Error message
WMFTimeoutException: the execution time limit of 60 seconds was exceeded from /srv/mediawiki/wmf-config/set-time-limit.php:39
trace
#0 /srv/mediawiki/php-1.35.0-wmf.15/includes/diff/TextSlotDiffRenderer.php(214): {closure}(integer)
#1 /srv/mediawiki/php-1.35.0-wmf.15/includes/diff/TextSlotDiffRenderer.php(140): TextSlotDiffRenderer->getTextDiffInternal(string, string)
#2 /srv/mediawiki/php-1.35.0-wmf.15/includes/poolcounter/PoolCounterWorkViaCallback.php(69): TextSlotDiffRenderer->{closure}()
#3 /srv/mediawiki/php-1.35.0-wmf.15/includes/poolcounter/PoolCounterWork.php(125): PoolCounterWorkViaCallback->doWork()
#4 /srv/mediawiki/php-1.35.0-wmf.15/includes/diff/TextSlotDiffRenderer.php(173): PoolCounterWork->execute()
#5 /srv/mediawiki/php-1.35.0-wmf.15/includes/diff/TextSlotDiffRenderer.php(124): TextSlotDiffRenderer->getTextDiff(string, string)
#6 /srv/mediawiki/php-1.35.0-wmf.15/includes/diff/DifferenceEngine.php(1137): TextSlotDiffRenderer->getDiff(WikitextContent, WikitextContent)
#7 /srv/mediawiki/php-1.35.0-wmf.15/includes/api/ApiComparePages.php(175): DifferenceEngine->getDiffBody()
#8 /srv/mediawiki/php-1.35.0-wmf.15/includes/api/ApiMain.php(1603): ApiComparePages->execute()
#9 /srv/mediawiki/php-1.35.0-wmf.15/includes/api/ApiMain.php(539): ApiMain->executeAction()
#10 /srv/mediawiki/php-1.35.0-wmf.15/includes/api/ApiMain.php(510): ApiMain->executeActionWithErrorHandling()
#11 /srv/mediawiki/php-1.35.0-wmf.15/api.php(78): ApiMain->execute()
#12 /srv/mediawiki/w/api.php(3): require(string)
#13 {main}Impact
Raised error levels for MediaWiki in production as a whole.
User gets fatal error without a way forward.
Notes
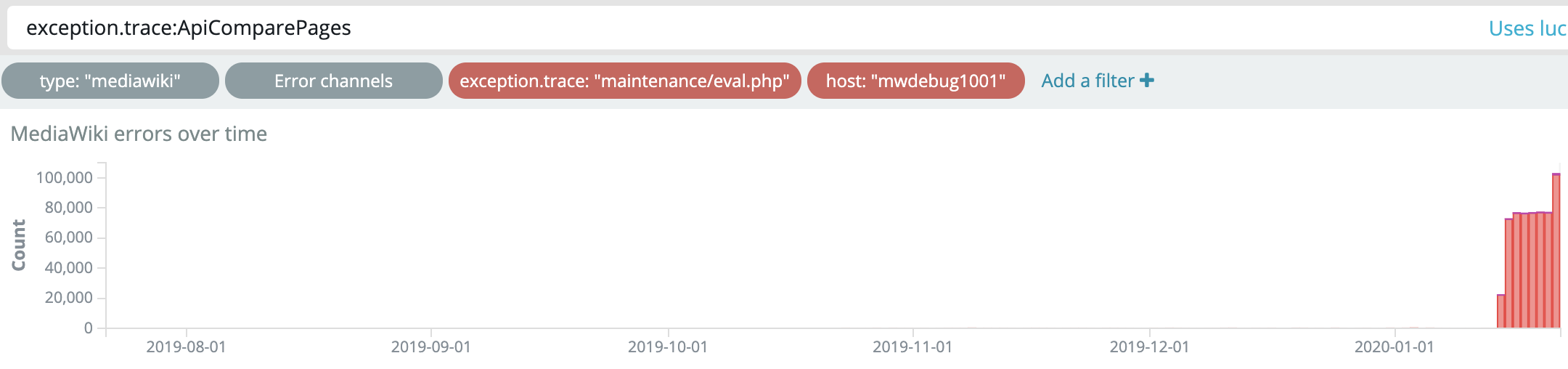
This started 15 Jan 2020 and has a frequently of 80,000 to 100,000 crashes per day, which makes it the most frequent error in production right now by several order of magnitudes.
From https://logstash.wikimedia.org/app/kibana#/dashboard/mediawiki-errors.