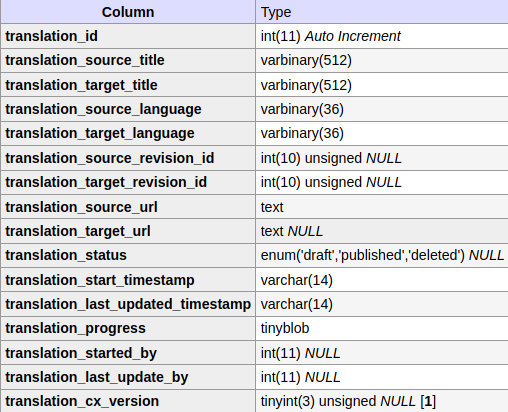
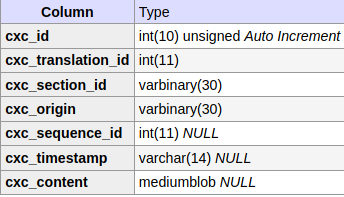
When an article is published with Content Translation, contents are also publicly exposed as part of the parallel corpora. In this way, anyone can use APIs or data dumps to get information about the translated paragraphs (original content, initial MT, user modifications, etc.)
We want sections published with SectionTranslation to also contribute to this useful data resource.
Metadata changes
As part of the work in this ticket we need to define any changes in the metadata to distinguish section translation from article translation, an how they impact external services using the data (e.g., Opus project). In particular, the current data schema assumes there will be IDs for the translation and the translator for each translation. This does not align with the current support for Section Translation where translations are not persisted yet and anonymous translation may be supported in the future.
QA Notes
This ticket does not result in many visible changes to the user, we may want to verify that:
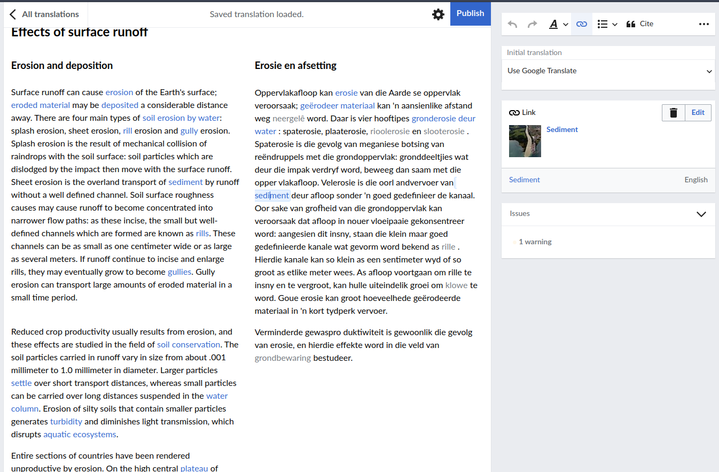
- The usual publishing process is not broken. Making some translations and verifying that they could be published without issues.
- Data is available in the corpora. By inspecting the database, check that information for the previous translations was added to the corpora.
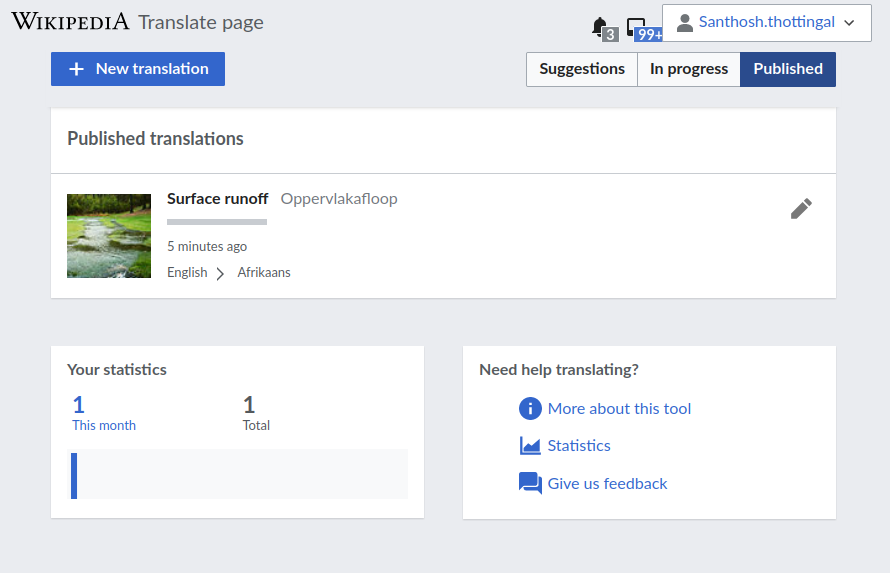
- Published translations with Section Translation should become visible in the "Published" view of Content Translation for the same user.