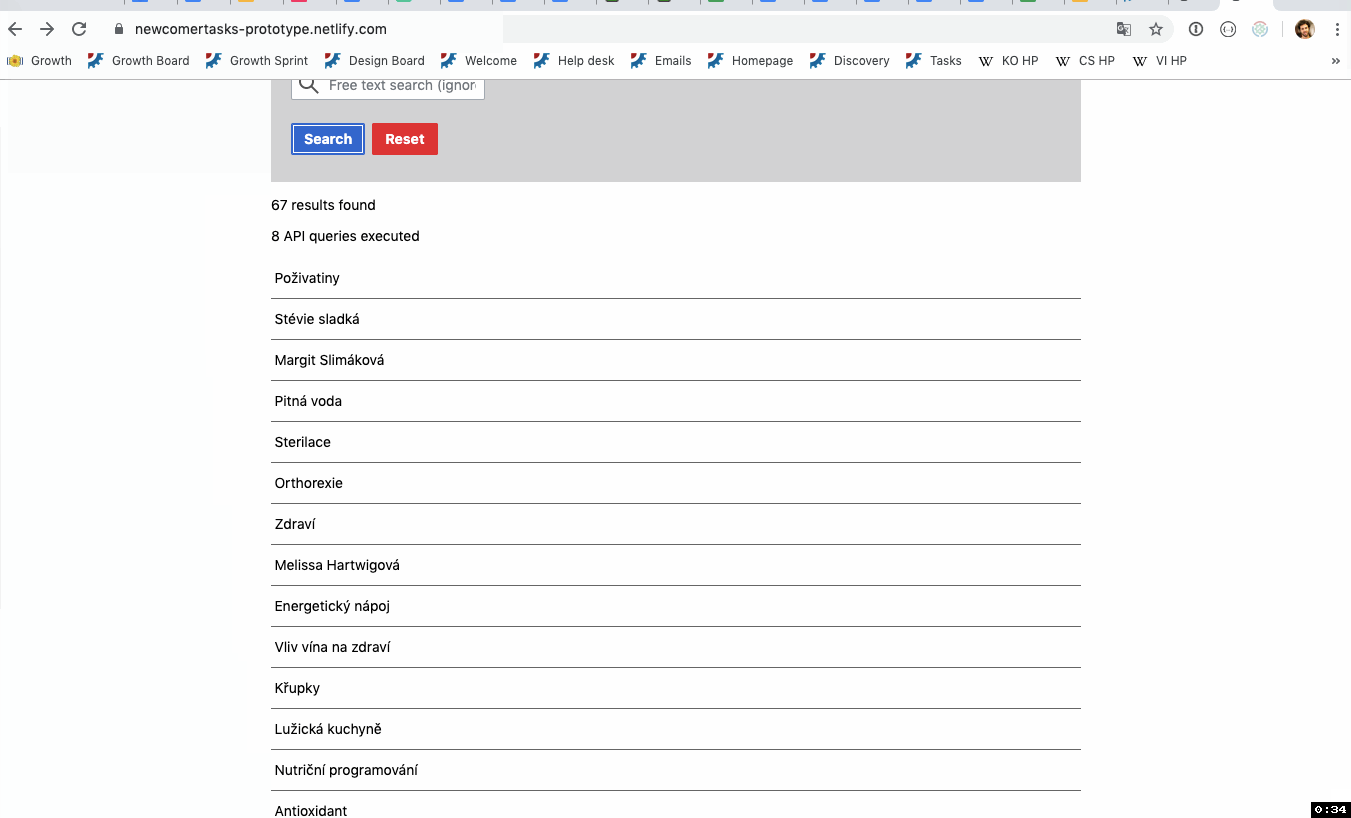
We've decided to draw tasks from maintenance templates. Via T229430, our ambassadors have gathered the lists of maintenance templates that our target wikis use into this workbook. The tabs called "cswiki MM", "arwiki MM", and "kowiki MM" indicate via the "Task type" column which specific templates map to which task type. Some of the task types only exist in one wiki -- that is okay for the purposes of this prototyping. Templates that have no value in the "Task type" column are not part of this.
Topic matching
Our conversations have identified several possible approaches to narrow the recommended tasks to a user's topics of interest. The list below may not contain everything we've discussed, or the explanations may be wrong, so this prototyping can pursue whatever options look promising.
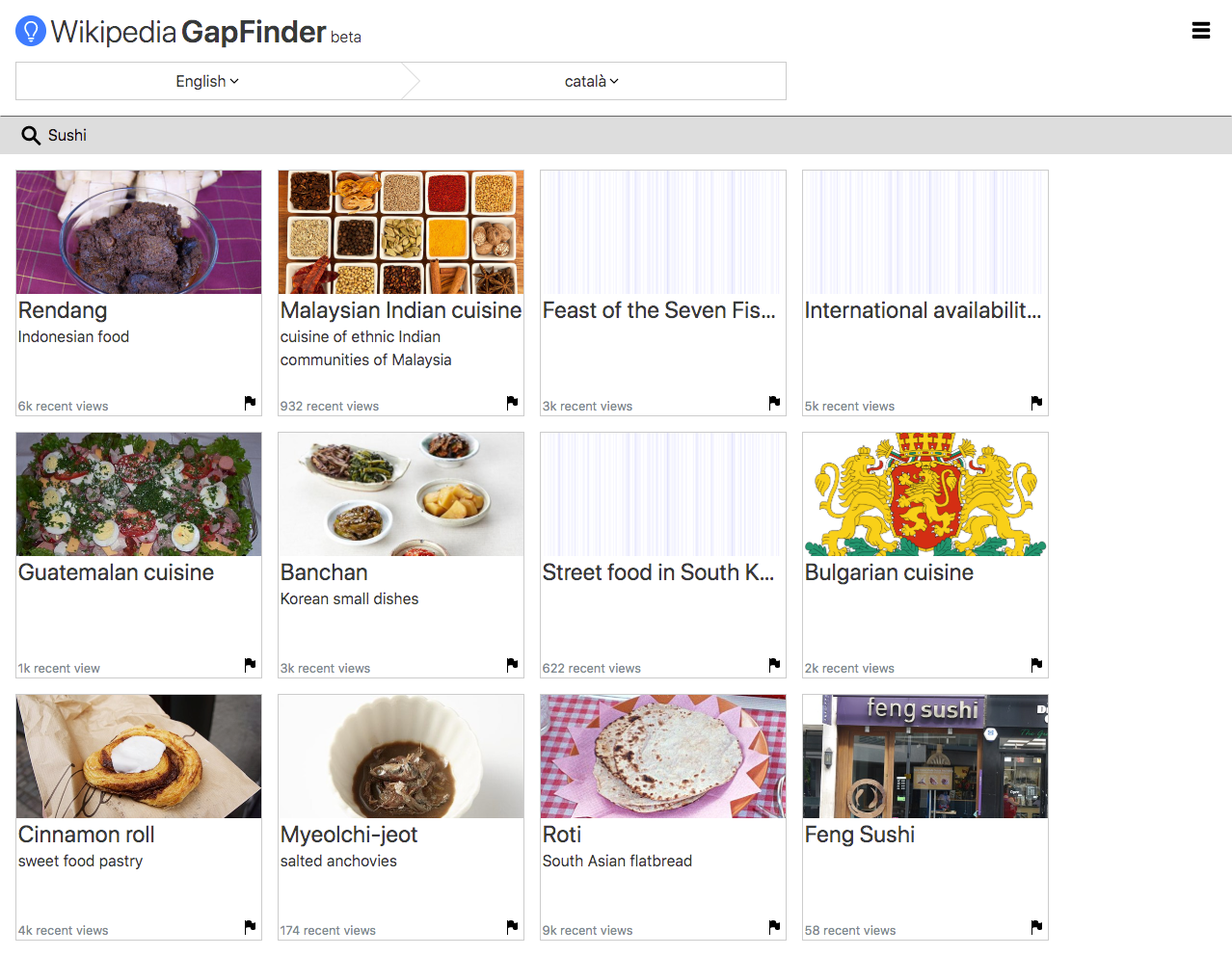
- User selects high level topics from a list (e.g. "Art", "Music", "History"). Each of those topics has a hard-coded list of archetypical articles associated with them (e.g. "Music" may have "Orchestra", "Rock and roll", "Hip hop", "Beethoven", "Drum"), and a "More Like" algorithm is used to find similar articles. This method can draw on the topics currently being used in Question 3 of the welcome survey in each of our target wikis. The hard-coded seed lists could come from "vital articles lists" and use Wikidata to translate that set across languages.
- User enters some topics of interest into a free text field (e.g. "Skateboarding superstars") that brings up results from article search (e.g. "Skateboarding"). The user selects some resulting article, and then we use the "More Like" algorithm to find similar articles.
- User can type in a free text field or select from a list to choose amongst the categories available on the articles that have maintenance templates. To effectively use categories, this approach might need to crawl up or down the category tree. It's common that the category actually on an article is much more specific than something a user would type in (e.g. "16th century Dutch painters"), but higher up in the tree is a category they would type (e.g. "Painting").
Outputs
These are some of the desired outputs from this task (other useful outputs are welcome):
- Some lists of topic inputs and resulting recommendations for each target wiki. In other words, what articles do we get if the user selects these topic options, or enters this free text?
- Those same lists when narrowed to different task type groupings, along with counts of how many results there are.
We'll then get help from our ambassadors to determine if the outputs look like useful and relevant recommendations for newcomers.