The drop looks too good to be true. Did we break the pipeline or change how we log errors?
https://grafana.wikimedia.org/d/000000566/overview?orgId=1&viewPanel=16
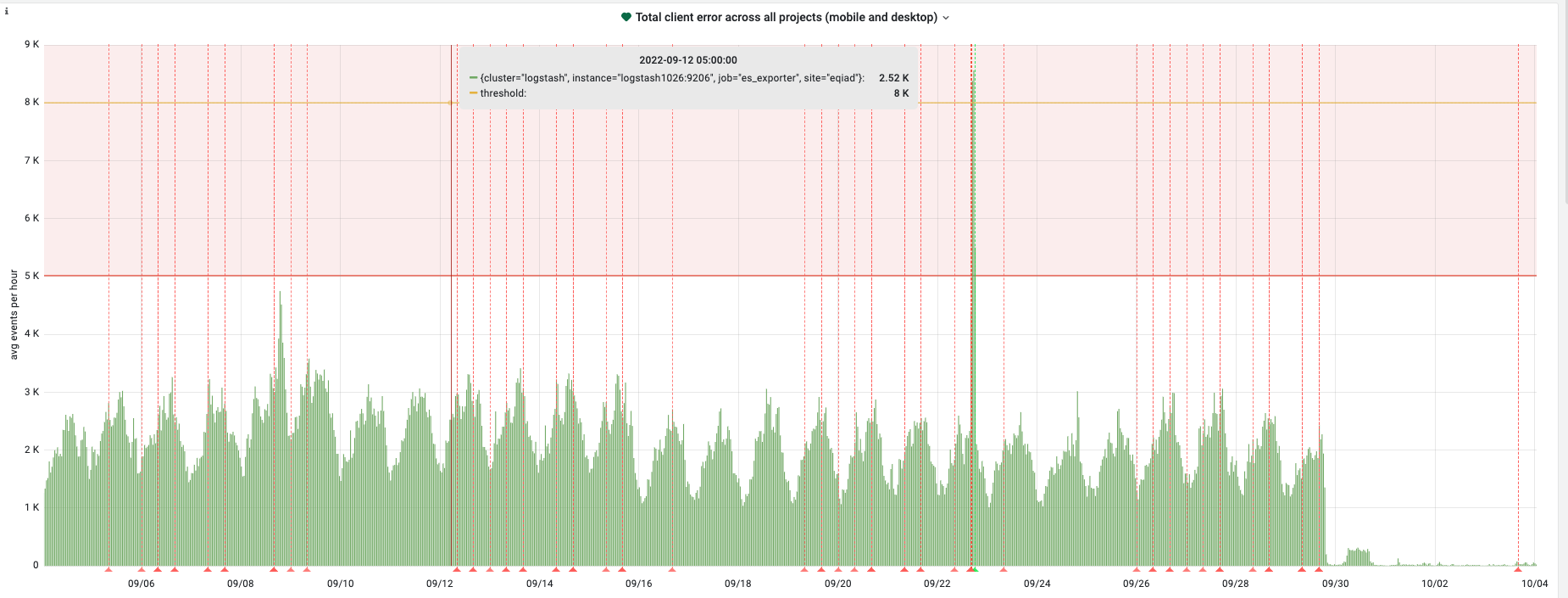
Marking as UBN until we can confirm what happened here.
Last 24hrs only 557 errors were logged.
Last week before the deploy we were averaging 50,000 errors a day.